

Enrichment—a word that you can almost feel, like rubbing silk between the fingers—conjures images of incremental luxury, of things getting better bit by bit until they are almost perfect. That’s what enriching your data can do for search: make it better and better.
Search seems like such a straightforward concept—ask a question and get an answer—but that’s different from getting a relevant answer.
For relevant answers, we need to move beyond keyword search, the bread and butter of information retrieval for the past three decades, to enriching our data with metadata and information about the user.
When keywords don’t match—you can end up with a recall of zero. (This is the kiss of death in the ecommerce world and is becoming just as deadly in site search.) No one wants to waste time trying to figure out how they should ask a question to get the response they need. And that brings us to enrichment. For years enrichment has happened only on index, but with machine learning we can enrich in real-time – or on query. Each approach has a role to play.
Enriching With Metadata on Index
In ecommerce, where a null search result means leaving money on the table, merchandisers often manually pore over log files looking for misspellings and synonyms. It’s an odious, yet necessary, task that requires looking for queries that didn’t yield the right result. These words and typos are carefully added to a thesaurus or dictionary as metadata—and all that valuable metadata is, in turn, indexed. We call this enrichment because we have made our data better.
This enrichment, done at time of index, greatly improves the odds of returning results from keyword search since it now includes looking for synonyms and misspellings for search terms.
About a decade ago, I worked for a text analytics company and our promise was to help do away with some of the dumpster diving through log files. It worked like this: as the content was being uploaded, the text analyzer could automatically categorize content with some degree of certainty.
For many professions, such as media or healthcare, editors or domain specialists would verify the tags. In other industries where a mistake was not as critical, the metadata might be accepted as is. Regardless, the metadata was indexed along with the content.
We call this enrichment on index.

Shelf-Life of Metadata
But this type of enrichment introduced some new challenges.
After all, language is dynamic. And with pop culture and social media, we are birthing (and killing off) slang in ever faster lifecycles. What was “cool” for years became “lit,” “dope,” and “fire” until each has its own cooling-off period where it falls out of fashion. Because of this revolving door of word meanings, metadata that isn’t refreshed regularly can become stale and irrelevant.
My friend Isaac Sacolick was formerly the CIO at a large media company that had a corpus of well over a million documents. About every four months they would reindex their entire corpus. I reminded him of this and he visibly cringed. “I hated when we had to do that,” he said. Search response times were impacted during this process. And, he had a hefty bill after running all that content through the SaaS analyzer.
Still, it’s a necessary function.
Let’s see how enrichment can impact an ecommerce site that offers the sale of automotive parts—to both B2B buyers as well as consumers. In addition to a hefty catalog, the manufacturer also has content repositories of editorial, DIY video, documentation, and schematics.
How should it determine which content should be ranked as relevant to the following query?
Spark Plug 2000 F-250 Pickup
Users entering that string can have different intentions, such as, is it a general education question or is it intention to buy?
Indexed metadata allows us to determine that pickup can equal a truck and that F-250 is a truck model and 2000 equals a year.
That same metadata isn’t going to help determine intent—but machine learning (ML) can.
Here’s how.
Real-Time Enrichment
The word spark plug actually indicates that the person is looking to become more knowledgeable. A mechanic would know that model of truck has a diesel engine—which means it would take a glowplug.
Administrative metadata that comes off a person’s browser, the wisdom of the crowd (what others before have done), and in-session behaviors of our user are all types of enrichment—that can help deduce intent. But this type of enrichment would not be applied during index – instead it is applied at query time.
People who have searched for spark plugs on a truck have often chosen a piece of content entitled: “Maintenance schedule for F-250 diesel engines.” So the search engine would rank that asset the highest.
If the person searching has GPS enabled, the search engine will see in real-time that our searcher is actually from a latitude of 44.9778° N, longitude of 93.2650° W. Other people from similar coordinates have also chosen content about “How to start diesel engines in cold climates.”
Our machine learning models didn’t actually know our customer was from the cold city of Minneapolis – instead, it learned that others like this person often selected this second piece of content.
This is a near real-time level of context that runs on how much we know about a user during a specific session. Waiting until query time has the advantage of improving search results because they’re enriched with the information we’ve gained through user interactions during that session.
When You Should Enrich on Index
Synonyms are a popular example of index-time enrichment. In our example above, “pick up” is the same as “truck” but is “spark plug” the same as “glowplug” (and “glow plug!)”? One way to resolve this is by manually maintaining a list. Others use machine learning techniques and models like word embeddings (such as Word2Vec) to calculate the distributional relationship of words with other words to identify closely related terms.
