
If you have been researching Natural Language Search or Natural Language Processing (NLP), you may have heard of word2vec.
If not, we have you covered. We’ll dig into what you need to know about a word2vec model to be conversant with the data scientists in your life.
What Is Word2Vec?
Word2Vec is a machine learning technique that has been around since 2013, courtesy of Tomas Mikolov and his data science team at Google. It relies on deep learning to train a computer to learn word embeddings and semantic relationships between words in your language (vocabulary, expressions, context, etc.) using a corpus (content library).
You train Word2Vec using neural networks, which teach the computer to process data the way that human neural networks do in the brain. Those neural networks can be set up using two prevalent models:
Continuous Bag of Words (CBOW)
CBOW uses surrounding context words as input to predict the target word. The context words are encoded using hot vectors, which are averaged to more accurately predict the target word.

Skip-gram
A skip-gram model begins with the target word and predicts the context words that should surround it.

What Are Word Embeddings?
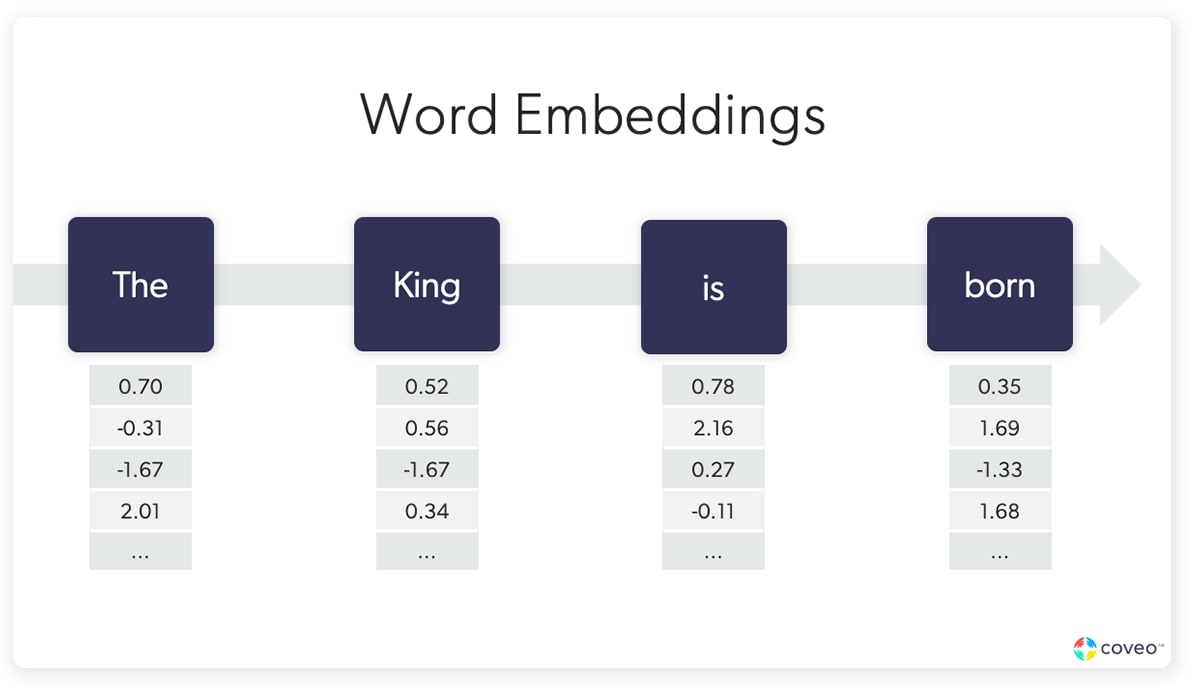
Word embeddings (also known as word vectors) are the vectors that are created to represent words — and their context — or the relationships between individual words. It is the process of converting words into dense vectors — or a series of smaller vectors.

This process assigns values to each word along several different dimensions, creating a dense word vector that isn’t just a string of 0s but actual coordinates in abstract space.
For the word vector geeks out there, sparse vectors are when you have a lot of values in the vector that are zero. A dense vector is when most of the values in the vector are non-zero.
Word2Vec Applications
Let’s not lose track of who word2vec is really for: the end-user. A person performing a knowledge base search, or looking for particular products, cares most about speed and relevance.
