
Generative AI has moved from research labs into boardrooms, design studios, and development pipelines—reshaping industries in real time. Over the past year, we’ve seen the rise of advanced models like diffusion architectures (e.g., Stable Diffusion and DALL·E 3), multimodal transformers (like GPT-4 and Gemini), and open-source challengers that are accelerating innovation across the AI ecosystem.
At its core, generative AI refers to a class of models capable of producing original content—text, images, audio, code, and more—by learning patterns from large datasets. These models are not just supporting human creativity and productivity; they’re beginning to augment and automate entire workflows, from customer service to software development.
In this guide, we break down five foundational types of generative models—GANs, VAEs, autoregressive models, flow-based models, and transformers—and explain how they work, where they excel, and why they matter in an enterprise context. Whether you’re evaluating AI solutions or simply trying to keep pace with this fast-moving field, understanding these models is key to making informed, strategic decisions.
What is a Generative AI Model?
Generative AI models are a type of machine learning model that generates new data similar to the data on which it was trained. These models are called generative because they create something new; for example, images, text, video and audio.
In the realm of artificial intelligence, generative models play a pivotal role in teaching computers to understand the real world and generate novel content that resembles the original data. They are used in unsupervised machine learning (more on this later) to discover underlying patterns and structure in unlabeled training data.
Real-World Applications of Generative AI Models
Generative AI is more than just a technical breakthrough—it’s rapidly transforming how industries operate and innovate. Here are some real-world applications that highlight the power and versatility of generative models:
- Image and Video Generation: GANs and diffusion models are widely used in media, fashion, and gaming to create hyper-realistic visuals, synthetic training data, and even virtual try-on experiences.
- Text Generation and Summarization: Transformer-based models like GPT and BERT power AI-driven chatbots, automated content creation, and summarization tools used in customer service, publishing, and enterprise knowledge management.
- Synthetic Voice and Music Creation: Models trained on audio data can generate lifelike speech for virtual assistants, audiobooks, or voiceovers, and compose original music tracks for entertainment or branding.
- Drug Discovery and Molecular Design: VAEs and flow-based models assist researchers in generating novel molecular structures, accelerating innovation in biotechnology and pharmaceuticals.
- Code Generation and Automation: Codex-style models are being used to write code snippets, automate repetitive programming tasks, and support developers in integrated development environments.
These examples illustrate how generative models are already delivering tangible business value, with applications poised to expand as the technology matures.
How Do Generative AI Models Work?
How do they work? To create a generative model, an organization usually requires a large data set that is fed to the model in a process called training. The model learns the patterns in the data, adjusting its parameters to match the distribution of the training data. Following the training period, the model can generate new data that resembles the original data.
A generative model’s significance lies in the high quality of its output and creativity – its ability to ascertain the patterns in data and create something new from its learnings – which has boundless applications across many fields. They particularly shine in tasks that require new content or augmentation of content such as creating human faces with a range of different emotions or generating a new art piece in the style of Monet.
Although generative models have been around for some time, new algorithms, increased computation powerthe advent of deep learning and the availability of vast amounts of data have led to significant and exciting advances. Deep learning, a type of machine learning in which computers learn through interconnected neural networks fashioned after the human brain, led to the ability to develop more sophisticated models with much more realistic outputs. The models we highlight in this article belong to this class of “deep generative models,” which is a subset of generative models that relies on layers of neural networks to learn complex and hierarchical representations of data. The “deep” refers to the multiple layers of interconnected neurons in the neural network architecture.
ChatGPT, for example, was trained on a transformer-based generative model. GPT stands for Generative Pre-trained Transformer, a type of transformer-based neural network architecture designed for natural language processing tasks such as generating texts from prompts.
Machine Learning Vocabulary
Let’s distinguish between a couple sets of terms used in the field of AI to help us further understand generative models.