But even these methods need context. For example, the term “pole” may have a different meaning if we talk about electricity, sports, or cartography.
A related issue with index-time enrichments is that they may not age well, as we discussed above. Words and their usages change over time. Remember in the ‘90s, when “sick” meant “cool”? And then more recently regressed to a less slangish meaning with the onset of the pandemic?
Another way to look at this is from the machine learning perspective: models that use techniques like word embeddings require more data to understand the context behind a term. This means the model will always lag behind the evolution of a language as terms go in and out of fashion. And this type of enrichment can quickly bloat an index, especially if regular maintenance fails to delete obsolete terms.
While there is a downside to overuse of enrichment at index time, there are some situations where it can be advantageous.
For example, a manufacturing catalog can quickly grow cumbersome because of the complexity of all the parts and pieces, which can impact the user experience. Unlike retail purchasers, commercial buyers are often looking for a specific part for an order. These buyers often know a product catalog better than the business themselves.
By implementing a partial value search (or wildcarding) for SKU, their user experience is enhanced by the fast retrieval of their target part from a complex array. In this case, providing them with the part, even without knowing the complete product ID or SKU, allows them to find what they want and move on to other tasks. Index-time enrichment, in this case, removes friction from the purchasing process.

WIldcarding has to be implemented artfully – otherwise, there can be downsides.
There are other times when you will want enrichment at index time. Enriching search items such as pictures for content attributes (i.e., pictures containing people) or captions is best done at index time as part of our processing of the images. The index provides us with important metadata about the contents of the pictures.
Choosing to implement enrichment at index time makes sense for many different scenarios—it just comes down to what pros and cons you and your searchers are willing to live with.
Index-time Enrichment Pros:
- Maintained by the content source (thesaurus metadata)
- Flexible in processing of text (SKU decomposition)
Index-time Enrichment Cons:
- Changing means re-indexing your corpus
- Content source must supply proper metadata (if available)
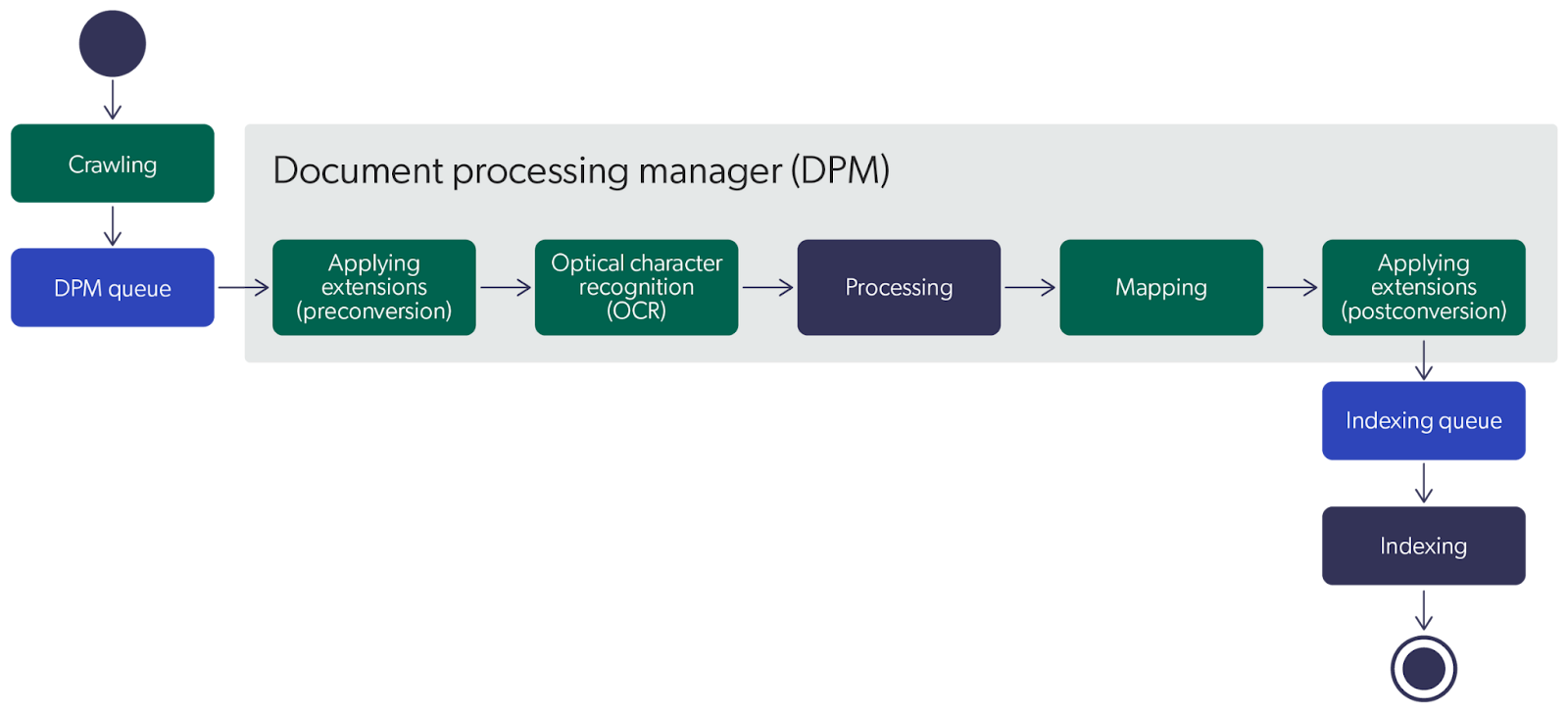
When You Should Enrich at Query Time
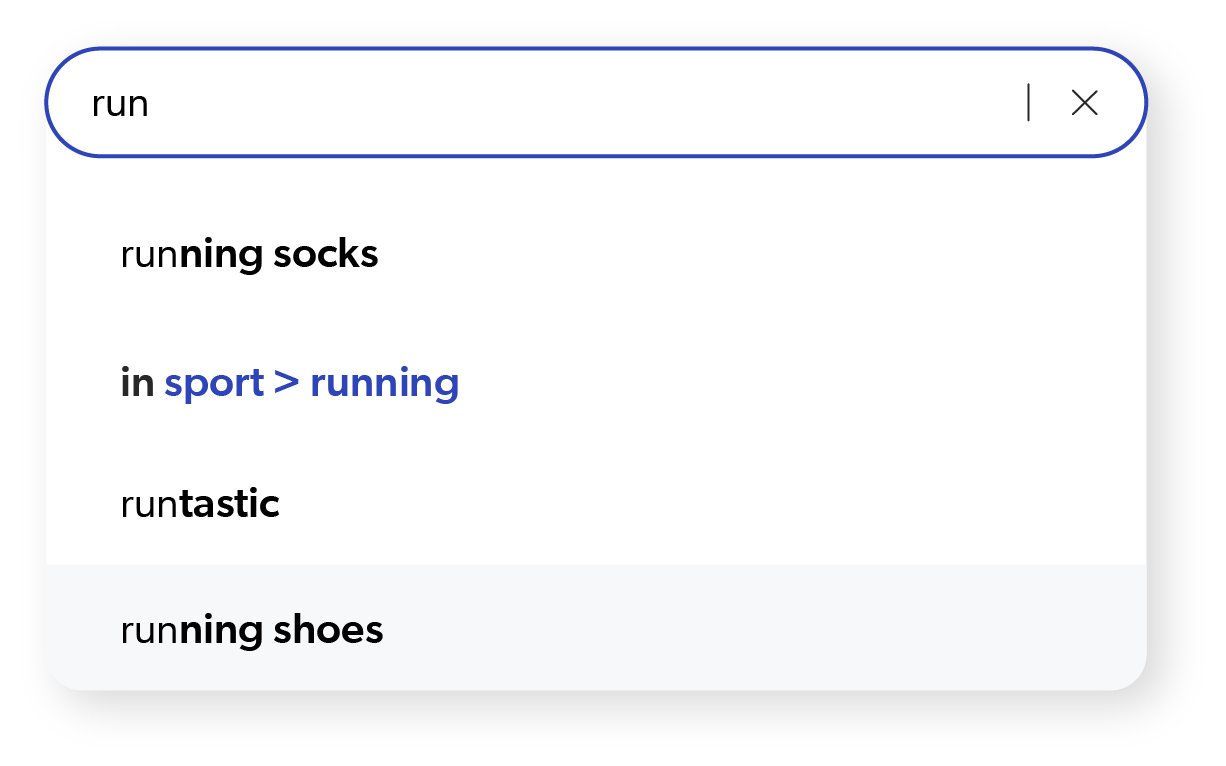
Instead of applying enrichment during the content ingestion and indexing process, you can choose to apply it when a user submits a query. This is a near real-time level of context that runs on how much we know about a user during a specific session—the more we know about them and their intent, the more relevant we can make the results.
