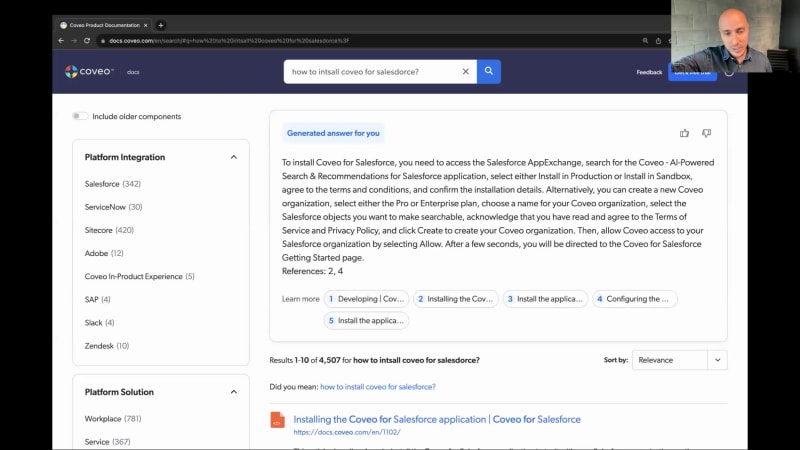
Hello, everyone. Thank you so much for joining our webinar today. Go beyond the hype enterprise ready GenAI for industry leaders. My name is Bonnie Chase, and I lead the product marketing team for Covayo's service line of business, and I'll be your moderator today. I'm joined today by our director of R and D, Vincent Bernard. I have a couple of housekeeping items to cover quickly before we get started. First, everyone is in listen only mode. However, we do want to hear from you during today's presentation, and we'll be answering questions at the end of the session. So please feel free to send those along using the Q and A portion at the bottom of your screen. Today's webinar is being recorded, and you'll receive the presentation within twenty four hours of after the conclusion of the events. And because we're cutting through the hype and showing you some real products today, I would like to draw your attention to our forward looking statements I won't read this out loud but feel free to read at your leisure when you receive the recording. So today's agenda is simple. In the next thirty minutes, I'll give you a quick overview of Coveo and how generative AI continues to shift customer expectations. Then Vincent will introduce you to the new Coveo relevance generative answering solution with a live demo. Then we'll take questions at the end, so get those fingers ready. Now for those of you who may not be familiar with us, Kovea has been building enterprise ready AI for over ten years. And ultimately, our goal is to really democratize AI so that any enterprise can take advantage of AI capabilities for search recommendations, and one to one personalization. Now we do this across three lines of business, commerce, service, and platform that you can deliver those personalized, relevant, and profitable experiences across the entire customer journey. And the strategy we pursue, of course, is last to hype first to results. So we've been working really hard build a generative answering solution that meets your business needs and your customer expectations. And over the years, we've seen how large tech disruptors like Netflix, Amazon, Spotify, have shifted customer expectations and really redefine the way businesses interact with people. The launch of OpenAI's chat GPT is no exception. From large enterprise companies all the way down to, you know, our family members everyone is getting their hands on GPT. Genative AI is an experienced game changer driven by quantum leaps in large language models, which is driving the need for enterprises to move quickly to start leveraging this technology so that they can deliver on these expectations and not get left behind. And we know that these expectations have changed for good. These are really aligned around delivering unique individualized journeys experiences that are prescriptive and intent driven and journeys that are coherent and don't off don't differ depending on where you search for an answer. So when thinking about leveraging generative AI, it's important to remember that this is something that should be seamlessly threaded into your digital experience, not bolted on the side. And we've gotten this question a lot, you know, is is genai the new search? Well, the truth is search is not going away The worlds of intelligent search, recommendations, and generative chats all converge into a new more modern digital experience paradigm. And by combining large language models with mature and reliable AI search and relevance capabilities is imperative to create those generative experience is that enterprises and their customers can trust. Now as I mentioned, we've been building AI for over a decade, and this is really the latest step that is part of the not evolution of our AI journey. So again, not something to think about as a separate silo or as a bolt on. We're very excited about what the future holds with this new technology and we wanna help your customers solve key challenges found with platforms such as chat GPT. So we've talked to CIOs around the world and really identified nine headaches that we need to take into consideration as we as we think through generative AI. You can see, you know, the first group here is really around the security and privacy of the generative platform as well as generative content. You want to make sure that you're only giving people access to answers that they should be allowed to see that they're entitled to see. You don't want your data being shared to the public, and you want to make sure that you have will access to multiple content sources so that you're really providing more relevant and factual information. Currency of content is key making sure that, you know, if you have new content, new articles, that that content is being considered as part of that generated answer, you don't want outdated answers. Of course, factuality, veracity at scale, we've heard a lot about hallucinations and some of the falsehoods that Chad GPT can produce, for example, coherence of search and chat channels. Again, we don't want another silo. We want things to flow together seamlessly. Sources of truth and verifiability. We wanna make sure that your generative answer is not only are truthful, but are verifiable. So you can really see the sources of information. And then of course the high costs of generative AI, you know, it's a lot to build into a platform, and so we wanna some of that for you. So, you know, I've covered the nine headaches and and what I'd like to do now is hand it over to Vincent so we can really talk through you know, how we're how we're approaching the solution for generative answering? Thanks, Bonnie. I'm super excited to be here today, and explain a little bit it happened in R and D? How do we build it? What do we saw