

Search relevance refers to a search engine’s ability to provide the most significant results to address the searcher’s needs and satisfy their intent.
Creeping in steadily over the years, search relevance now represents a ubiquitous element in our daily interactions with applications and websites. Despite this, delivering search relevance is also becoming harder and harder.
Because of digital giants like Google, Amazon, or Netflix, we now expect relevant results that address our information needs everywhere, whether we are shopping on our favorite brand’s website or looking for information within our company’s information systems.
What’s their secret? Here’s how you can leverage machine learning to drive search relevance and finally meet users’ expectations by enabling what was impossible before: genuine optimization of relevant results on an individual level, at scale.
From Mooers’ Law to Moore’s Law
Because search is now everywhere, search relevance is critical.
In 1959, Calvin Mooers, a pioneer in the early history of computer technology development, coined Mooers’s law and its corollary:
An information retrieval system will tend not to be used whenever it is more painful and troublesome for a customer to have information than for him not to have it.
In other words, the more difficult and time consuming a search is, the less likely it is that we will use it. Whenever we search, search relevance is what we expect.
But now a second principle enters the fray, namely Moore’s law: once you experience something better, you’re never going to go back. When a shopper goes to Wayfair and gets a relevant recommendation that leads to a quick purchase, that experience becomes their shopping expectation. When a customer goes to Dell or Salesforce.com and gets highly relevant support content, that experience becomes the norm for customer service.
Every company should therefore make “relevance” the performance bar to jump over.
Relevance Outside the Search Box
If you have to ask what jazz is, you’ll never know.
– Louis Armstrong
We also expect relevance even when we’re not using a search box.
Within the field of information retrieval, search engines and recommendation engines are the two most popular technologies used to satisfy users’ information needs. The key differentiator is that a search engine matches a user’s explicitly entered search query, whereas a recommendation engine instead recommends what a user may want to see next based on known or inferred knowledge.
Recommendations can be exceptional drivers of content relevance, helping users encounter items they weren’t even aware of. Looking for an example? Here’s one you may already know, as this was presented by Chris Anderson in his book The Long Tail.
In 1988, a British mountain climber named Joe Simpson wrote a book called Touching the Void, an account of a near death experience in the Peruvian Andes. When the book got good reviews but only a modest success, it was soon forgotten. A decade later, Jon Krakauer wrote Into Thin Air, another book about a mountain climbing tragedy, which became a publishing sensation. Suddenly Touching the Void started to sell again.
What happened? In short, Amazon.com’s recommendations.
Amazon noted patterns in buying behavior and suggested that readers who liked Into Thin Air would also like Touching the Void. People took the suggestion, agreed, and drove more sales.

This is a powerful illustration of how recommendations can help deliver highly relevant results users weren’t even aware of.
Search and Recommendations Best When Combined
So, whether I’m inputting query terms or not, the expectation of relevance is always there. It’s also important to keep in mind that while many companies think of search engines and recommendation systems as separate technologies solving different use cases, they are best when combined to provide users with relevance.
Consider the case of zero-result recommendations. Whatever the reason for a user reaching a zero results page, it’s critical to provide guidance or content on the page. Though users may not find the exact content they were searching for, zero-result recommendations are an effective way of pointing them towards other items they may be interested in.
The key point, whether you’re searching by actively entering queries or instead just consuming streams of content, topical relevance is expected and needed.
The Fundamentals of Search Relevance
Search is a wicked problem of terrific consequence… the defining element of user experience.
– Peter Morville
We expect to find relevance everywhere. Regrettably, relevance is not what search engines most frequently deliver.
For example, in a recent survey we found that “workers surveyed spend an average of 2.5 hours a day searching for information, in part because 41% of the information provided to them is irrelevant to their job role.”
And this isn’t just about search in the workplace. We also found that 90% of consumers surveyed expect online shopping experiences to be equal to or better than in-store, but half say they sometimes-to-always experience a problem when shopping online. Regrettably, this confirms older findings from the Baymard Institute that show how 29% of sites won’t yield useful results if users misspell just a single character in a product title and 61% of ecommerce sites don’t have proper synonym support.
As shown above, delivering on search relevance and closing the expectation vs delivery gap turns out to be quite tough. Despite the intuitiveness of the concept, there are a number of capabilities that are required to meet relevance expectations:
- Contextual & Personalized: search should consider user context, keyword context, and domain context to understand user intent. For instance, relevance search should point employees towards the best knowledge to consult and the right people to connect with, automatically tuning the relevance of recommendations based on location, department, or other important attributes.
- Conversational: search should let users interact in natural language and guide them through a discovery process while learning and remembering relevant new information along the way. In an ecommerce setting, for example, users should be able to find products irrespective of how complex and long their queries are.
Importantly, search should also empower users to ask questions and easily find answers. Question answering (QA) is a complex natural language processing task where a search engine directly answers a question posed by a user, presented in an answer box at the top of the search result page. An example of this is Coveo’s Smart Snippets, which is a preview of the section most relevant to the given query term. - Intelligent & Proactive: search should be able to deliver predictive query suggestions, anticipating what users mean (through spelling correction, intent classification, conceptual searching, etc.) to provide the right answers at the right time—and to be constantly getting smarter.