Delivering that speed and relevance at scale can quickly become cost- and resource-prohibitive. Word2vec provides a computationally fast (and comparatively cheap) method for delivering baseline word embeddings in a scalable way.
Many organizations still use word2vec for these reasons, as well as the fact that it’s rather straightforward compared to more complex solutions (recurrent neural networks that rely on a graphics processing unit, for example), and can often deliver sufficient — if somewhat less accurate and complete — results.
Common word2vec applications include:
- Improving search relevance by capturing semantic relationships between query terms and content
- Content recommendations and topic discovery based on word embeddings
- Sentiment analysis to quickly determine if customer feedback text is positive or negative
Contemporary alternatives to word2vec:
- GloVe
- FastText
- Transformers such as BERT and GPT
To Understand Word Vectors, Understand How We Learn as Individuals
So you’ve had the brief: word2vec and word embeddings. But before we go any further, let’s take a step back first to consider how we learn as individuals.
Ever have someone come up to you with a question and you have no idea what they are talking about? Chances are they have not given you enough context to understand what they really need. Maybe they are using a unique word to describe the problem, or maybe they are using a single word that changes in meaning based on the context in which it is used.
For example:
“Bowl” has different meanings and its interpretation depends heavily on context. Are we talking about a round dish used for holding food or liquid? A venue for a sporting event? A geographical basin?
We can try and decode what a person wants by asking questions, prompting them to use a similar word or phrase until we can finally winnow down what they want.
Understanding natural language is not a trivial matter. And as humans, we don’t realize how incredibly complicated language is, which is why it is hard to teach computers natural language processing.
Structural Relationships Between Words and Context
Words rarely have meaning in isolation. If I say “leopard print”, I might be referring to the indentation of the animal’s paw on a given surface, or maybe it’s a description of a pattern that replicates a leopard’s skin. Then again, it might be a poster of the magnificent beast itself. It’s the surrounding words that clue us in on the context of the current word or words.
Without any context words, it’s hard to know what a given word means. That’s where a word embedding model comes in. It shows the particular relationship certain words have in relation to others in the same phrase or sentence.
When paired with clothing or accessories, we understand that “leopard print” is describing colors and markings. When paired with sizes like 24 x 36, we understand that it is a poster. When we use it with words like sand or mud, we know that we are tracking the animal.
Semantic Relationships Between Words
Your brain – and the word2vec model – understands the semantic relationship between words.
For instance, it understands that frequent word pairs like “king” and “queen”, “blue” and “yellow”, “running” and “jogging” each have a special relationship. A word pair of “king” and “running,” and “queen” with “yellow” don’t have the same relationship. Our brain also understands that the semantic meaning between “shoes” and “socks” is different from, say, the relationship between “shoes” and “sandals,” or “shoes” and “running.”
Your brain knows that the word “queen” has a certain relationship with the word “England” that it doesn’t have with the word “California,” (unless we are talking about Gen Zs in California talking to each other). The word “toast” has a relationship with the word “French” that it doesn’t have with the word “Spanish.”
Now imagine the area of your brain that contains language as a well-organized storage space. Words like “French” and “toast” would be located closer together in that space than the words “toast” and “Spanish.”
Target Words, Word Vectors, Vector Representation
Finally, every word evokes a set of associations that are partially shared by all speakers of the language and partially a result of your personal experiences/geography/etc.
For example, your associations with the word “milk” might be white, 1%, breakfast, cereal, cow, almond, and if you have experience with dairy allergies, danger, ambulance, or anaphylaxis.
This ability to draw these associations is the result of complex neurological computations honed by our brain’s neural network over thousands of years of evolution.
Does Word2vec Use One Hot Vector Encoding?
No, it makes use of word embeddings because one-hot vector coding has two main limitations:
- Inability to understand ‘obvious’ relationships
- Incompatible with a large corpus
From all the context shared above, you now have a greater appreciation and understanding of the complexity of the human language. You know that it’s not enough to just feed computers the dictionary definition of words as training data and hope for the best.
Yet, NLP had to start somewhere, and this is where it started. Since computers understand only numbers, in order to teach them natural language, we have to represent words numerically. For a long time, it was done by representing each target word as a string of zeros with 1 in a different position for each word. This method is called “one-hot vector encoding.”