in the market? And you're gonna, I kinda walk you through how, we build a feature. Then we're gonna do a cool demo. And at the end, like we said in the beginning, we're gonna answer to all of your questions. So, Kavio, relevance, generative answering. First, I'm gonna introduce what we saw on the market and the different things, that we realize. So with that tsunami, created by GPT, or more specifically chat Jibiki. We realize even in our current implementation that the behavior of the end user change a little bit, it it shifts toward more complex queries and natural language queries. So instead of going with classic keyword search, We see an evolution in the behavior of the clients. First, those are little examples here that we see in the service in this where instead of asking for bank account Canada, we're gonna have more complex questions such as how to add a bank account to feed in Canada or hear my robots not following the path, the find on the map, this woman talking, about a roomba, or here explain the difference between atomic and a headless. Those are, use cases we see at Cavell quite a few times. So this is an example of queries in service same thing in commerce. We're gonna have a more demand for what we call a digital assistant, instead of asking for, and and using filters and simple queries, we're gonna see longer queries, people that are asking advice to the systems. You realize that the classic search experience is not very, it's not well tuned, I'd say, to respond to these kinds of answers. So we need to be careful when we're we're getting these requests to to find the right solution, technologically, to answer them. Same thing in workplace. We see, more and more complex, quick questions. This is a video example. Where we have questions that are fully fledged in English, very complex questions that requires specific technology. So people have expectation what we see on the market, so GPT has an influence, how do we respond to that? So before doing the demo and showing you our response, I want to make two different distinctions here. The first one, what is AI power surge? So Kaveo has been in that industry for quite a long time now. A good search engine will have these different features. So we're gonna have what we call query suggestion. Which is that pipe ahead experience you have when you're using Google, for instance. These suggestions are predictive. So on what you're doing, they're gonna modulate themselves. And then on the right side, you see these fully fledged search interfaces that have, keyword search good relevance navigation that will merge multiple sources of content. So this is good. Obviously, it's not there to to to fade away. But we see with the evolution of the keywords I was in the queries I was expecting. I was talking about just earlier. We see a new type of vendor face coming on the market. And this is not a surprise for you. Those are the new things we see. So people have a larger box with an input box that is a little bit wider where we are, ins we're we're invited to ask more complex questions. And then we're gonna have a fully redacted bonds. So that LMM answer is usually more vocal, more verbose. It's gonna be, more precise and more prescriptive mostly. So cool. We have classic search. We have new LLM and question answering, but what do we do as a company to, expose these to our end user? So you're gonna have your search page, which is the classic thing you have right now. If you're a bank, you're gonna have a a a kind of a self service portal where people go to ask question and you're you're trying to deflect these so they they they don't reach your support center. So that's the kind of classic experience you have. With Kavil, you're gonna have a UI. You're gonna have the index. I mean, I have all the analytics and machine learning in three stack, feature here. On the right side, you're gonna see what we call question answering. So this is a new tech. This is what you're interested in. We're talking here about large language model. We're talking about embeddings and vector databases to store the content that has been extracted from your knowledge base. So cool new technologies, quite easy to put in place, to be honest. That's not the challenge. The challenge we see is, the duplication of the endpoints. So right now you have search, you have question answering, and it causes quite a few headaches. First off, you have two entry points. So how can a user understand should I use question answering or should I use instead the classic search? Then we're gonna have also duplication of infrastructure term. If you're trying to build what's on the right side, you'll see costs will come up quite fast So we're talking about, having these Victor databases up and running scale, make them reliable and redundant, having all these models ready to serve So instead of you're gonna have a a bill for your search stack and also another bill for your question answering stack So different set of fact, different set of content, duplication of technology. This is not, obviously, optimal for a large corporation or any kind of enterprise out there. What we're coming up with is this merge between these two different, I'd say entities. So here, we're gonna have a unified way to search and ask question. The goal here is to avoid duplication of content and respect, actually, all the goodies you have with the good search engine. We're talking here about always fresh content that is ready to be served and ready to be used to generate answers, security. So if you are in a logged in portal or in an intranet, you don't want the engine to recommend or speak about things you're not entitled to see. This is really important. It has been cavaille bread and butter for years, so we're able to merge these technologies together. On