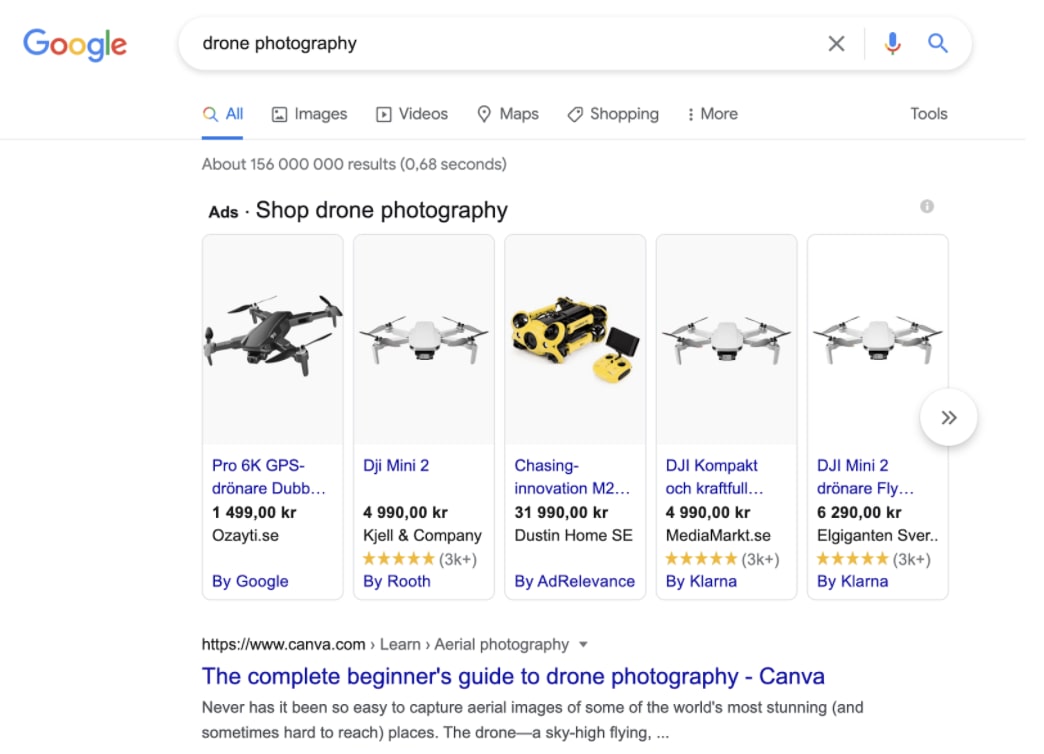
- Unified: search should provide accurate answers by incorporating multiple content sources, work seamlessly with recommendations, and aggregate a wide range of content (e.g., documents, products, blogs, images, videos, etc.) in a search result page to create a relevant, seamless search experience. For example, for “drone photography,” Google knows that useful content may not only include products, but also blog posts, videos, or images.
Leverage Machine Learning to Drive Relevance
What I’ve described up to this point is a tall order, especially for even a team of human search engineers working around the clock. To aspire to the heights set by industry—leading digital giants, businesses need the ability to consume and utilize a huge amount of contextual customer data, and respond appropriately.
This is possible only with AI technology and powerful machine learning capabilities.
For example, if I’m searching for “gloves,” there’s nothing in the search term “gloves” that specifies whether I am interested in golf gloves, rather than, say, winter gloves. Relevant, AI-powered search can leverage multiple types of data (such as onsite customer behavior and the fact that I’ve been browsing through golf pants) to deliver the most relevant search results.
So, if you were wondering how Google can answer your questions no matter how complex they are or how music-streaming services such as Spotify find songs that you like, that should be clearer by now. They haven’t mastered relevance overnight; instead, they’ve systematically perfected machine learning models to drive and deliver relevance.