A Visual Example
So if you have a vocabulary of four words, they would be represented like this:
This computational linguistics method creates a unique representation for each target word and therefore helps the system easily distinguish “dogs” from “cats” and “play” from “Rome.” But there are two problems with it.
First, this method of word representation has no way of encoding the relationship between words that as humans we take for granted. It has no way of knowing that the word pair DOG and CAT are similar, in a way that DOG and ROME are not. That CAT and PLAY have a special relationship; that CAT and ROME do not.
Second, this vector representation is problematic if you have a very large corpus. What if your vocabulary size is 10,000 words instead of four? This would require very long vectors, with each vector consisting of a long string of zeros. Many machine learning models don’t work well with this type of data. It would make training the data really hard.
Today, both these problems are solved with the help of a modern NLP technique called word embeddings.
Word Embedding Vector Methodology
As an example, lets see how this method would encode the meaning of the following five words:
Aardvark
Black
Cat
Duvet
Zombie
Each word can be assigned a value between 0 and 1 along several different dimensions. For example, “animal”, “fluffiness”, “dangerous”, and “spooky”.
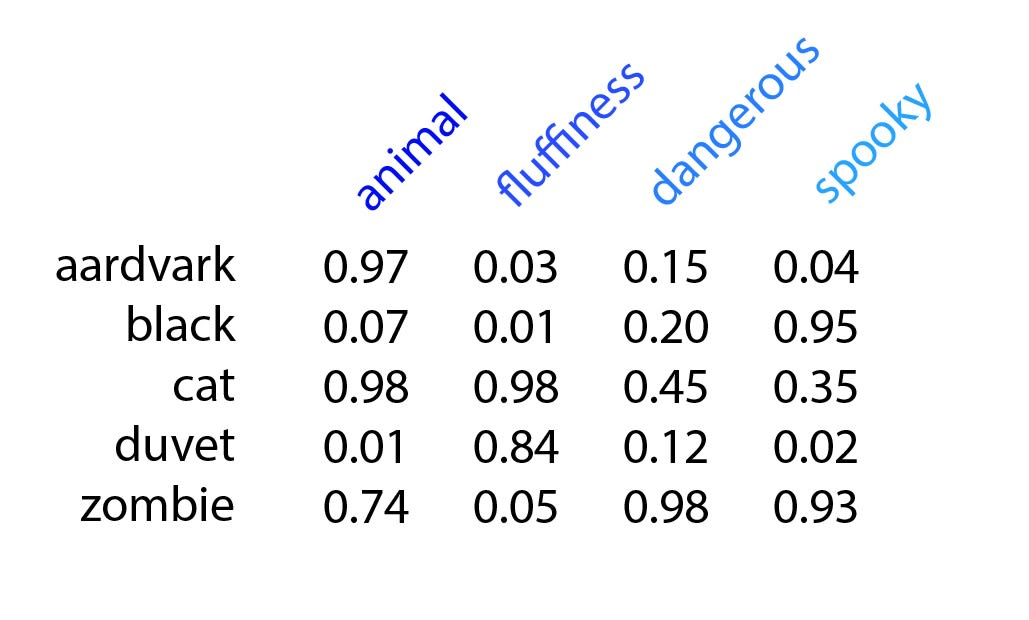
Each semantic feature is a single dimension in an abstract multidimensional semantic space and is represented as its own axis. It is possible to create word vectors using anywhere from 50 to 500 dimensions (or any other number of dimensions really…).