the right side, you're gonna see by analytics, administration, obviously, in a single tool, but then also unified search box for all your queries, having generated answer based on the most relevant things in your company and then personalization. So everything Kavil was offering and more because we're, in fact, bolting on top of our stack, those new question answering capabilities. So I know, it's, it's theoretical right now. So let's jump in a demo. You I'll show you how it works. So if I share my screen here, continue let me show you here. This is Kaville documentation. So, I'll use it as an example because we, drink our own Chanbang. So the first client that was introduced to feature is Kavil. We tested it on our our own documentation website. So docs dot kaville dot com is a Kaville search interface. This is the classic experience Kaville will usually deliver. So you're gonna have search results. You're gonna have query suggestion. As I was explaining, you're gonna have the most relevant or latest results here and a bunch of different facets, to navigate. So the main thing, and we'll start simple, and then we'll go more and more complex as we iterate through the example. The first example I'll write here is how does Kaville determine relevance? Quite a simple query, but it's not a keyword search. Query. It's a question. So if you start asking, you'll see that the first difference between, this, instance and the classic search is the widget at the top. This is our ML generated answer. How does it work? Quite simply, we take the best results at the bottom here and we're able to extract from these results, the right snippets, and then we send it to a large language model that is able to formulate the right answer, and it's coming back. You can see here that this has been generated for me. You can see in an easy to understand language, the solution, and then also all the different citations at the bottom that are pointing to the real part of the product that we, we encountered and we use to generate this sensor. It's pretty sweet. You can see also that it is blazing fast, which is something we're pretty proud of And like I said, it's gonna respect all your security, documents. It's always gonna be up to date. So let's now jump to something a little bit more complex. My second example, how to install Kavio for sale doors. So, I wanna showcase here the semantic search capability is behind the scene. Making a generative answering a feature requires quite a bit of thinking. It's not just keyword search. We need to have better recall to get more snippets. So we installed behind the scene what we call embeddings and semantic search, and this will let us actually go through these typos and give you the right answer. So if you look here, install Covir for Salesforce, our classic engine produced a did you mean, feature here which was how we were handling that before. But here, what's different is the generated answer, and even the results at the bottom are able to go through these typos and and read and understand the meaning even if it's wrongly typed so that aggressive mechanism to go through typos and misspelling, truly useful for mobile devices when people are having a little bit of a hard time to type. It is one of the big benefit we, we noticed when we started to use that Let's continue with another query. What are the best practices for configuring Caveo query pipelines? In the CAVA ecosystem, the query pipeline is a place where you go to end to to configure your search interface. So if you're asking best practices, kinda go through and obviously find, the document best practices, but it's also gonna find a little bit further such as routing and conditions, and then the query pipeline mechanism rules and the the query pipeline optimization. So this example, I like it because it's able to get documents from a variety of sources, merge them, and then give you a coherent answer in a few seconds. Let's continue here with another example here. We'll go with, again, the query pipeline since we're in that topic, but I'll go a little bit deeper. My query here is explain in details in bullet points. So I'm gonna ask some more specific instructions. So here, you'll see the answer within another formatting. When you ask in details or when you ask in bullet point, you will influence the output of the Kavil generated answering feature. So here we're gonna have something more detail, more verbose. That's gonna give you a little bit more meat around the bone. You know? So it's it's it's a little bit better depending on what you're looking for. You can ask for a synthesized answer. Or you can look for something that is a little bit, more complete. Then, let's continue here with one of my favorite example, you may have noticed. I have a slightly, accent. I'm a French Canadian. And what we realize with that feature, again, is it's able to proceed, to and and this one is mind blowing in my opinion. It's able to search and respond in different languages. So here you can see I've asked a question in French. I am able to retrieve the right documents So you see that comma function inquiry pipeline. It's how to how does the query pipeline work. You see that the first results are actually ware pipeline, the glossary, how to manage it, and then it's able to retrieve the right document and reformulate the answer and give it it, in my own language. This is crazy because there is no translation. There is no article in French in the Caville documentation that talks about it. So this unlocks a lot of possibilities such as just having, people to interrogate your, your documentation in different languages. Let's continue with another cool one, a little bit more complex compare feature by feature, the sitemap and the web connector. Here, I'm asking, something a little