
Retrieval augmented generation, or RAG, augments a large language model ’s (or LLM) predictive abilities. It does this by grounding the model with information from external knowledge that is current and contextual.
LLMs like GPT-4 represent a huge advancement in natural language processing abilities. They enable computers to process, understand, and generate human language.
Despite the seemingly human-like capabilities LLMs have brought into our everyday lives, we also know about the limitations and risks. LLMs are prone to hallucinate, provide misinformation, and cannot grow their knowledge outside of their training data. Additionally, they can pose serious security and privacy risks.
This is where a RAG system comes in.
What Is Retrieval Augmented Generation?
Retrieval Augmented Generation is a process that guides artificial intelligence in generating relevant and coherent responses based on a prompt. RAG first appeared in 2020 data science research by Patrick Lewis and a team from Facebook (now Meta).
RAG improves the quality of LLM output by relying on an information retrieval system. Drawing on relevant document chunks or passages from trusted external data sources. (External in that it’s outside what the LLM already “knows”).

By using retrieved passages for a specific query and user, RAG can help produce the most up-to-date, accurate generative response.
Relevant viewing:The Best Retrieval Method for Your RAG & LLM Applications
RAG in the Enterprise
For an enterprise’s AI, RAG provides greater control over the data an LLM uses to generate its responses. This could mean restricting a model’s answers to pull only from an enterprise’s approved company procedures, policies, or product information. Using this approach, enterprises can provide the LLM with greater context for queries and ensure greater accuracy.
RAG particularly suits knowledge intensive tasks that most humans would need an external data source to complete.
Typically, a pre-trained language model responds to a user prompt — or query — based its training data. The model draws from its parametric memory. This is a representation of information that’s already stored internally in its neural network.
With RAG, a pre-trained model now has access to external knowledge that provides the basis for factual and up-to-date information. The retrieval system first identifies and retrieves from external sources the most relevant data based on the user’s query.
RAG as a Service
RAG as a Service refers to a cloud-based offering that combines search capabilities with generative models to provide accurate and contextually relevant responses to user queries. This service leverages an indexing pipeline to organize data and a retrieval system to fetch the most pertinent information based on user input.
Key Features
- Search and Retrieval: RAG as a Service utilizes a search engine to identify relevant documents or data from external sources before generating a response.
- Generative Capabilities: It employs generative models to create responses that are grounded in the retrieved information, ensuring accuracy and relevance.
- Real-Time Updates: The service can access up-to-date information, making it suitable for knowledge-intensive tasks that require current data.
- Security and Control: Access controls are implemented to protect sensitive information, allowing only approved content to be used in generating responses.
Applications
- Enhanced Search Experiences: By integrating RAG, businesses can improve the quality of search results, providing users with precise answers and reducing misinformation.
- Chatbots and Virtual Assistants: RAG can enrich interactions by enabling chatbots to deliver context-aware responses, enhancing user engagement.
RAG as a Service is particularly beneficial for enterprises looking to improve their customer service and information retrieval processes while maintaining data security and accuracy.
Learn more about Coveo’s managed RAG as a Service offering.
Techniques That Support RAG
Word embeddings, vector search, other ML models, and search techniques assist in finding the most relevant information for the user’s query in the current user’s context. In an enterprise setting, external sources may be knowledge bases with documents on specific products or procedures or an internal website for employees such as an intranet.
When a user submits a question, RAG builds on the prompt using relevant text chunks from external sources that contain recent knowledge. The “augmented” prompt can also include instructions — or guardrails — for the model. These guardrails might include: don’t make up answers (hallucinate), or, limit responses to only the information found in the approved trusted sources. Adding contextual information to the prompt means the LLM can generate responses to the user that are accurate and relevant.
Next, the model uses the retrieved information to generate the best answer to the user’s query through human-like text. In the generated response, the LLM can provide source citations in order to give the user the ability to verify and check for accuracy, because the LLM is “grounded” with the identifiable retrieved information from the retrieval system.
Why Do Enterprises Need Retrieval Augmented Generation?
The need to overcome limitations in GenAI applications has led to an explosion of interest in knowledge retrieval systems.
