

Have you ever found yourself wondering, ‘what is prod2vec‘? Probably not, right? After all, it’s unlikely that many of us have given a thought about how a website emulates a great store experience.
After all, the sign of a great, intuitive design is one that often goes unremarked upon. But if you want to design a retail site that visitors flock to (and customers do want great ecommerce experiences — 93% expect the online experience to be at least equal to if not better than in-store), then you’ll want to know all about a machine learning model called prod2vec, or product embeddings.
Because (not to pick on Amazon) if your site offers recommendations, you don’t want to be on the receiving end of this:
So how did we get from great ecommerce experiences to recommendations and product vectors? Well, it all starts with intent.
How Do You Determine Intent ?
In a traditional shopping scenario, a sales assistant has the advantage observing a shopper’s movements, what displays or products draw their interest, or (even more revealing) ask them questions. Are you shopping for yourself or someone else today? If themselves, their physical appearances can also be decoded by the store clerk.
But how do you determine a customer’s intent when they’re not in a physical store? You might think this is solved by big data analysis; we’re going to lay out how really small data will provide very actionable recommendations.
Rules-based Approach to Figuring Out Intention
First, it’s important to consider that recommender systems, historically, were made by looking at purchasing patterns to observe that “when a person buys this … they might like that.” Rules were created that enabled the system to recommend similar products along these predefined but static dimensions.
Of course, the caveat is that your team must be maniacal about tagging products with descriptive item metadata such as brand, size, or color, purpose, etc.
This method is horrible for a number of reasons, which you might be able to infer. It doesn’t scale. It ties up your staff with tedious and truly boring tasks. It isn’t great at determining which products are complementary to one another from a customer’s perspective. It’s based on generalities and doesn’t figure into shoppers’ individual preferences and experiences.
In other words, it falls well short of the in-person experience. But there still is a way to deduce intent — and that is to observe what the shopper is doing.
Deducing Intent From Behavioral Data
While the machine can’t physically see the person’s age, gender, body type, clothing, hairstyle, race, and can’t hear their tone of voice, there is behavioral data to clue you in.
On an ecommerce site, you have shopper interactions: clicks, scrolls, queries, category selections etc. These can be from either authenticated users and anonymous ones (cold start users); and you’ll have historical data from both groups. We call this first-party data. It’s an activity that happens on your site and it provides you with rich information about your visitors’ intentions.

To understand intent, your tech stack needs to be advanced enough to understand what the person is typing and doing, and be able to relate it to the existing product catalog — and what people have done in prior sessions.
For our purposes, a session is a series of product page views that have been viewed within a given time frame. A session can be real time or historic. When a person comes to your site, within three key strokes you should be able to discern the next best recommendation based on the path that person is taking.
What gets you there are product embeddings.
What Are Product Embeddings?
Product embeddings, or product vectors, are ways to represent products. Products are assigned positions in a multi-dimensional abstract space, based on clickstreams; also known as paths or routes others have taken to get to those products. The numbers that are closer together reflect products that are similar in that space.
To conceptualize this a bit more, consider how a sales associate might learn to provide great customer service. Over time that person has observed that if shoppers come into the store looking at tennis rackets, they might continue around the store looking at tennis balls, tennis shoes, or tennis apparel.
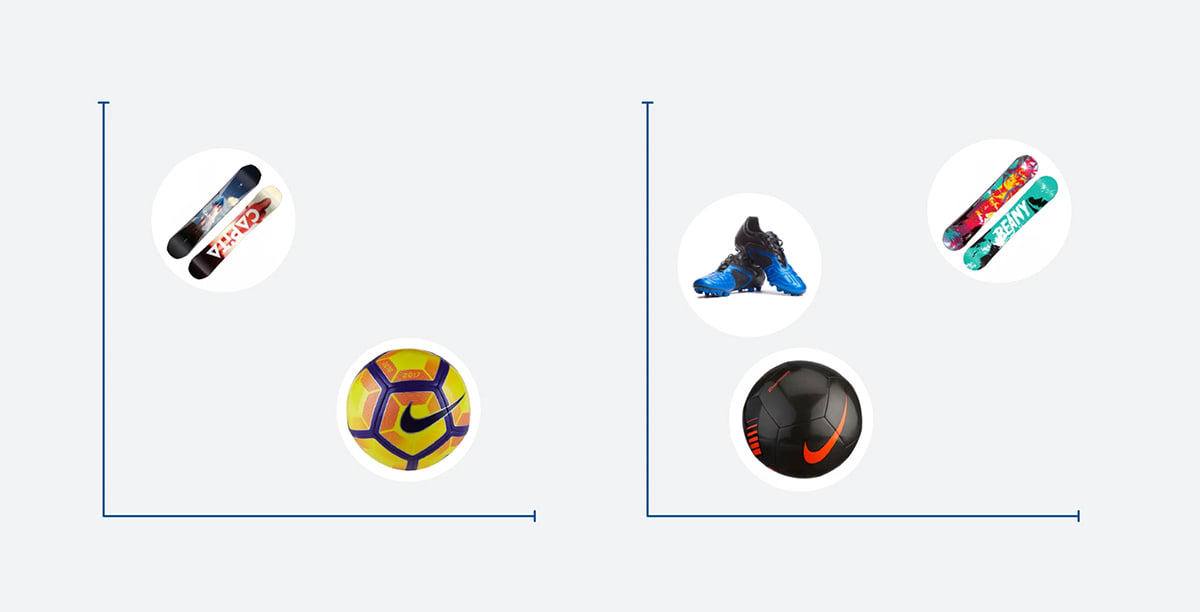
Without any other knowledge of tennis, a store clerk could confidently recommend that the shopper consider balls and shoes. However, over time and experience, the clerk might also recommend sweat bands or an athletic bag that is not necessarily stored in the same area as tennis equipment.