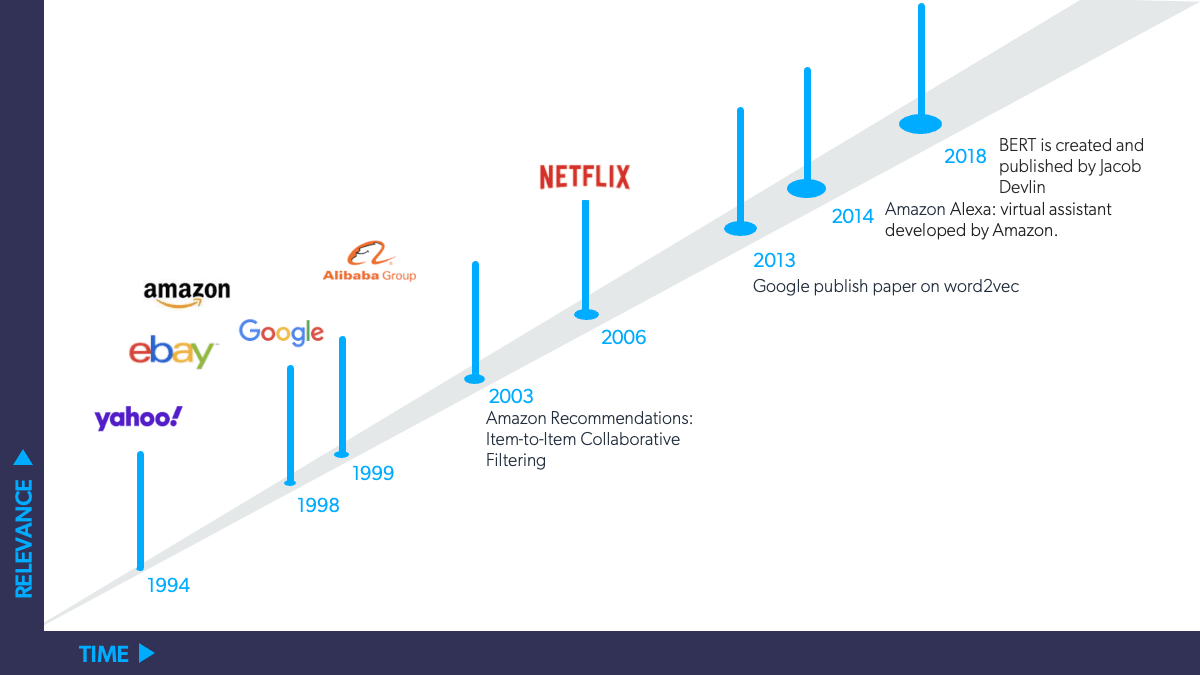
A machine learning algorithm enables the impossible: genuine optimization of results on an individual level at scale. Digital giants invest in AI research and constantly develop and test cutting-edge algorithms to push boundaries of innovation, publishing in top outlets for artificial intelligence.
For instance, if you find yourself impressed by the relevance of Amazon’s product recommendations, that’s because of their proven technology. They originally presented it in their 2003 paper called “Amazon.com Recommendations: Item-to-Item Collaborative Filtering,” but has continued to evolve and improve over the years.
Just considering the context of ecommerce, if we look at the number of papers published in top AI peer-reviewed outlets, you will find the usual suspects (e.g. Amazon, Microsoft, Spotify) with the only exception of Coveo.
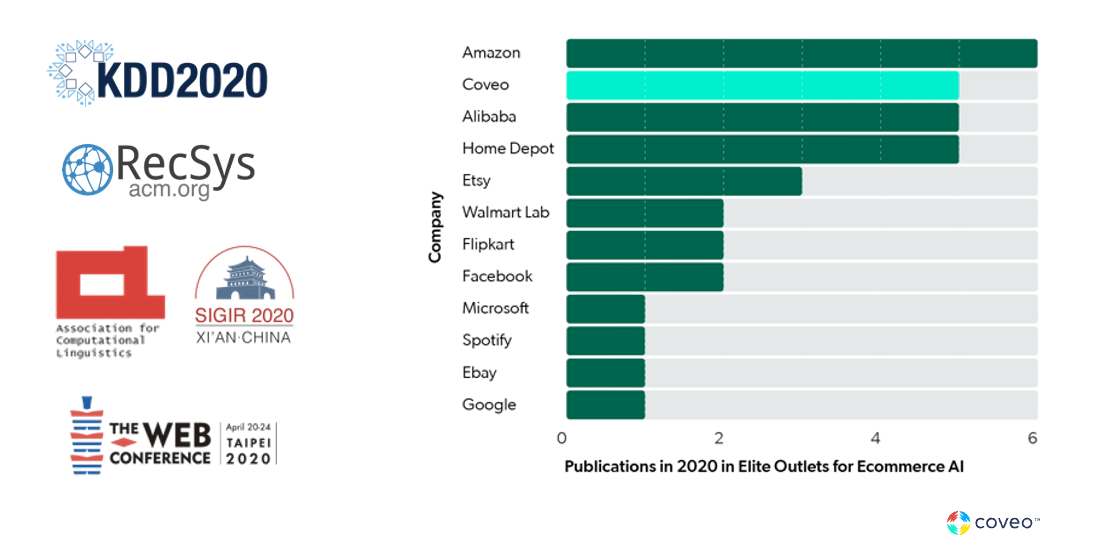
The illustration above nicely shows how companies that are successfully delivering on search relevancy are those that keep pushing the envelope in advancing ML.
Pick the Right Search Vendor to Deliver on Relevance
Companies like Amazon have been researching and developing cutting-edge technologies for relevance since their early days and have hundreds of search engineers to ensure their search experience is best-in-class.
Digital players who wish to deliver the most relevant experiences to their employees, users, and shoppers shouldn’t despair. You don’t have to develop that technology in-house, nor do you need to hire a plethora of PhDs and data scientists to close the expectation vs delivery gap.
But how can you choose the right site search solution for you?
Selecting an established and recognized industry leader is the first step. For example, Coveo has been consistently recognized as one of the leading solutions providers by Gartner and Forrester.