bit complex. So there is two different features. The sitemap connector and the web connector. And I'm asking feature by feature. Can you list me the difference between both of them? And you see here it it it found that in the documentation that indexing speed, content coverage, and prerequisites are all three things you can compare those features. And depending, on what you're looking for, you can select the right technology. An interesting part here as well is you see we are pulling the documents from the knowledge in Salesforce, but also from the documentation and the glossary So we're merging information from a variety of sources within Eureka system. We're taking that back, and then we're able to generate a pretty sweet feature. I'm almost done with my example. The next one, describe every ML model and their usage, I quite like this one too. This one is another instruction. So I I've shown you compare describe is, similar, but it's just like list me everything. So here, you're gonna see all the different Kaville machine learning models, as soon as we have the documentation up and ready for this new feature and presenting today, you're gonna see it being added on top of it. This portal doesn't let me be logged in. So, soon gonna implement it on our community, you're gonna be able to see if I'm logged in. I'm gonna have additional response. If I'm not, it's not gonna show. But this feature of being able to show logged in or specific content for a single user is something we're very proud of as well. So that being said, let's continue, the slide deck enough examples here. A few things, that I wanna highlight, we have very cool thing coming soon. So first off, you see here in this design, there are inline citations. So in my example, I've shown you citations at the bottom. Those are global citations from the whole answer. We wanna be more descriptive and be able to pinpoint directly in the response which document was used to produce this. So we think it's a very valuable question and the in line citation will be, added in the product very, very soon. The other features we're coming with is follow ups and conversation. So cool. You gave me a good answer of what is a query pipeline, but then when should I create one, or can I have more than one query pipeline, or what's the best use? Those are all follow ups and conversation type questions that we wanna have as well. It's coming in the product very, very soon. Then we're also extending these capabilities to our, different line of businesses. So this is an example of a commerce interface, barca sports, And you can see here what are the best panel boards for a beginner. This created a lot of things. So first off, we went in the category selection and we selected a category for your product, and we also selected a level of difficulty like beginner, to give you, like, a scoped version of the products that matches that complex query we've got. Final thoughts before jumping on the question, we think that we can bring these very, very cool feature at low costs, because Kaville is And that's the classic story of Kavil. You wanna fight against Amazon or against GPT or Microsoft. We can help you bring the these technologies to your, to your environment at a lower cost because we're developing it for all of you. Instead of you developing it for yourself, and having to maintain all these different infrastructure and costs. Also, we want to open choices for LMSs So right now, we're leveraging open AI models. We want to make this as generic as possible so you can select multiple large language models. Depending on your preferences. We wanna make sure that we are adapted to different domains. So if you're in the DIY industry or if in the high-tech industry or in the banking industry, we wanna make sure we have adapted models, language models that will represent all the concepts that we need to to to tolerate in these different concepts. Open sources, we are making sure that the technology we use or technology g, we build our shareable across the community, and then we want to be LLM agnostic as much as possible. It's all about relevance, you know, So we wanna make sure these features that I've presented today on a website are also available through Salesforce in an agent panel or on a chatbot or on a commerce web app or anywhere you're using conveyor. So these features are use case agnostic wanna make sure you can leverage them all over the place. So now time for the q and a, Bonnie back to you. Do we have any questions out there? Thanks, Vincent. Yes. We've got a few questions here. Plus a comment from Scott. Thank you for that comment, Scott. So let's just jump to Scott's first question, which is Vincent, you mentioned results in seconds. But I have a feeling performance is faster than that. Can you comment on speed? Yeah. For now, and it's we're we're very proud of it, to be honest. So the way that works behind this seen is we do a semantic search. We get all these snippets and we send it to the generative engines. So we ask, we send your prompt what is a query pipeline. We send all the right snippets, and we ask it to to make a good answer out of that. And this is how we achieve speak because we're using the large language model, not for retrieval purposes, but because he's charming and he speaks well, so that's why we love these engines because they're really well articulated, and we don't ask them to retrieve content. And this is how we're able to achieve quite phenomenal speed in my opinion. Great. A follow-up question here, from Scott. Can you comment on the personalization signals captured using this new search capability and their use in the customer journey? Yeah. Of course. The way it works with Cavea is if you go on the Cavea website and you're only looking at Kavail for Salesforce. You're