

The artificial intelligence bandwagon for search and recommendations has become crowded, with virtually every vendor touting its AI fortification. Naturally, this leads to one key question: does the AI actually work and how can you tell?
As ecommerce teams move beyond rules-based automation toward model-based systems like machine learning (ML) and deep learning, interpretability becomes a crucial factor. Does the model behave as expected? How do we know? And how does it impact product discovery and business outcomes?
You don’t want to rely on a model that seems to “work,” but in reality drains profits or recommends products that conflict with commercial priorities.It’s no longer a tradeoff between performance and transparency. In ecommerce, where product discovery is tightly linked to conversion and revenue, interpretability must go hand in hand with results. AI systems should be powerful and explainable.
In short, vendors that can combine automation with transparency will win in this evolving market.
In what follows, we unravel the intricate interplay between interpretability and ML, ensuring that you can understand the goal of the model, be able to control (configure) it, and then measure its performance. This convergence is what is desired to enhance the product discovery journey.
What Is Interpretable AI?
As AI takes on a growing number of critical tasks, interpretable and explainable AI are emerging as major trends. It’s no longer enough for a model to deliver results; we also need to understand how it works and what drives its outputs. Mistaking the true driver can be costly.
While interpretability is often emphasized in fields like healthcare and finance, it’s highly relevant to ecommerce too. Consider a product ranking model trained on shopper behavior. If newer products get more clicks -perhaps due to recency bias or promotional placement — the model might start favoring newness over true relevance. It may look effective in testing, but it’s optimizing the wrong signal. This kind of black-box behavior is risky. Ecommerce teams need visibility into why a product ranks — especially when KPIs like conversion rate or average order value are on the line.
Avoiding the Clever Hans Effect
This problem, also known as the Clever Hans problem, is well known. And yet that doesn’t make it any less worrying. In the late 19th century, a horse named Hans appeared to solve math problems by tapping his hoof. In reality, he was picking up on subtle, unconscious cues from his owner. He wasn’t doing math – just reacting to a pattern.

In the late 19th century, there was a horse in Germany named Hans whose owner thought he could perform math, including complex operations like interest calculation. The horse would tap his hooves on the ground to indicate an answer, and he would get it right.
Unfortunately, the horse wasn’t actually performing math. Instead he was taking cues from his owner’s subconscious facial expression. It turns out that the owner’s face would change when the horse neared the correct answer.
Machine learning models can fall into the same trap. They often latch onto correlations in the training data that appear meaningful but are ultimately misleading. A relevance model, for instance, might learn to favor newer content — not because it’s more relevant, but simply because newer documents were more often labeled as such during training.
This kind of shortcut-thinking is dangerous. The model isn’t actually understanding relevance — it’s just mimicking a pattern. And like Hans, it can look brilliant while missing the point entirely.
This isn’t a fringe issue. A study in Nature Communications showed that “Clever Hans” behaviors are surprisingly pervasive across deep learning systems. Which is why interpretability still matters — now more than ever.
Why Explainable AI Matters
So far, it all might sound pretty abstract. Yet, the problems of unexplainable, uninterpretable AI can be tethered to serious consequences. Interpretability plays a vital role in rooting out bias or assumptions in algorithms, for example.
In the financial sector, for example, lack of transparency in AI has led to discriminatory credit decisions, where borrowers from minority groups were denied loans or charged higher rates despite having similar qualifications. Without interpretability, it’s nearly impossible to detect these issues, especially in edge cases.
Other industries are already recognizing the need for explainable AI:
- Healthcare. Explainable AI systems that aid in patient diagnosis can help build trust between doctor and system, as the doctor can understand where and how the AI system reaches a diagnosis.
- Financial. Explainable AI is used to approve or deny financial claims such as loans or mortgage applications, as well as to detect financial fraud.
- Military. Military AI-based systems can predict weather, better routing, and autonomous vehicles.
- Autonomous vehicles. Explainable AI is used in autonomous vehicles to explain driving-based decisions, especially those that revolve around safety.
It’s clear that understanding why AI makes certain decisions is key to building trust — across sectors.
These risks extend to ecommerce as well. While the consequences may not be as dire, the stakes are still high. Poorly understood AI can:
- Violate brand agreements
- Surface irrelevant or confusing results
- Undermine customer trust and loyalty
According to Coveo’s 2025 Commerce Relevance Report:
- 59% of shoppers say they’ve encountered irrelevant results when searching on a retail website.