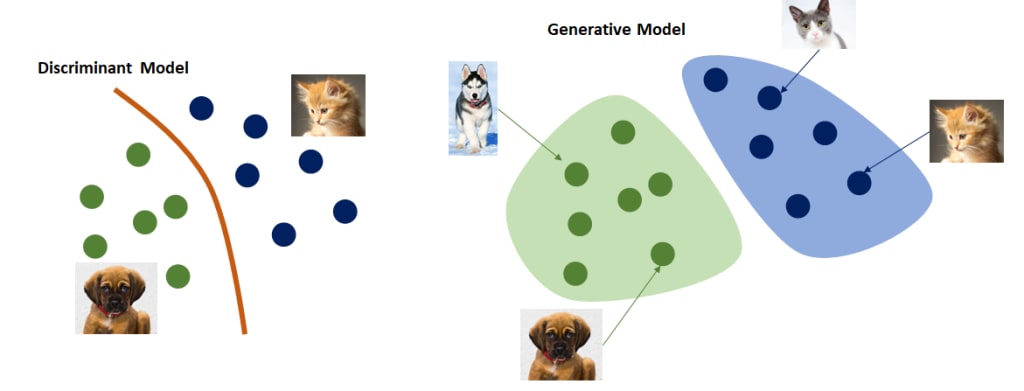
- Generative vs. discriminative models. There are two distinct types of machine learning models. Generative is a class of statistical models that generates new data instances by learning the underlying structure of input data. Discriminative models, on the other hand, do not generate content. They learn to distinguish between different kinds of data instances and are useful for tasks such as classification. A discriminative model, for example, can differentiate a lily from a rose. A generative model can generate new images of flowers.
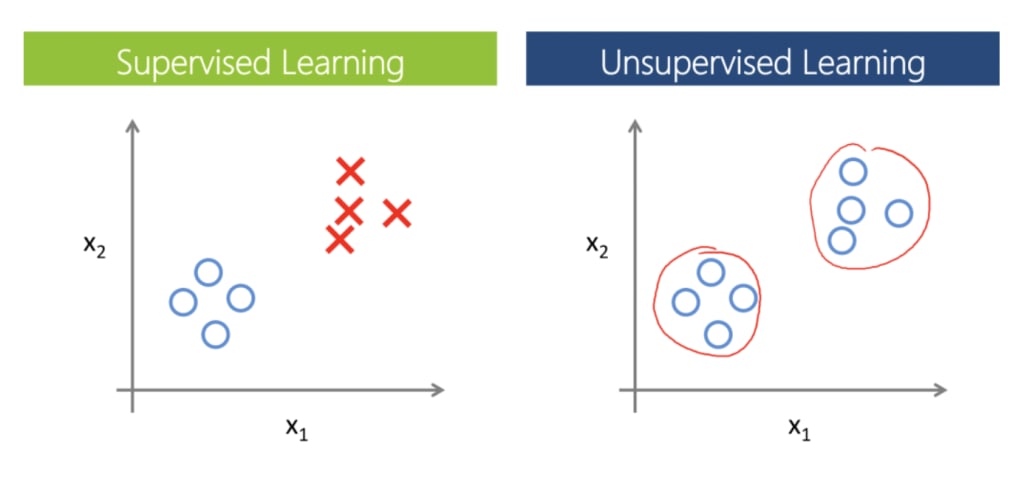
- Supervised vs. unsupervised learning. There are two main approaches to machine learning called supervised and unsupervised learning. In supervised learning, algorithms are fed a dataset of inputs that they learn to associate with a set of expected outputs. Supervised learning depends on human supervision. Generative models typically fall under unsupervised learning, in which algorithms learn on their own to identify patterns and structures in the data without outside guidance. Both approaches have their uses and strengths in ML applications.
Generative models are actively applied today across a diversity of areas including computer vision, natural language processing, art creation, and music composition. They have the potential to open up businesses to new avenues of creativity, content generation and complex problem solving.