In the digital space, the machine takes the place of the human sales associate.
The tennis racket in your online catalog is assigned a matrix of numbers — dynamically derived from all the other sessions people have taken that included that racket. Also the machine learns based on behavior patterns of shoppers what products are more closely aligned — beyond logical placements such as categories/brand/usage.
In our previous example, the sweat bands might therefore have a very close spatial position to the tennis rackets. As products are assigned positions in this product space, each product’s position is called a product vector.
What is Prod2Vec?
Prod2Vec was inspired by the word embedding technique in natural language processing, and the machine learning model Word2Vec. Instead, product embeddings are conceptual relationships between different products and their attributes — all determined by the path people take to get there.
Language Vector Space vs Product Vector Space
Let’s compare how language vector spaces and product vector representation are similar to one another.
In language vector space, terms that are similar or belong to the same semantic domain (e.g., “king” and “queen”) are located close to each other.
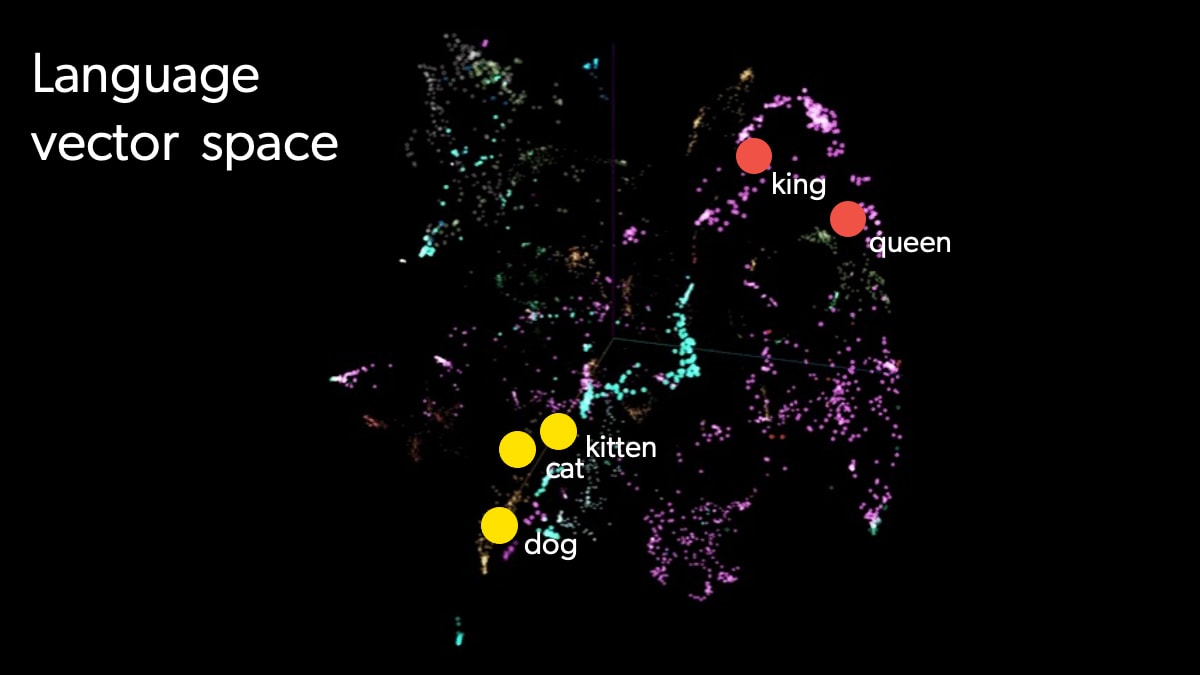
Similarly, in the product vector space, products that are “related” to each other in some way will appear closer together:

“You don’t need to know the intention,” says Ciro Greco, VP AI at Coveo. “The machine model will learn what people click on and try to extract from that.