- 50% say they’ll abandon a site after just one poor search experience
In short, your AI could be quietly eroding revenue and loyalty, without you even realizing it.
In ecommerce, nobody wants to be the one who bet on the wrong AI. That’s why interpretability and understanding are essential, especially in the context of product discovery.
Interpretable AI in Product Discovery
Interpretability isn’t just relevant, it’s essential. In ecommerce, ML-driven personalization can introduce subtle biases or changes that are easy to miss but costly if left unchecked.
Take a marketplace selling apparel: a shopper searches for “Adidas,” but the system returns Nike or Puma – not out of intent, but because vector search groups them in the same semantic space. While technically “similar,” this may conflict with brand agreements or shopper expectations.
Or imagine you’re a merchandiser monitoring top queries. You notice that results for “running shoes” have changed and a product that used to rank #1 is now buried. Is it due to a new rule? A change in product popularity? Or has the model been retrained? Without transparency, you’re left guessing.
And from a model training perspective, suppose the AI was trained during a major sale period. The data might over-represent discount-driven behavior, causing the model to favor cheaper products — even outside of promo windows. It’s learning a pattern, not true shopper intent.
These aren’t edge cases – they’re everyday realities in ecommerce. That’s why understanding why the AI behaves the way it does is critical for maintaining control, trust, and business alignment..

AI Accuracy at the Cost of Interpretability?
Understanding ML models sounds ideal — but a common concern is whether there’s a trade-off between interpretability and performance.
This is especially relevant with the rise of powerful, but opaque, deep learning models. Simpler models like linear regression or decision trees are easy to explain, but often less accurate. In contrast, deep learning and vector-based models deliver stronger performance, but their inner workings are harder to unpack.
Take information retrieval: keyword search is highly explainable, but limited. Vector search is more effective at capturing intent, yet harder to justify why a specific result was shown.
The good news is that you don’t have to choose. It’s possible to achieve both performance and transparency — especially in product discovery — by following three key tenents: understanding the model’s purpose, configuring its behavior, and measuring its impact.

Tenant 1: Understanding the Purpose of the Model
A fundamental requirement is to comprehend the precise objectives of the ML model. Is it driven by the collective wisdom of the crowd, seeking optimization for profitability, or perhaps pursuing a different goal altogether? Understanding the AI’s intent is the cornerstone of effective interpretability.
For example, consider one of the models that Coveo makes available to customers as part of the Personalization-as-you-go suite. Intent aware product ranking is based on proprietary deep learning technology and the use of product vectors (or “product embeddings”). These multi-dimensional vectors are used to measure the distance between products so that affinities can be determined.
Imagine a three-dimensional space — or store — where products reside. Products that are closer together in attributions — will be closer together. These attributes might be category, color, size, brand. Digital shopping sessions can be thought of as a virtual “walk” in that space — with the added benefit of being automatically tailored for individual customers versus a generic setup for all.