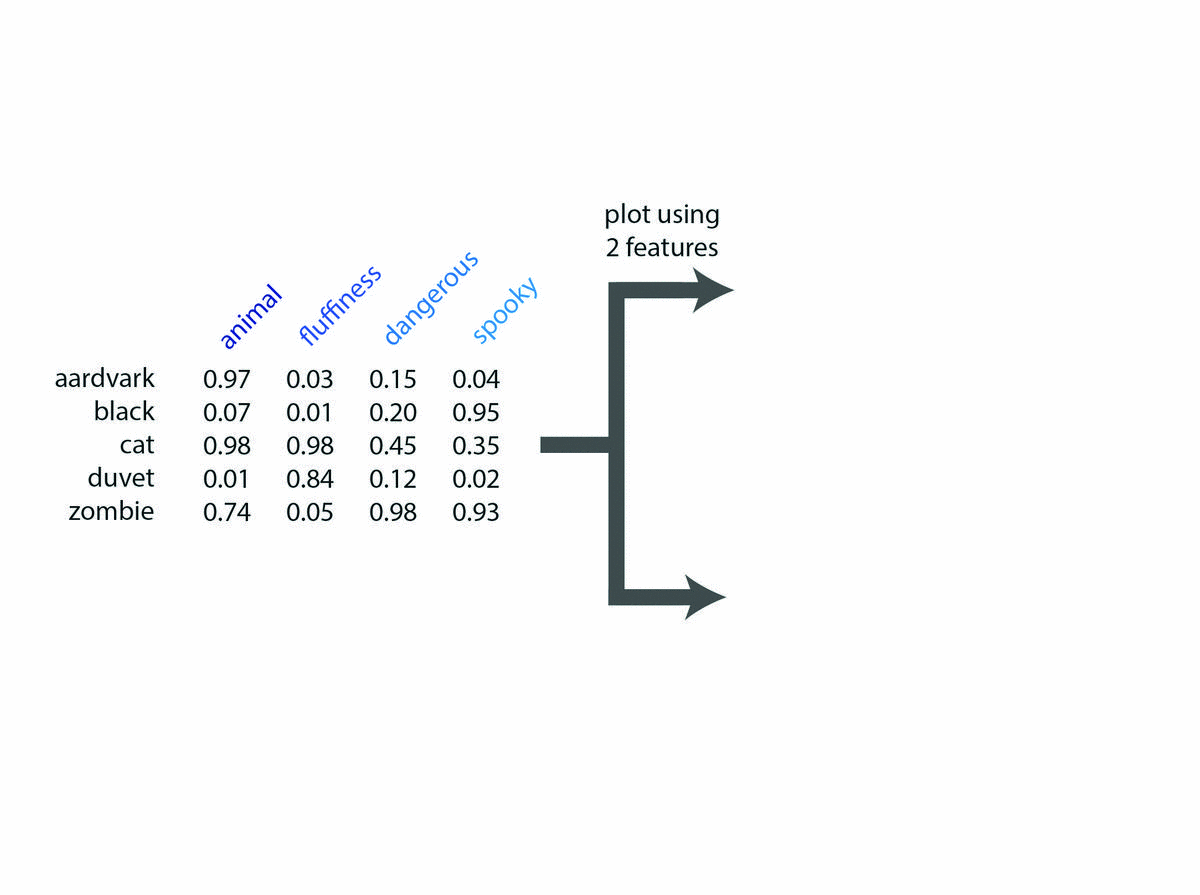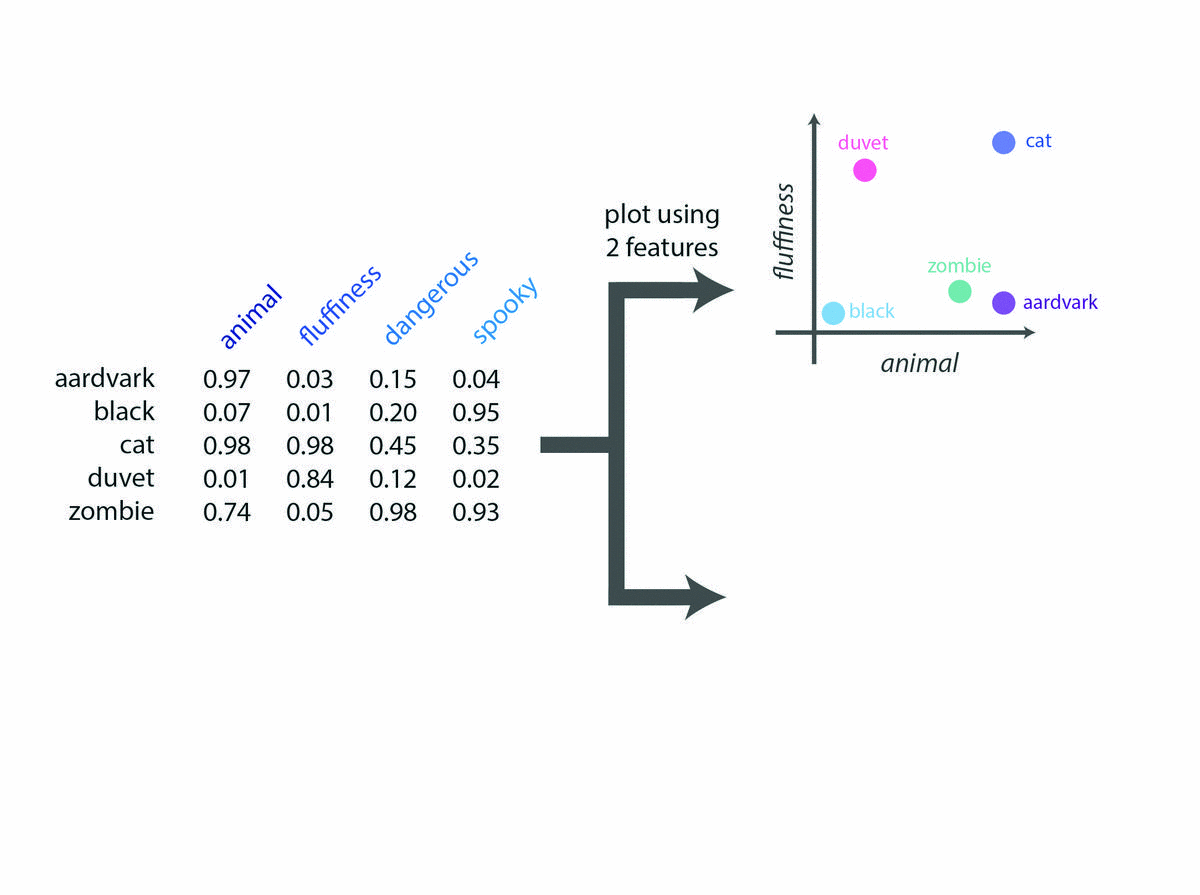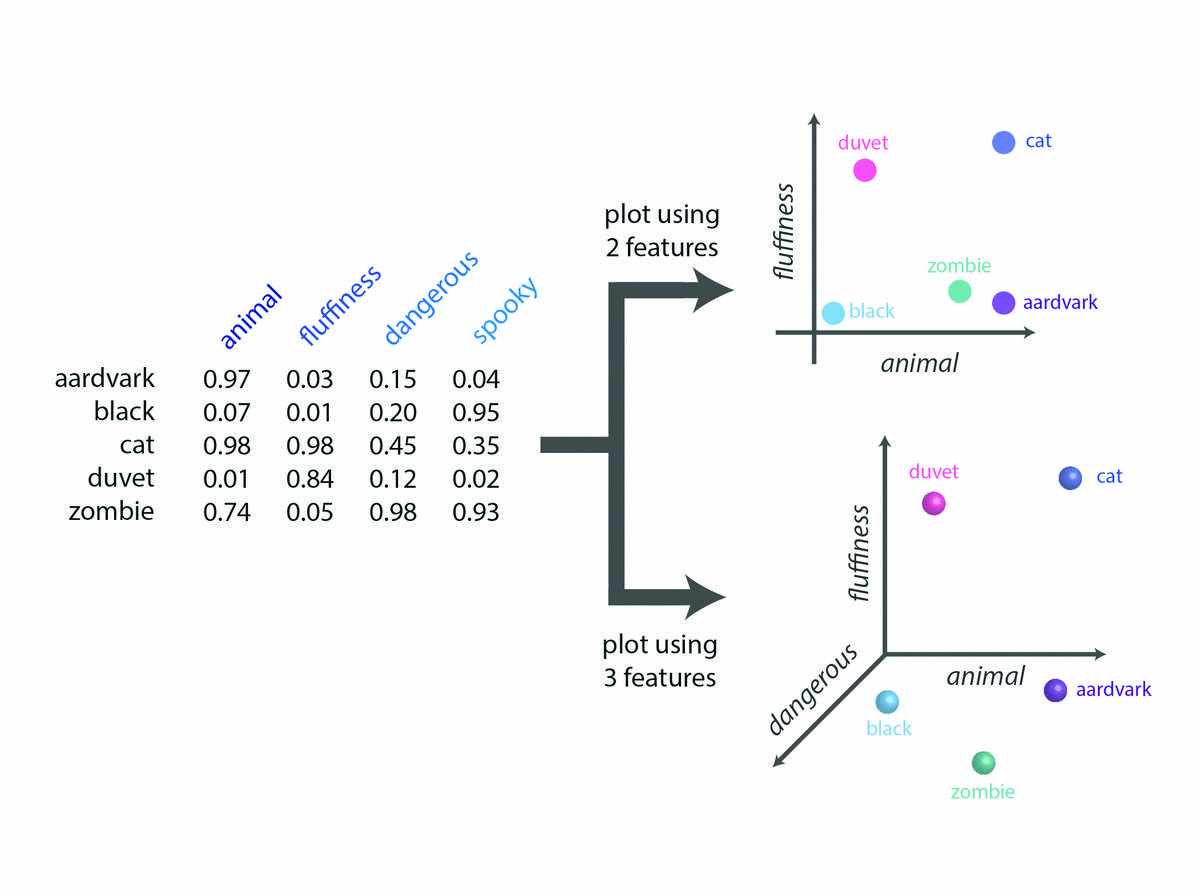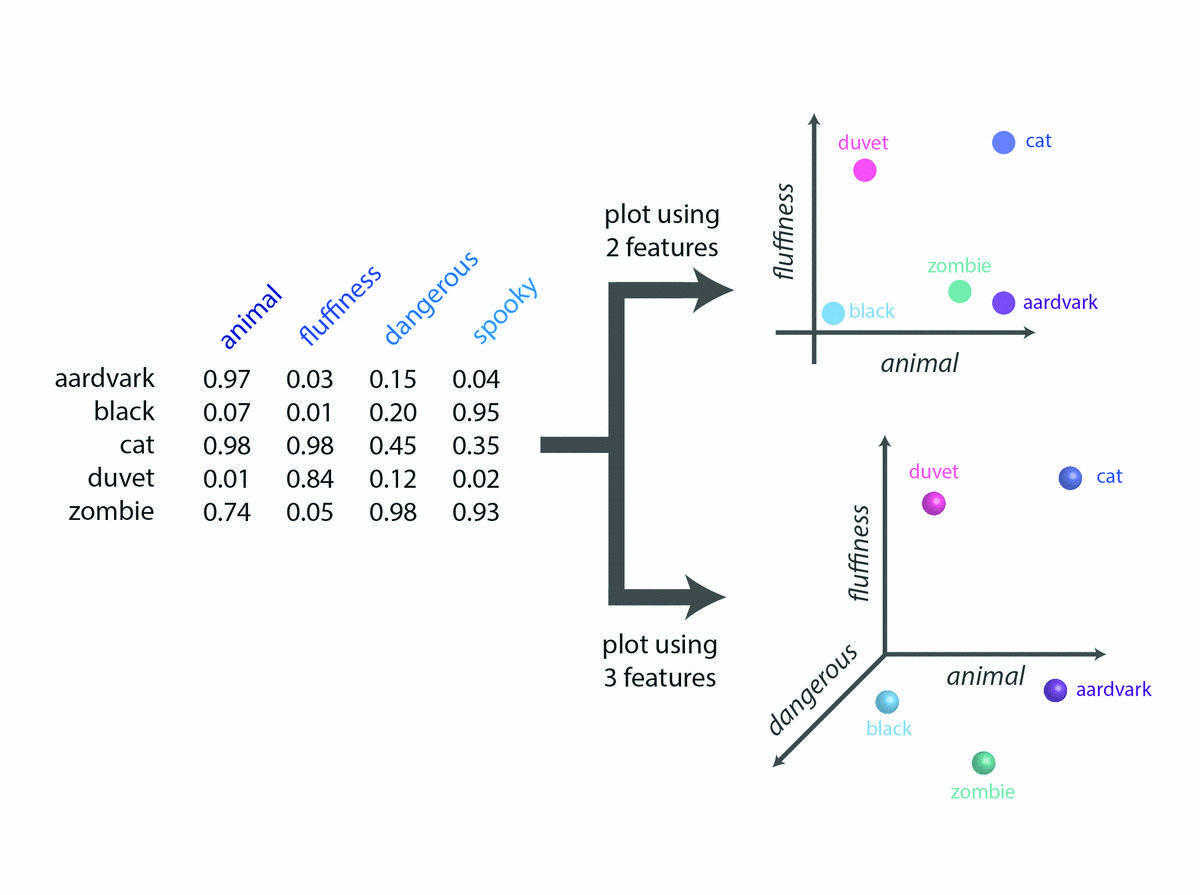
Organizing by Similarity and Dissimilarity
Each word is then given specific coordinates within that space based on its specific values on the features in question. The good news is, this is not a manual job. The computer assigns these coordinates based on how often it “sees” the co-occurrences of words.