“Since people don’t browse randomly,” Greco explains, “we kind of piggyback on the fact that people browse for things that are similar or somehow conceptually related. Maybe somebody is not necessarily browsing for something similar but rather stuff to play tennis for the first time and that is going to include a pair of shoes, a racket and a tee-shirt. If the model does its job correctly, these similarities, and even dimensions of similarities, will emerge.”
Products are dynamically assigned a number, and products that are closer in that vector space will have a relationship. Because people (in aggregate) don’t browse randomly, you can offer recommendations based on the proximity of one product to another in that space.
Creating a Product Space
In product embeddings, context is determined by the clickstream in a browsing session. The assumption is that products that are related to each other tend to appear in the same browsing sessions. For example, when a user is training for a marathon, they might browse for running shoes and other related products in the same session.
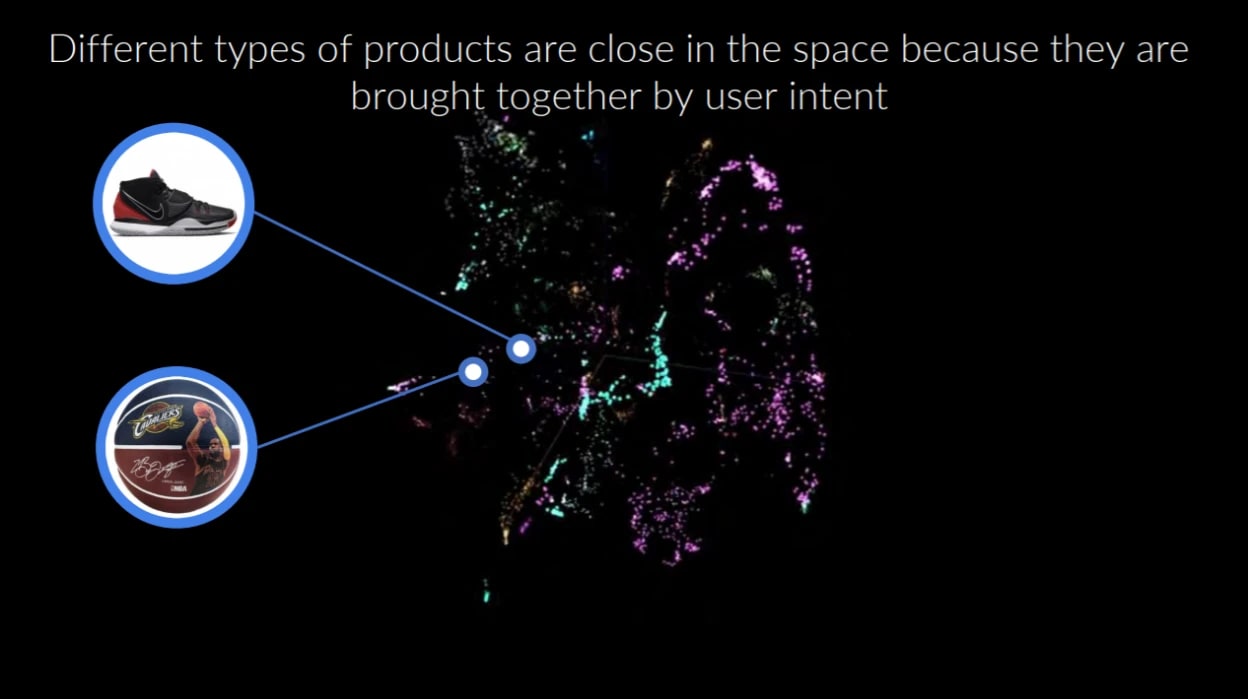
This entire product space representation is the output of what shoppers have done in the past. When a new shopper comes into the space, the model looks at the sequence of behaviors — and puts the person on a path that others have taken. So you can serve up highly nuanced recommendations based on this session analysis.
This is an ideal solution for retailers to personalize for the myriad of shoppers who are now shopping anonymously. According to research from Bluecore, more than 75% of shoppers aren’t logged in. You don’t know who these people are at all.
Why Do We Need Product Embeddings for Recommender Systems
Prod2Vec or product embedding is a very powerful and flexible machine learning concept that is able to encode relationships between products — as well as the ways individual shoppers think about these products and their attributes.
This is important as this allows us to solve a major problem that most ecommerce sites have to deal with: the small data problem.
Amazon and Netflix have given the impression that they are providing highly relevant and personalized results — because they have the benefit of big data. But most ecommerce sites don’t have access to the huge volumes of customer data that digital giants have. At best, your customer logs in only once in a while, and more often than not they’re a one-time visitor.

Prod2Vec allows you to personalize recommendations without any prior data about the shopper (good news as cookies start to disappear). And without all the manual intervention found in rules-based systems.
By capturing user interactions, and how they engage with products and their attributes, the system is able to match that information to the existing product space, modify it according to the individual customer’s needs and preferences and help them find exactly what they’re looking for — and more.
And providing people with what they really want increases the likelihood of conversions.
We’ll delve more into specific examples of product embeddings and how they help create personalization. Stay tuned!