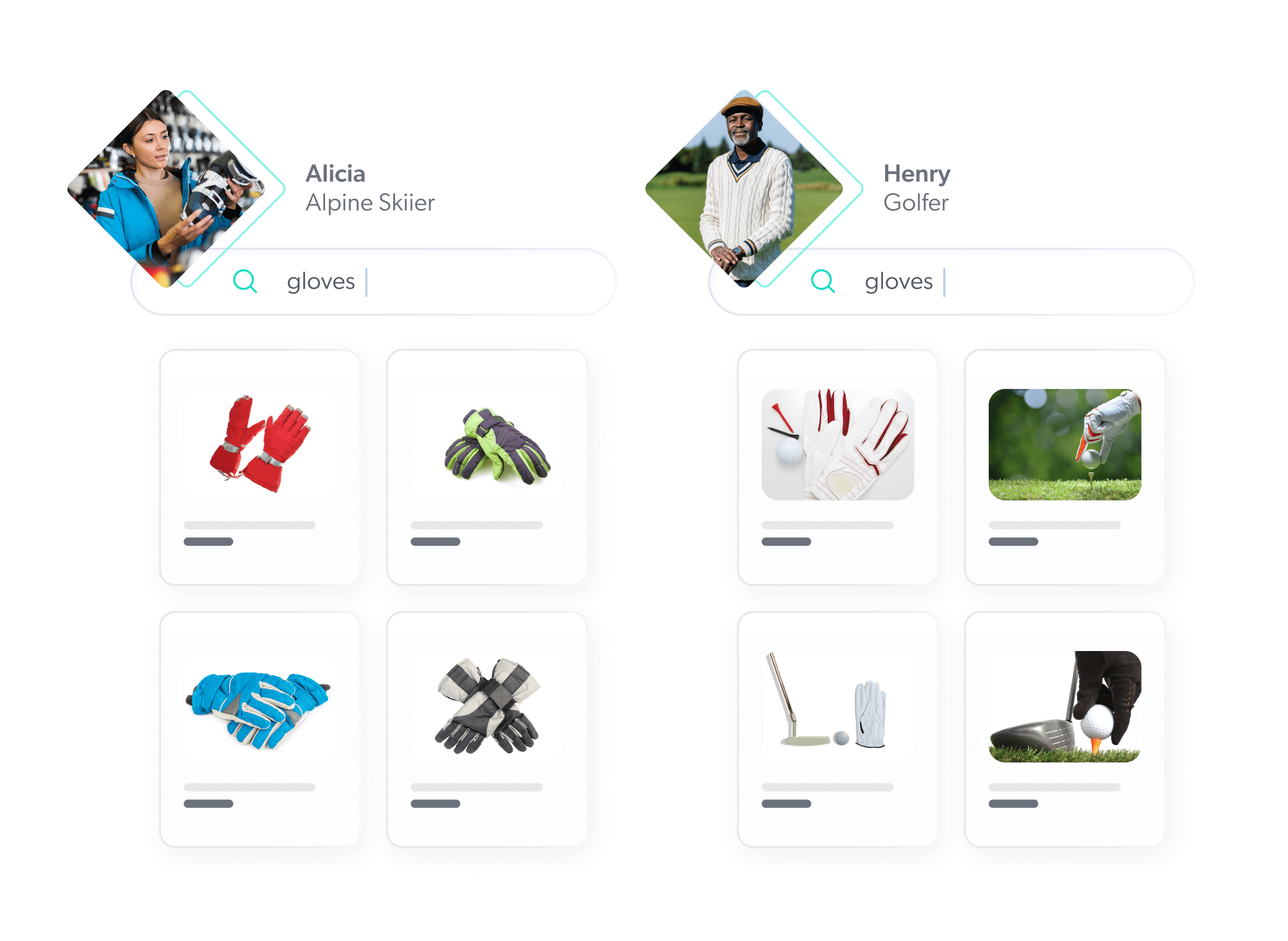
Of course, product embeddings are not inherently fully explainable on their own. We go into much greater detail in this piece on product embeddings and their relationships to recommendations.
But when our customers activate the Intent-aware Product Ranking ML model based on product embeddings, they have a clear understanding of what the model should be doing. Namely, to rerank products dynamically to show the most relevant based on the intent detected during the session.
Other vendors will refer to their models as optimizing for attractiveness. As usual attractiveness can be in the eye of the beholder — but often it means by popularity. But these ill-defined notions often leave business users and merchants confused and unable to really understand what the model is doing.
Tenant 2: Model Configuration
Further, a robust framework for model configuration and relevance settings is paramount. This entails the ability to curate the data and signals leveraged by the AI, granting users the power to shape the outcomes to align with specific preferences and objectives.
For instance, Coveo’s AI proprietary ML models are easily configurable. Consider the Automatic Relevance Tuning (ART) model, which is one of the most important Coveo ML models you will want to deploy. ART boosts products that are the most popular based on the current search query.
