

Information retrieval is the process of accessing data resources. Usually documents or other unstructured data for the purpose of sharing knowledge. More specifically, an information retrieval system provides an interface between users and large data repositories – especially textual repositories.
Information retrieval techniques have been part of computer science for decades. But in the internet age, it’s even more important as public search engines are key in connecting people to information. Information retrieval applications are also essential to modern digital enterprises; it’s a crucial aspect of retrieval augmented generation, which helps ground enterprise generative AI.
Today, information retrieval often augments artificial intelligence, or vice versa. This powerful combination provides us with the fast-as-lightning digital experiences we’ve come to expect.
Relevant reading: GenAI & 10 AI Models Transforming EX + CX
What Is an Information Retrieval System?
Information retrieval is the process of finding relevant information from a collection of documents. Humans have been creating systems to organize and retrieve information long before the digital age.
A shift from physical to digital information retrieval emerged with the introduction of computers in the mid-20th century. The first instances of computer-based searching systems appeared in the 1940s with information retrieval capabilities growing alongside advances in processor speed and storage.
The term “information retrieval” was coined in 1950 in a paper presented by computer scientist Calvin Mooers. During this period, information retrieval evolved from manual indexing and searching for information to automated systems.
The 3 Parts of Any Information Retrieval System
Information retrieval systems act as a bridge between people and data repositories. At a high-level, an information retrieval system includes three main aspects:
- Indexing: The process of indexing the source data, compiling metadata, and unifying disparate stores.
- Query: Providing a UI that allows for expressing queries against the repositories. In modern systems, this usually involves some form of natural language processing (NLP).
- Display: Presenting the retrieved document(s) with some degree of metadata. Information retrieval’s main feature is to rank results based on relevance. It also supports results tuning based on how well they serve a user query.
ASIDE: A corpus is a repository of text documents, meaning a body of works. A corpora is the plural version.
Historically, information retrieval, or text retrieval, grew out of the challenge in finding relevant results when confronted with large amounts of written data. Consider the printed book library. An enormous amount of useful data is present in the library’s repository. How can an interested party identify what results are relevant to their needs? The Dewey Decimal System was a response to that problem. As computers and software became more powerful, they radically improved this process.
Traditionally, information retrieval is associated with unstructured or semi-structured forms. However, modern information retrieval must often deal with a heterogeneous set of data sources including structured sources like relational databases.
Repository Architecture
The first step in an information retrieval system implementation is to count the number of repositories. Then devise an architecture that can address them in a unified way. To index content for effective search at query time, a system must be able to access said source material.
This involves orchestrating the necessary network and authorization/authentication components. An information retrieval system as an architectural component that offers a UI while consuming data from one or more repositories.
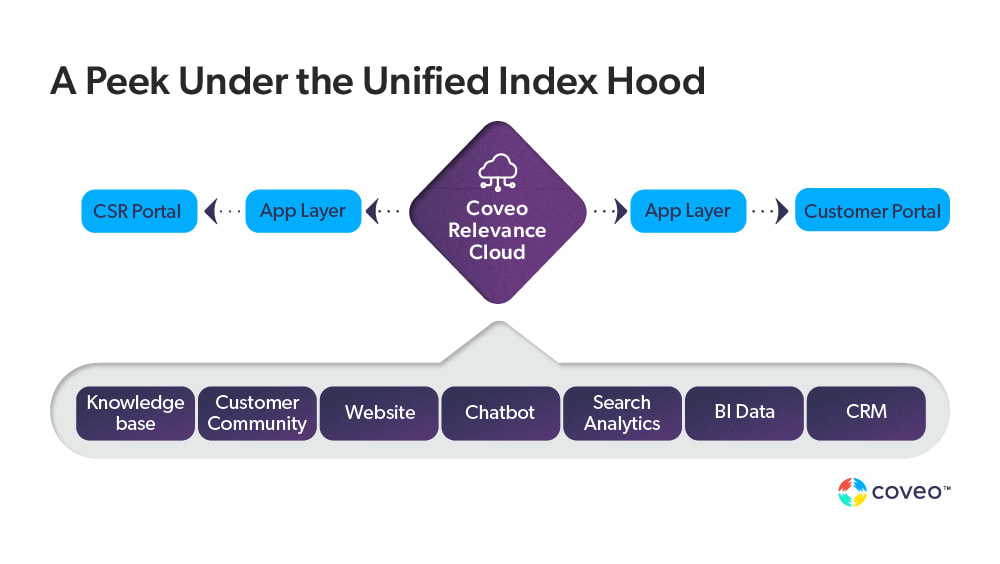
Once the system can access content, the challenge becomes compiling metadata for effective search. This area has undergone an immense amount of research over the years. A corresponding abundance of approaches to compiling metadata exist — with further innovation still to come. Source data will provide guidance in how best to apply indexing. How a system views data is known as an information model.
