


Artificial intelligence (AI) is reshaping today’s business landscape. From investors betting on AI ventures to the proven benefits of AI deployments for organizations, today the relevance of artificial intelligence is undeniable.
Yet, in spite of the attention around AI, particularly in generative AI with the introduction of ChatGPT, many of AI’s key concepts remain surrounded by a surprising lack of clarity.
Machine learning, a subset of AI, is a case in point. Business leaders often struggle to understand the capabilities of new machine learning techniques and how to identify use cases to which machine learning may be productively applied.
Understanding what exactly machine learning is and debunking misconceptions are prerequisites for unlocking business opportunities and gaining a competitive edge.
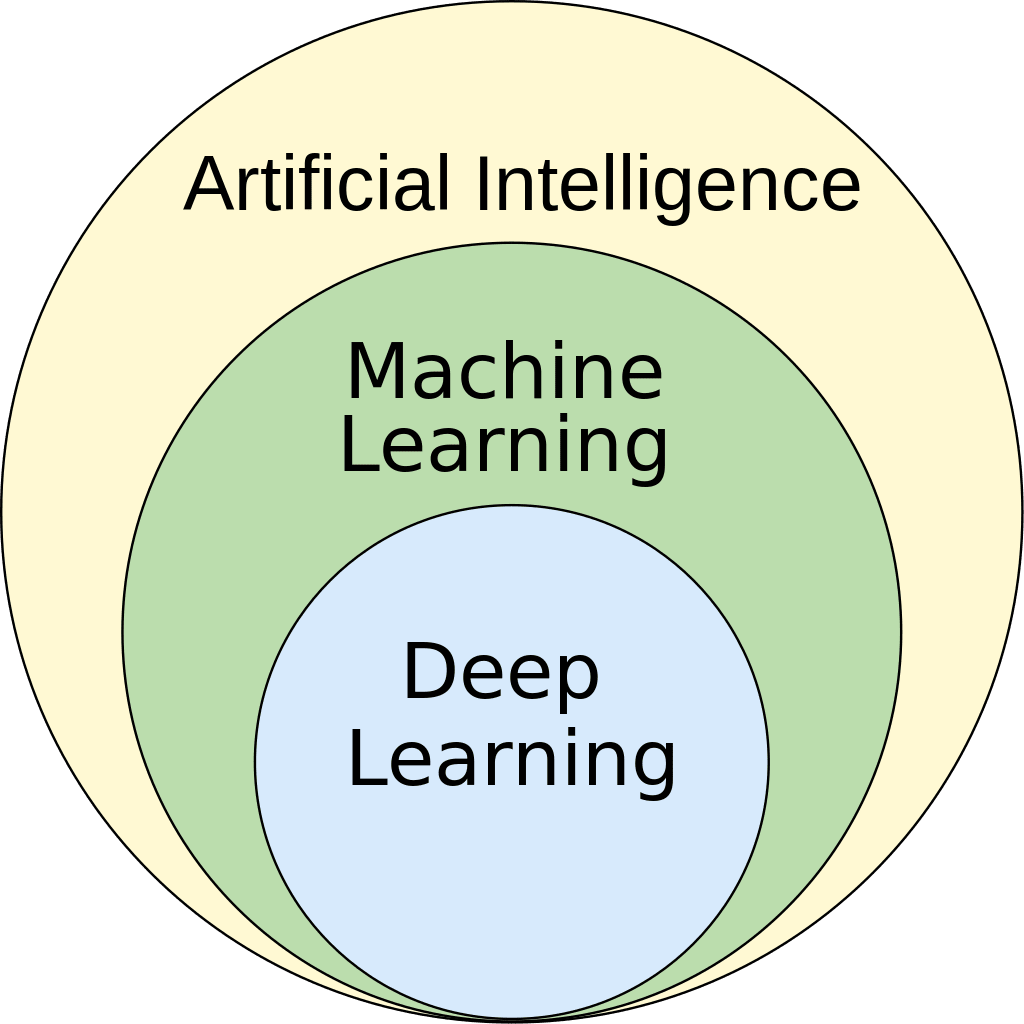
What Is Machine Learning?
Machine learning, defined by one of the field’s pioneers,is the “field of study that gives computers the ability to learn without being explicitly programmed.” It is an important part of data science in which algorithms and statistical models allow computers to learn from data and improve their performances over time. ML currently underlies a range of applications we use every day including product recommendations, voice recognition, and virtual assistants.
Fitting models to data has always been a crucial aspect of scientific endeavors. Scientists like Galileo or Newton would design experiments, make observations, and collect data. Then they would try to build models to account for the observed data and make further predictions. When their predictions failed, more data was collected and used to revise the models.
Machine learning is characterized by a similar process of data collection and model building. But in its case, computer programs rather than people analyze data and extract information. This means computers can learn from their own experiences and make decisions with minimal human intervention.