In our work with enterprise customers, we’ve repeatedly run into the following issues with pre-trained language models:
- Difficulty in extending knowledge
- Outdated information
- Lack of sources
- Tendency to hallucinate
- Risk of leaking private, sensitive data
RAG attempts to address these challenges when working with language models. Let’s next look at how RAG accomplishes this.
Relevant reading: Build vs Buy: 5 Generative AI Risks in CX & EX
What Are Different RAG Methods?
The above description of Retrieval Augmented Generation (RAG) is considered a starting point. Coveo takes RAG to the next level by doubling down on the retrieval accuracy to create an advanced application of RAG. It combines multiple techniques, including vector embeddings, semantic search, keyword matching, and more.
First, Coveo converts text to create vector embeddings, building relationships between concepts using an embedding model. This means different passages can be grouped with others that discuss the same topic, improving the retrieval accuracy for a given input query.

Then, the first stage of retrieval at the document level answers the question, what are the most relevant items in the index addressing this query? The retrieval system then fetches the first 100 relevant documents with specific information relevant to the user query.
Then, the second retrieval stage identifies the most relevant passages from those documents, which are then used in the generated response.
Coveo offers retrieval augmented generation in two forms: the full package with our Relevance Generative Answering as part of our industry-leading AI search platform, or via our Passage Retrieval API that makes solely our advanced retrieval accessible to enterprises.
Relevant reading: Putting the ‘R’ in RAG: How Advanced Data Retrieval Turns GenAI Into Enterprise Ready Experiences
Benefits of Using RAG With LLMs
Retrieval augmented generation brings several benefits to enterprises looking to employ generative models while addressing many of the challenges of large language models. They include:
- Up-to-date information. A retrieval-based approach ensures models have access to the most current, reliable facts.
- Control over knowledge sources. RAG also gives enterprises greater control over the knowledge LLMs use to generate their answers. Rather than relying on the vast general knowledge from their training data, you can have LLMs generate responses from vetted external sources.
- Verification of accuracy. Users have insight into the model’s sources to cross-reference and check for accuracy.
- Lower likelihood of hallucinations and privacy violations. Because the LLM is grounded in factual knowledge, accessible by the user, the model does not depend as much on pulling information from its parameters. As a result, there is a lower chance of hallucinations , leaking sensitive data, and misleading information.
- Dynamic knowledge updates. RAG eliminates the need to retrain a model on new data and update its parameters. Instead, the external source is kept up to date so that the retrieval system can search and provide the LLM with current and relevant information to generate responses.
- Cost savings. Without the need to depend on retraining parameters, which can be time-intensive and costly, RAG can potentially lower the computational and financial costs of running LLM-powered chatbots in an enterprise setting.
How Is Retrieval Augmented Generation Different From Fine Tuning LLMs?
RAG and search tuning have emerged as key ways to extend an LLM’s capabilities and knowledge beyond its initial training data. They aim to add domain-specific knowledge to a pre-trained language model, but they differ in the way they introduce and implement new knowledge.
Fine Tuning vs Retrieval Augmented Generation
Fine tuning, which occurs downstream of NLP tasks, takes a pre-trained language model and fine tunes it with additional training data for a particular task. This approach involves adjusting the model’s internal parameters for a specialized body of knowledge, such as industry-specific use cases.
In contrast, RAG combines nonparametric data from secondary knowledge sources through a retrieval mechanism with the model’s existing parametric memory to enhance the pretrained language model’s generated responses.
Which Should You Use For Your LLM?
Whether an organization chooses to fine tune its model or employ RAG depends on what it’s trying to accomplish – and what it’s trying to avoid.
Fine tuning works best when the main goal is to get the language model to perform a specific task, such as an analysis of customer sentiment on certain social media platforms. In these cases, extensive external knowledge or integration with such a knowledge repository are not necessary for success.
However, fine tuning depends on static data, which is not ideal for use cases that rely on data sources that constantly change or need updating. Retraining an LLM like ChatGPT on new data with each update is not feasible from the standpoint of cost, time, and resources.