Generative Model Types
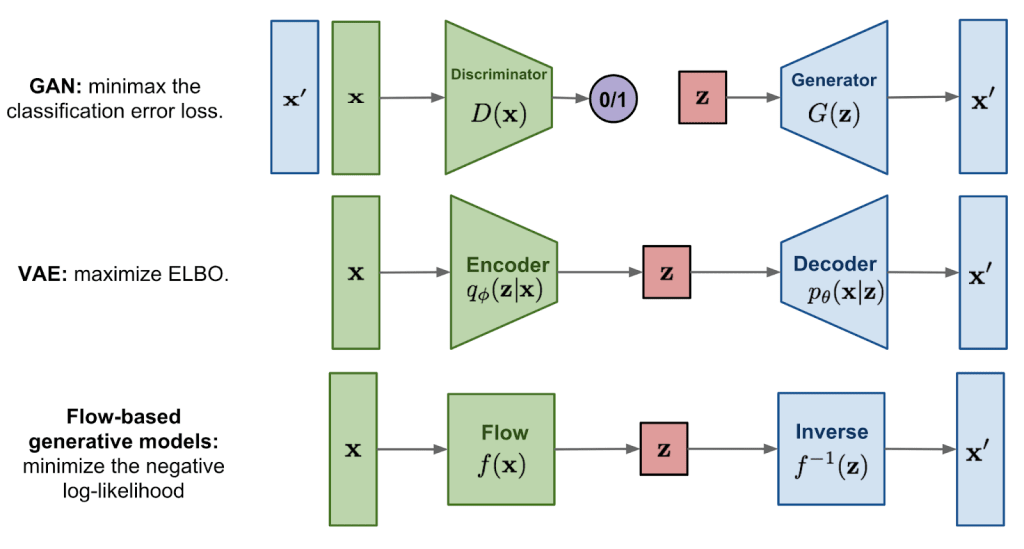
Generative models have seen some of their most significant advances in recent years. In 2014, Ian Goodfellow and his colleagues introduced generative adversarial networks (GANs), which utilized a new training framework involving two neural networks, a generator and discriminator, that compete against each other, leading to incredibly realistic outputs such as in audio or image generation. Other advances since include the development of variational autoencoders (VAEs) and large-scale pre-trained language models using transformers. Let’s examine these and other major types of generative models in use today.
Generative Adversarial Network (GAN)
One of the most powerful AI technologies in development today is generative adversarial networks, which encompass a relatively new way for machines to learn and create that are leading to highly successful results.
Architecture and training process
GANs are adversarial in nature and involve a game between two deep learning submodels called the generator and discriminator.
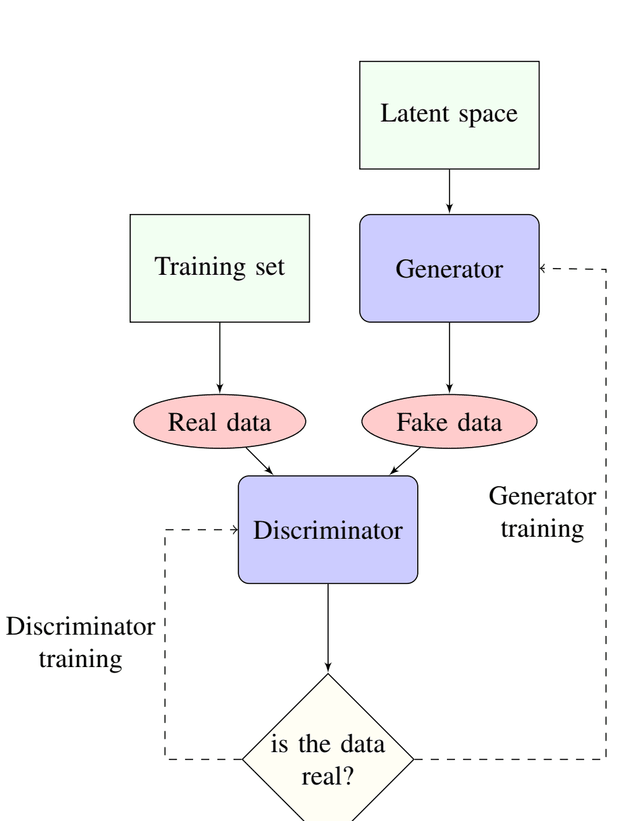
The generator learns to create fake data that resembles the original domain data. The discriminator learns to distinguish between the fake data from the generator and the real data. At first, the discriminator can easily tell the two sets of data apart. As training progresses and the models make adjustments according to the results, the generator improves until the discriminator struggles to easily distinguish the fake from the real data. Through these iterations, GANs achieve a level of realism and authenticity in its output that can fool the human senses, such as videos of destinations that look like real places or photographs of corgis in beachwear that appear to be real dogs.
Applications
GANs are typically employed for imagery or visual data, including image generation, image enhancement, video predictions and style transfer.
Strengths
GANs excel at generating high-quality and realistic content, particularly when it comes to images.
Weaknesses
GANs have been known to be difficult to train due to instability in the interactions of the two submodels. The generator and discriminator can fail to reach an optimal equilibrium or state of convergence, oscillating in their abilities to outperform each other. This instability can lead to mode collapse, which means the generator learns to only create a limited subset of samples from the target distribution rather than the entire distribution. For example, a GAN trained to create cat images may start creating only orange tabby cat images. This limitation in generated samples means a degeneration in the quality and diversity of the output data.