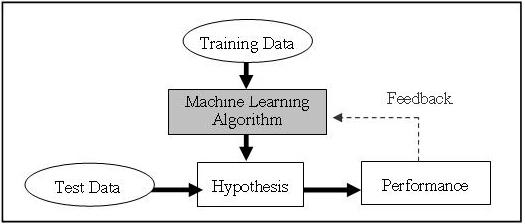
Fundamentally, a machine learning model is trained to minimize the gap between its predictions and the ground truth. The computer learns from sets of training data that are fed into a machine learning algorithm that identifies patterns and relationships in the data to make its predictions. The model adjusts its parameters and weights to decrease the error between its predictions and the true labels in the training data. This process repeats millions of times until arriving at an acceptable level of performance.
All of this might still sound highly abstract, but applications of machine learning can actually be very concrete. It has been driving success across many different industries and applications, ranging from Google’s language translation app to autonomous cars, fraud detection and portfolio management. A large language model (LLM) is a specific application of machine learning for natural language processing tasks that has risen in prominence as the technology underlying ChatGPT.
In light of widespread machine learning adoption, let’s clear up some misconceptions around the field and lay out potential business significance.
What Machine Learning Is Not
1. Machine learning is not human learning
A widespread misconception is that machine learning adequately represents the way humans learn.
According to a popular view, some of the most famous approaches to ML are directly inspired by the study of the human brain. We’re referring to deep learning, a subset of machine learning that uses layers of neural networks to learn complex patterns and representations from data. Amazon, Facebook, Google, Microsoft and Uber have all made substantial investments in deep learning systems, and it is undeniable that the current success of their data hungry algorithms contributed to the surge of interest in AI.
You’ve probably encountered statements that equate the functionality of a deep learning algorithm with that of the human brain. In order to explain how those algorithms work, the processes that underlie them are treated as analogous to signaling amongst a neural network in the brain.
We really like analogies, but this one is far from helpful. Here’s why: humans are typically able to learn from very few data points, whereas statistical learning thrives when plenty of data is available.
For example, consider handwritten character recognition. This is a real problem for children and adults, which they typically learn to solve after seeing just a few examples of each. In comparison, computers would typically require hundreds or thousands of training examples to achieve the same goal.
In a business context, this difference matters a great deal. The emergence of big data is undoubtedly driving new successful machine learning applications. However, the statistical learning underlying essential processes necessitates a significant amount of data — an amount that many organizations do not have.
So while it’s estimated that the average person generates 102 MB of data a day, many organizations won’t be able to leverage big data when applying machine learning to their use cases. Given the increasing amount of data needed to competitively utilize machine learning, companies should be ready to embrace new approaches to learn from small data as well.
2. Machine learning is not new
A second misconceptionis that machine learning is a nascent field. The definition presented earlier in this article was actually provided by Arthur Samuel in 1959. So there should be no doubt that the field of machine learning is far from new.
This also applies to deep learning. Given that the 2018 Turing Award went to the fathers of this popular approach to machine learning, one might think that it is a fairly new approach. Spoiler: It’s not.While the data that has enabled deep learning’s key successes has only recently become available, this does not hold for its algorithms. Deep learning can actually be seen as the latest wave of connectionism — a movement in cognitive science that hoped to explain intellectual abilities using artificial neural networks and had its Golden Age between 1980 and 1995.
The factor that distinguishes the past and present when it comes to deep learning is not its existence. Instead, it is the methodology employed, which is a function of the tools available. Recent breakthroughs in deep learning have largely been the result of turning away from human thought processes. And instead turning to the awesome data-mining power of supercomputers to grind out valuable connections and patterns without trying to make them understand what they are doing.Linking cutting-edge machine learning to its historical connectionist roots provides some interesting insights for organizations, as it sheds light on some of the limitations of deep learning applications. These will become evident by clearing up a third misconception about machine learning, which concerns the relationship between it, deep learning and AI.
3. Machine learning is not the same as AI or deep learning
As we have seen, deep learning is a subset of machine learning, which is in turn a subset of artificial intelligence. While these terms often seem to be used interchangeably, doing so would count as a serious mistake.
Deep learning relies on complex layers of artificial neural networks that give a deep learning model capabilities to perform tasks that a traditional machine learning model could not. Deep learning is credited with important advances today in health care, robotics, images and speech recognition, natural language processing and much more.