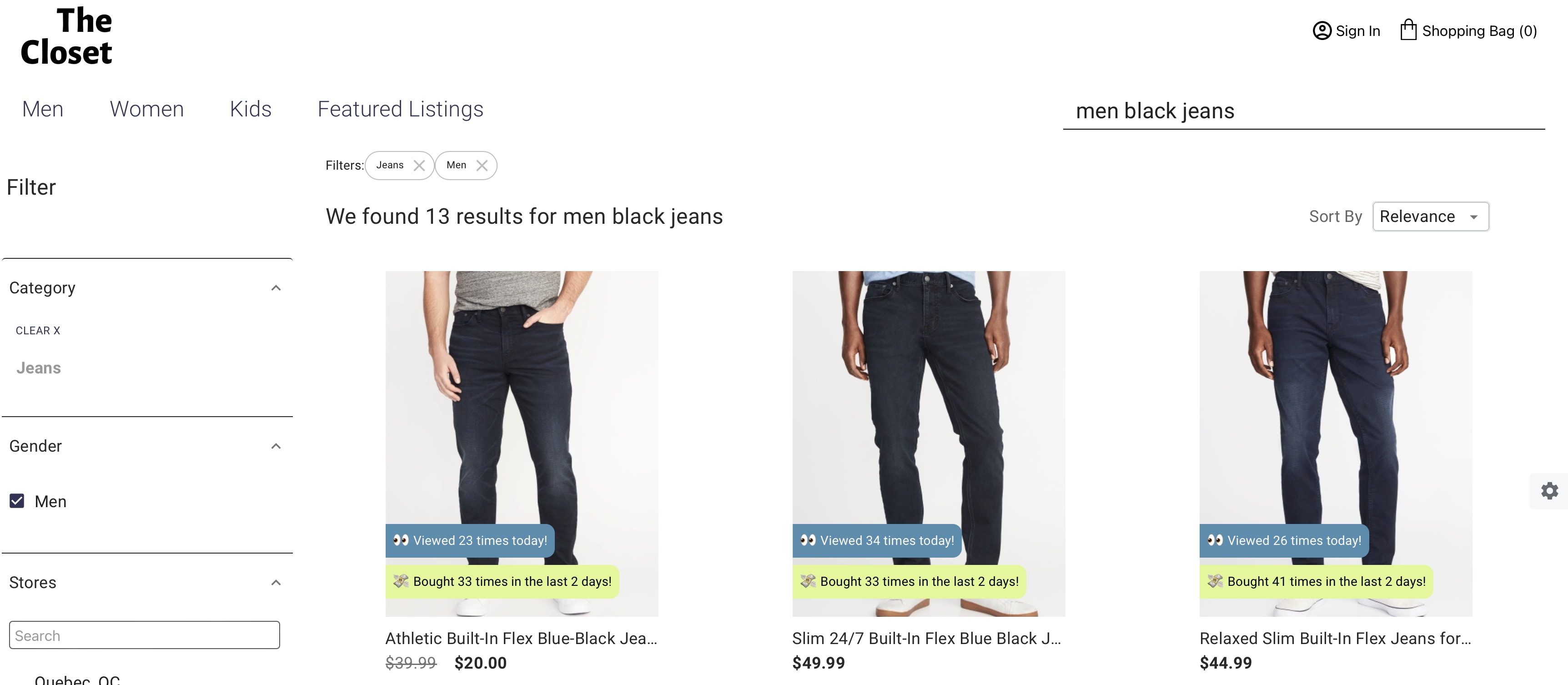
In the example shown above, the three first product listings are the most popular (via clicks and other user interactions) when querying for pants. The user context is being considered here to display womenswear. By automatically reordering, ART ensures that the top performing products are always presented first. Members with the required privileges can not only create, manage, and activate models in just a few clicks.
But they can also easily configure whether they want the ART model to automatically consider purchase and cart event data. Further, in the Learning interval section, they can change the default and recommended data period and building frequency.
Tenant 3: Model Measurement (Impact)
Further, interpretable product discovery should empower you to look inside algorithms, giving you confidence to make strategic decisions that elevate your KPIs. Extracting useful information from analytics platforms can be cumbersome and time consuming, so vendors should offer actionable insights specific to product discovery.
At Coveo, for example, we’re committed to helping merchandisers access the best information to help inform their decision making.

More precisely, understanding why a product is ranked in a specific position is critical to gaining confidence and trust in machine learning. Coveo’s ranking visibility lets business users understand the impact of AI on the experiences shoppers receive with rankings controls.
Final Thoughts
You don’t have to choose between AI performance and interpretability. With the right platform, you can achieve both:
- AI models that drive real business outcomes
- Clear insight into how they work
- Control and customization for business teams
Partnering with a trusted vendor in AI-powered product discovery helps you deliver great customer experiences while maintaining the transparency and control needed to build trust and navigate the complexities of AI effectively.