For example, the words “cat” and “aardvark” are very close on the “animal” axis. But are far from each other on the scale of fluffiness. And the words “cat” and “duvet” are similar on the scale of fluffiness but not on any other scale.
Word embedding algorithms excel at encoding a variety of semantic relationships between words. Synonyms (words that have a similar meaning) will be located very close to each other.
The counterpart is that often antonyms are also very close in that same space. That’s how Word2vec works. Words that appear in the same context – and antonyms usually do – are mapped in the same area of space.
Other Semantic Relationships
Other semantic relationships between words, for example, hyponymy (a subtype relationship, e.g. “spoon” is a hyponym of “cutlery”) will also be encoded.
This method also helps establish the relationship between specific target words, for example:
- A leopard print was seen in the mud.
- That’s a beautiful leopard print on your coat.
- I bought a leopard print with a black frame.
The system encodes that the target word “leopard print” appears within sentences that have the words “mud,” “coat” and “frames.” (This is called a word window. Older models like word2vec have a small window, with the targets being within 3-5 words.)
By looking at what is before and after a target word, the computer can learn additional information about each word. It can then locate it as precisely as possible in abstract vector space. This helps the system make an efficient estimation of word context even when infrequent words are used.
So to summarize, under this method, words are analyzed to see how often they appear near each other (co-occurrence). Thus, word embedding algorithms capture word context in a document, semantic and syntactic similarity, relation with other words, and so on.
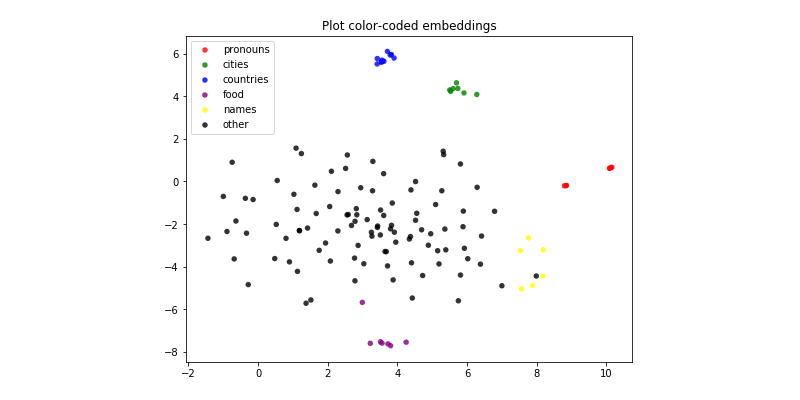
As you can see below, similar words and similar vector representations are assigned. This method was able to encode the meaning of words and cluster them according to categories. Such as cities, food, countries, and so on.resentations are assigned. This method was able to encode the meaning of words and cluster them according to categories. Such as cities, food, countries, and so on.
Recap: word2vec Still Matters, Even as NLP Evolves
Word2vec is still in use because it is relatively simple, efficient, and effective. It’s best suited for tasks requiring basic word similarity and semantic relationships (expanding search queries, for example). To understand word2vec means understanding how humans learn language, including structural and semantic relationships between words.
In brief: word2vec uses shallow neural networks with either CBOW or Skip-gram architectures to generate a single vector for each word regardless of context.
Of course, our methods for generating word embeddings have evolved. Transformers, for example, provide a more complex and computationally intensive method with advanced capabilities (context-sensitive embeddings, for example). Tools like Gensim provide an interface for using word2vec and other models, such as FastText and Doc2Vec.