For example, administrative metadata such as knowing the individual’s role, geolocation data, browser type and security role allows us to tailor results. Waiting until query time has the advantage of improving search results because they’re enriched with the information we’ve gained through user interactions during that session.
We can correct misspellings with query suggestions or tailor the search recommendations to bring back the most appropriate items based on the click-throughs of previous users. Users are constantly telling us what they’re looking for through their behavior during a session—we call these “signals.”
These signals feed machine learning algorithms so they can build user-profiles and other enrichments, such as determining which filters and facets to display so a user can refine their results as they wish. Signals can be everything in a browser session—search queries, revisions of queries, and what they click on.
Historical signal data train the machine learning algorithms on what others have done, providing a ‘wisdom of the crowd’ perspective that the ML model can draw upon. Real-time behavioral data informs the model about what an individual user is doing in the session. By combining these datasets together, your search provides increasingly relevant results—even for a first-time shopper, if we narrow this to an ecommerce perspective.
Query-time enrichment is also useful when users interact with your digital presence across channels. Let’s take customer service, as a different example—while 70% of customers try self-service during their resolution journey, only 9% are wholly contained within self-service. Many will frequently shift support channels, with the expectation that the level of service will continue with them. After all, there’s nothing more frustrating than explaining an issue ad nauseum to agent after agent after agent. Because enrichment is added at the time of their query, and by connecting your touchpoints with a relevance platform, relevant content and information is served to them wherever they are.
We can extend this scenario to the agent’s perspective as well—the same data that’s enriching the user’s journey can be exposed to the agent (via a device like an insight panel), giving them an insider’s look into what the user might have already tried. They can see their navigation through the site, the items they click on. To continue giving the agent the upper hand, as you might say, an insight panel can provide recommendations on what’s related to the user’s issues but that they haven’t tried—maybe insight from a recent internal Slack thread or a community forum discussion that the user hadn’t come across yet.
In this way, the tailoring of a digital experience extends into the real world and curates the interaction between the agent and the customer—personalization results from enrichment from information gained during the session.
Query-time Enrichment Pros:
- Easy to change, no reindexing necessary
- Rules can be set up by audience
- Is immediately available
Query-time Enrichment Cons:
- Requires configuration of rules
How Query Pipelines Let You Curate on a User Level
We know that different people come to a website with different intent. Information relevant to one might not be to another. For example, suppose from analysis of user actions, we defined three types of people visiting a website: learner, fixer, buyer. Let’s dig into each of these a little more.
A user who lands on a site and searches for “computer batteries” may have any number of needs. And the answer to their queries can reside in any number of places. A learner wants to know how long that battery might last, or charging tips to prolong that lifespan. A fixer would be concerned with figuring out why a battery has stopped holding a charge, and if the issue is repairable. On the tail end of the spectrum, a buyer is in the market for a brand new battery—maybe a replacement, or perhaps they’re building a custom PC. They’re searching for prices and evaluating options.
Each of these users is searching for different answers. If we don’t differentiate between them, we put the burden of sorting through one-size-fits-all results on them. But why put the burden of differentiation on you or your workers?
Machine learning and query pipelines fed by a unified index allow us to personalize query results to suit each person based on their search interfaces, the content they interact with, and other in-session data. At Coveo, a query pipeline is a set of rules or machine learning model associations that modify queries. You can use and reuse multiple pipelines to modify queries based on signals. These pipelines allow you to treat the learner, fixer, and buyer differently, even if they typed the same query. Pipelines are a way of implementing what we have learned from our ML algorithms at query time.

So, Which Enrichment Should You Use?
To circle back to our original question—query-time or index-time enrichments—what did we arrive at? The answer is, “It depends.”
You have to take into consideration your search use case—is this an ecommerce website, a workplace intranet, or a self-service support portal, to name just a few—the content you have available to answer searchers’ queries, and the journey they are currently going on contrasted with the journey you want them to go on in order to achieve a desired outcome.
Whether that means enrichment at index or query will depend on the tradeoffs that must be made to achieve a search experience that meets your audience’s expectations. The key is applying all you know about user intent to provide relevance—and you probably know more about them at query time.
Dig Deeper
One way to determine where you should apply enrichment is by taking stock of your current search experience. Here are some tips on how to evaluate it, as well as a direct line to experts who can help!
Want examples of successful search implementations? Look no further than our Ultimate Guide to Site Search User Experience for real-world use cases from Milwaukee Tool, Fasken, and CMSWire.