Variational Autoencoder (VAE)
The second prominent generative model in use today is variational autoencoders. VAEs are a deep generative model that, similarly to GANs, rely on two neural networks to generate data. Traditionally, VAEs work to compress and reconstruct data, which is useful for tasks such as cleaning data and reducing the dimensionality of data sets to, say, improve the performance of an algorithm.
Architecture and training process
The dual networks, called encoders and decoders, work in tandem to generate an output that is similar to the input.
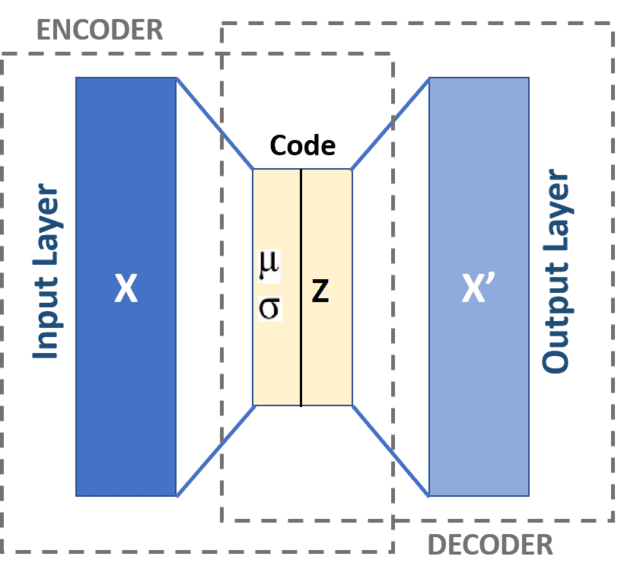
The encoder compresses the input data (into what’s called the latent space) to optimize for the most efficient representation of the original data while retaining only the most important information. The decoder then reconstructs the input from the compressed representation. The decoder in this way generates content and is able to achieve a high-level of detail to generate specific features.
Applications
VAEs are great for cleaning noise from images and finding anomalies in data. They are also flexible and customizable to specific tasks compared to other approaches.Today, they are used for anything from image generation to anomaly detection such as in fraud detection for financial institutions.
Strengths
VAEs learn a probabilistic distribution over latent space, allowing for quantifying uncertainty in data and anomaly detection. They are also easier to train and more stable than GANs.
Weaknesses
A weakness of VAEs is they tend to produce lower quality content, such as blurry images, compared to other methods like GANs. They also struggle to capture complex and highly structured data.
Autoregressive Model
The next class of models, autoregressive models, is a more straightforward approach to generative modeling. It predicts the next part of a sequence based on conditions from previous inputs. Put simply, autoregressive models predict the future based on the past.
Architecture and training process
This model’s training consists of a sequence of input-output pairs, such as a sequence of words from which the next word in the text is predicted. Autoregressive models are commonly used with recurrent neural networks (RNNs) and transformer-based models.
Applications
Autoregressive models are commonly used in text generation, language modeling and forecasting. They are best used for modeling sequential data such as in text, audio and time series prediction. Because autoregressive models can capture complex interactions in the data, they are useful for natural language text generation tasks. They are also useful for generating predictions in time series data such as forecasting stock prices and the weather. In image generation, these models are commonly used to complete images.
Strengths
Autoregressive models are well-suited for use cases involving sequential data modeling. They are particularly good at capturing the dependencies and patterns of sequential data, which means they can generate accurate contextually relevant sequences.
Weaknesses
These models can require large volumes of training data and resources.
Flow-Based Model
Flow-based models learn the mapping between a simple distribution of data and the complex distribution present in real-world data. A distribution of data refers to the way the values in a dataset are spread across the possible outcomes, which, for our purposes, captures the underlying patterns and structures of data. A series of invertible transformations, or flows, map samples from the input distribution to samples from the target distribution. By learning the distribution of data they are trained on, the model generates new samples similar to the training data.
Flow-based models use the technique of normalizing flows, which is a series of invertible transformations, to model complex data distributions. A definition of “invertible” is if the model transforms an input into an output, it can apply the inverse function and transform an output into an input. This means in flow-based models, you can essentially move back and forth between simple and complex distributions.
Architecture and training process
Flow-based models learn the underlying patterns and structures of data through a sequence of invertible transformations.The model generates novel content when it samples from the initial distribution of data and applies the transformation it has learned.