a Salesforce guy. That's your jam. You only checked Kavail for Salesforce documentation. If you ask a generic query, like, how do I track page views? Since you have such a strong Salesforce vibe, The results in the classic of your experience will be tinted Salesforce. And then since we use those results to put it in the generation engine, your and your your response will be Salesforce Focusizing. So the the good personalization engine that Kaville was already is bringing personalization to these answers. And that's how we we don't need to build that additional feature. It's already a part of our stack. So it's not just generated answer. It's personalized generated answer, depending on what you've done in your session out there. Awesome. Alright. So so we shared the generative answering in the COVID docs site. There's a question about location. So will these these features be available in all locations such as, you know, Salesforce knowledge panel, are in product experience, you know, will this be available in all those areas? Yes. Technically, if you and I I I think that, you know, could be up really well. So those are two machine learning models, the semantic search module, and the generative, model, you add these models in your query pipeline, and voila, you just need to be updated on your atomic or IPX or whatever the product you're using. Make sure these are up to date. Tweak your pipeline and then voila, you should have these as answers directly in there. K. Perfect. And there's there's a similar question here, which is will RGA be supported in the JS UI framework and IPX is there a preferred UI framework? As of now, we built the streaming component, you know, that that that component that stream the answers, we only build it for atomic and headless. It's gonna follow in chronic and Salesforce. It is not right now in GSUI and we're asking people to migrate, to atomic or quantity, but I don't want to jinx it, but we suspect we're gonna be virtual compatible because behind the scene, it's just a response in the search API. So we can we can boost It's simply a matter of bandwidth right now. We went with the latest and greatest. But, yeah, I don't wanna say yes, but I don't wanna say no. Okay, make sense. Alright. Let's see. What's the ETA for the features that you presented today? Can you share that information? Again, so general availability early twenty twenty four, we are already in beta and roll out with a specific limited set clients where we're testing the feature at scale with them, making sure they like it. But then the general availability is early twenty twenty four. You gonna see if you experience here and they're leveraging the feature before that. Like I said, we have bit of clients and programs, but the real go live is twenty twenty four. Hey. Let's see here. We still have a few more questions. This question's from Matthew. How do you recognize and catalog, AI answers, and responses, which are not completely accurate or could be improved. And how do you rectify this for future queries? That's a very good question. The feedback loop as of today uses small thumbs, up thumbs down, on the UI. So if users are not satisfied, they can express themselves. This is usually how we're doing it. Behind the scene, we're also capturing analytics. And if some queries are performing poorly, the system is gonna look at them and make sure they're optimized. So there's an automatic way, and there is also that that thumbs up thumbs down mechanism as well. K. Couple more questions. Do these improvements in generative AI improve how search handles special characters. For example, spreadsheet formula queries So that's a complex one. I'd say yes, and I'll take Barbara's question at, at the same time. So if you've experienced Kavail before with Smart snippets to realize that it's extremely sensitive to, syntax and and how things are are written because it's gonna spit it back exactly the same. This is different. GPT and those new LLMs don't really care about syntax. I mean, they can read through HTML. And even if the format is not perfect, they are generating an answer. So they don't care if the input is dirty because they are producing an output themselves. So it's not just you don't need to clean your input because the model is able to read and respond correctly. However, for formulas and numbers, it's different. So GPT is very good at words English words more specifically, but it's good in every language, but more in English. And it's not very good at numbers. So if you ask, like, make me, what is the latest thing or what's the highest number between two numbers? Sometimes it get confused. People sometimes think that GPT is just do it all machine, but it's purely a language model. So I I'd say you don't need to clean your input. It's gonna respond correctly compared to smart snippet And then, yes, it's able to persist, some special characters, but not everything. It's not a silver bullet. Okay. Great. We we do have a few more questions, but unfortunately, we are out of time for today. We will follow-up with you via email And of course, you'll receive the recording within twenty four hours. Feel free to reach out and connect, and, thank you so much for joining us today. Thank you. Have a good day folks. Bye bye. Bye.

Live GenAI Product Demo - straight from Coveo AI Experts
In just 30 minutes, you'll see..
- A unique feature you can use to fact-check every result with a single click
- The novel way we’ll transform your search box into a “cohesive” GenAI experience
- How our stringent security protocols protect you from data leaks without compromising performance
- Coveo’s Relevance Generative Answering in live product
Make every experience relevant with Coveo


Hey 👋! Any questions? I can have a teammate jump in on chat right now!