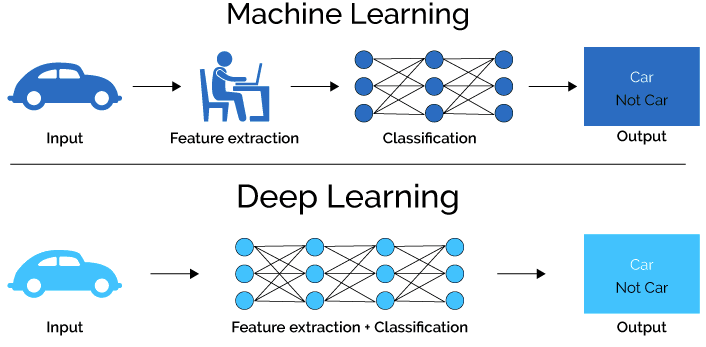
Machine learning is certainly a key component of AI — that much is true. However, conflating machine learning with AI would serve to eclipse everything else that AI has to offer.
As mentioned above, deep learning can be seen as the latest wave of connectionism which was popular in cognitive science and AI decades ago. Back then, connectionism was not the dominant paradigm.
Instead symbolic artificial intelligence dominated the scene and relied on strings representing real-world entities or concepts (aka Good, Old-Fashioned AI (GOFAI)). Today, in addition to symbolic artificial intelligence, artificial intelligence encompasses expert systems, natural language processing, robotics and computer vision.
No matter how important machine learning has become it is still only one part of a much more expansive AI landscape — and its influence in this space is not immutable.
4. Machine learning is not always automated or unsupervised
You may have heard of supervised and unsupervised learning, but there are many ways for machine learning to “understand” what humans want it to do. These techniques can include semi-supervised learning, where not all of the training data requires human interaction, and reinforcement learning.
With reinforcement learning, the algorithm learns by interacting with an environment and receiving feedback in the form of rewards. For example, Coveo has been exploring these approaches in applications like query refinement as a mobile-friendly alternative to classic faceted search.
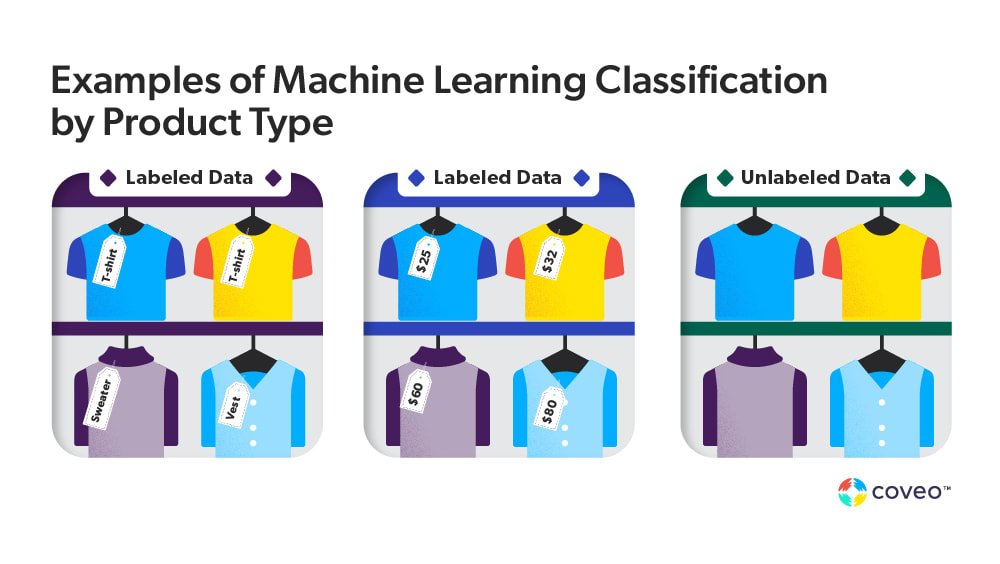
Supervised machine learning is particularly useful for applications that predict a relationship between an input and output, such as speech recognition or email filtering. Unsupervised machine learning, on the other hand, is commonly used for data analysis or clustering tasks such as fraud detection and customer segmentation.
The approach you choose for your organization will depend on the datasets you have available and the type of problem or goals you want to address with your machine learning model.
Understanding the Business Impact of Machine Learning
With generative AI the order of the day (after all, 72% of retail decision-makers are ready to implement this technology this year, according to a Google Cloud survey), it’s crucial that business leaders understand the full breadth of machine learning availability and capability to help create value for their business and where its limitations lie. Realizing what ML is, and is not, helps them to do just that.
We also acknowledge that different approaches bring different risks and opportunities. For instance, with old school symbolic AI, everything is visible, understandable and explainable, leading to what is called a ‘transparent box’ as opposed to the ‘black box’ created by machine learning and deep learning (link to explainable product discovery blog).
The long and short of it is that generative AI is not the only machine learning model that can help take your business to the next level. If you’re apprehensive about hallucinations (hi, Air Canada), contact an experienced provider like Coveo to get tailored insights for your unique situation.
Learn more about the AI and ML models Coveo can provide:

Dig Deeper
We’ve covered just a few ways machine learning and AI can help improve your customer’s digital experiences. But have you heard of total experience?
Watch this webinar to understand how a total experience platform can deliver on the promise of digital transformation.