Applications
They are especially powerful in image generation and density estimation.
Strengths
A flow-based generative model’s strength is in its ability to calculate the exact likelihood of occurrence of a data point in its learned distribution. They can effectively capture complex data distributions. They also are known for more stable training.
Weaknesses
They can struggle with long-range dependencies or structured interactions in the data.
Transformer-Based Model
Much of the recent excitement around generative AI has been around transformers, which is the underlying deep-learning architecture of large language models like the GPT series and Google LaMDA. Introduced in 2017, transformers can effectively generate a large variety of language-based content including text and computer code from training on large datasets. They excel at sequence-to-sequence interactions. Coveo also specializes in transformer-based models, enabling the democratization of AI for the enterprise.
Architecture and training process
Transformers use a technique called self attention to keep track of the relationships between words. This allows machines to develop a sense of context between words. Transformers analyze pieces of text concurrently, which leads to the ability to analyze large data sets at scale.
Architecture of the transformer used in BERT.T.E: text embedding; S.E: segment embedding; P.E: positional embedding. Source: Modified from Alammar (2018)
Applications
These models are used for a wide variety of language generation tasks including summarization, language translation, text completion, chatbots, recommendation engines and sentiment analysis.
Strengths
Transformer-based models are highly versatile and useful for scaling up large language models.
Weaknesses
Their limitations include the requirement for large data sets and high costs to train. Since the models are large, researchers and users find it challenging to see clearly into its inner workings, for example to isolate the source of bias or inaccuracy.
Comparing Generative Models
As seen above, there are a variety of generative models, and we only touched upon some of the major ones in use today. Let’s summarize how the models we highlighted compare:
- GANs generate highly realistic images, but they can be unstable and difficult to train.
- VAEs are easier to train than GANs and great for probabilistic data representation, but can produce lower quality results.
- Autoregressive models are good for predicting the likelihood of time-series events, but can be expensive to train, particularly for long sequences.
- Flow-based models produce high-quality image generation and are computationally efficient, but struggle with long-range dependencies in data.
- Transformer-based models excel in natural language processing tasks and complex sequence generation, but are expensive to train.
With each generative model displaying their own sets of strengths and challenges, organizations will benefit from carefully considering the ones best suited for their needs.
Ethical Considerations in Generative AI
As generative AI becomes more accessible and powerful, so do the ethical questions surrounding its use. Businesses adopting this technology must consider not just what generative models can do—but what they should do. Here are a few core concerns shaping the conversation:
- Misinformation and Deepfakes: Generative models can fabricate highly realistic text, images, and videos, raising the risk of disinformation and reputational harm if used irresponsibly.
- Bias and Fairness: Since these models learn from human-generated data, they often inherit and amplify biases. Without proper oversight, outputs can reinforce harmful stereotypes or exclude underrepresented voices.
- Intellectual Property and Ownership: Who owns AI-generated content? This question is increasingly complex, especially as generative tools remix or emulate existing styles and works—potentially infringing on copyrights or creative rights.
- Transparency and Accountability: Enterprises must ensure that AI-generated content is clearly disclosed, traceable, and auditable—especially in regulated industries or consumer-facing applications.
By addressing these concerns proactively—with governance, monitoring, and ethical frameworks—organizations can harness the power of generative AI while maintaining trust and integrity.
Looking Forward
Generative AI is no longer speculative—it’s strategic. As foundational models continue to improve in accuracy, speed, and versatility, their real-world impact is expanding across sectors. From enhancing customer experiences to accelerating R&D and creative production, generative models are becoming critical components in digital transformation efforts.
For enterprise leaders, the key isn’t just understanding how these models work—but knowing where and when to deploy them for maximum value. Whether you’re exploring AI-generated content, dynamic personalization, or intelligent automation, a foundational grasp of generative models will equip you to navigate this evolving landscape with confidence.
As the technology matures, ethical use, governance, and responsible AI practices will also play a central role. The organizations that thrive in this space will be the ones that combine innovation with intention.
Dig Deeper
Hallucinations, compliance gaps, and poor relevance are just a few of the negative outcomes risked without robust retrieval. Simple RAG frameworks fall short in enterprise environments; they can’t handle the complexity of dispersed content, strict access controls, or the need for real-time accuracy.
This guide explores how relevance-augmented retrieval transforms LLMs into secure, scalable, and trustworthy AI systems.