RAG is the better choice for tasks that are knowledge-intensive and stand to benefit from retrieving up-to-date information from external sources, such as real-time stock data or customer behavior data. These tasks may involve answering open-ended, ambiguous questions or synthesizing complex, detailed information to generate a summary.
Further, there is a security risk associated with fine turning. As you feed the model data – you are potentially exposing private or confidential information. Grounding with RAG helps eliminate this risk.
Note: Coveo Relevance Generative Answering uses its unified search platform to ground content by retrieving relevant content from trusted sources that a user is allowed to see. Access controls protect proprietary and private information. Only approved documents will be fed to the LLM to generate the answer.
Applications of Retrieval Augmented Generation
RAG has the potential to greatly enhance the quality and usability of LLM technologies in the enterprise space. Some of the ways businesses can use RAG include:
- Search: By combining search with a retrieval-based LLM, your search index first retrieves documents that are relevant to your query before responding to the user. The generative model with this approach can provide a high-quality, up-to-date response with citations. This should also significantly reduce instances of hallucinations.
- Chatbots: Incorporating RAG with chatbots can lead to richer, context-aware conversations that engage customers and employees while satisfying their queries.
- Content generation: RAG can help businesses in creating content in areas such as marketing and human resources that are accurate and helpful to target audiences. Writers can gain assistance in retrieving the most relevant documents, research, and reports.
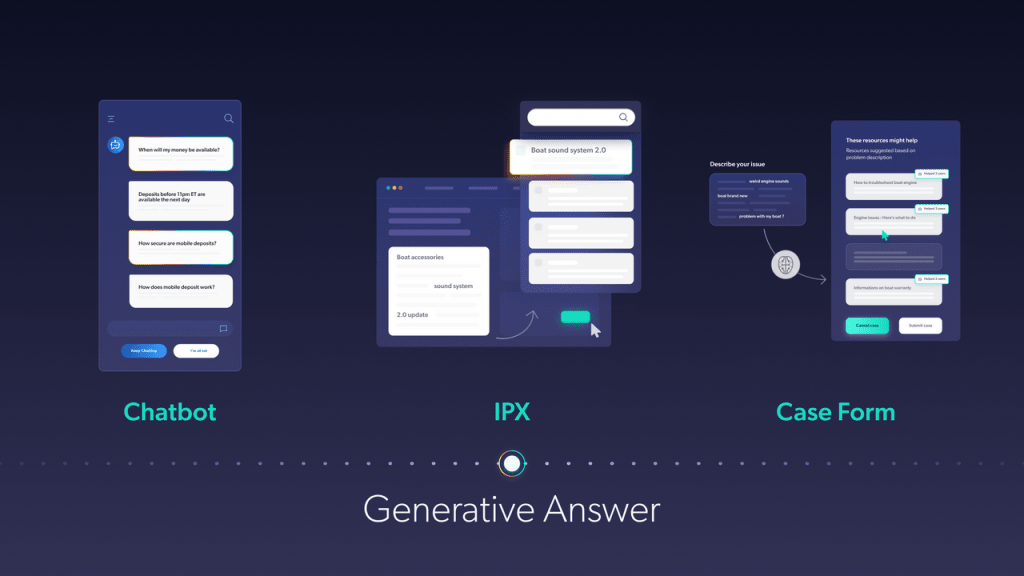
What’s Next with Coveo, RAG and Generative AI
At Coveo, we believe in the exciting opportunities large language models bring to enterprises. We also see the potential in RAG as a key approach to improving human-computer interactions using NLP. Our Coveo Relevance Answering capability takes LLM technologies and combines them with the Coveo Search Platform, a secured AI-powered semantic search retrieval system, to provide what we think is a pretty powerful search experience.
“We anticipate that demand for Generative AI question answering experiences will become ubiquitous in every digital experience. In the enterprise, we believe that search and generative question-answering need to be integrated, coherent, based on current sources of truth with compliance for security and privacy.”
– Laurent Simoneau, President, CTO and Co-Founder of Coveo
Learn more by visiting our Coveo Relevance Generative Answering page!



