When adding a source, you can modify the items that you want indexed. Or you can modify the item extensions as a means to strategize your content.
Machine Learning and IR Models
A struggle of querying unstructured data is that humans find different ways to say the things in different contexts. Metadata was long the go-to for adding more meaning to understand intent — but metadata gets stale. A more scalable method is through the use of artificial Intelligence and machine learning.
Let’s look at the main styles or modes of modeling data in an IR system. These are not rigidly isolated approaches and specific applications may use techniques from several of them.
Set theory and boolean models
The simplest form of data modeling is set theory, which is to view documents and queries as buckets of words. This approach results in a query capability in the form of typical Boolean expressions. It’s still common and has crossover with the familiar form of formal query language, SQL (structured query language). Boolean set theoretical models can be considered the classical approach.
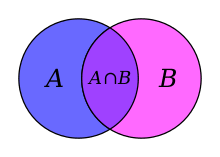
Fuzzy set theory is a refinement often used in IR systems that lends itself to ranking of documents by relevance. Instead of a hard-and-fast match/no-match, fuzzy logic allows for a weighted ranking to how well a document matches a query.
Algebraic models
Algebraic modeling of data uses equations for modeling data and queries against it. A common example is vector space modeling as in the image below.
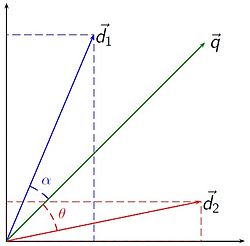
In the above image, q is the query and d1 and d2 are documents in the repository. The idea is that whatever terms are in the query can be expressed as a vector, comparable to the term vectors found in the documents as simple angle comparisons.
This core idea has been elaborated upon in several ways, for example in generalized vector space. The manner in which documents are considered as to their weighting of word occurence is also subject to various refinements. For example, using occurrence locality (specific words being near each other) to improve relatedness of words versus simple frequency counting.
Probabilistic Models
Probabilistic models predict how likely a given document is relevant to a given query. Such models are good at dealing with approximations in the face of incomplete evidence. There are several approaches that fall into this category and it continues to be an area of active research. Probability is the most powerful model but also the most complex, mathematically and in terms of applying the math to the problem domain.
Using statistics to model document relevance is helpful in dealing with the uncertainty of indexing huge amounts of data. Also, probability works by assigning relevance weight along a relative scale that is a natural fit for results ranking. Even further, probability modeling has synergy with machine learning techniques. Therefore, it lends itself to using AI in information retrieval systems.
One example of this probabilistic model method is the Bayesian network. This is a form of inference network that describes term distribution in a directed acyclic graph. The nodes represent statements about the documents and edges of the graph represent conditional dependencies between them. This network is then used to calculate the probability of what documents contain relevant information for a given query.
This type of model can use both prior experience and given evidence to describe the interrelation of term occurrence in a document to deduce a probability. A simple visualization is given in the figure below.
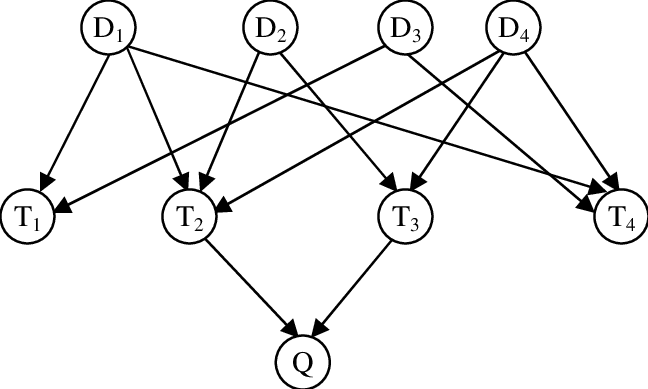
In the figure, the probability of documents D* is calculated by considering the weight of terms T* as they apply to query Q. In document text analysis, this includes factors like word frequency, proximity, and their importance to a document’s overall meaning. This is a simplification as the interrelations of terms and their proximity is also considered in real world systems.
Term Interdependence
A higher order consideration in information modeling is term interdependence . This is the way the model incorporates the significance of term relationships. As an example, counting how many times the word “dog” appears yields less nuance than assigning a value to “dog days of summer”. The latter system can perhaps arrive at the correct understanding that the document is dealing with weather rather than pets.
There are two approaches to term interdependence: information model (immanent mode) or existing without (transcendent mode). To identify which is used, ask yourself: “does the application of interdependence reside within the model or is it applied by an external agency?”
That external agency could be human beings or AI/machine learning (or some combination). In this way, the information retrieval model is making inferences about how words and phrases relate within the corpus and an intelligence outside the system is training it to be more effective.
Information Retrieval and Natural Language Processing (NLP)
NLP is concerned with making software effective in handling natural human language. It plays an important role in information retrieval, as it divines semantic meaning and better understand higher-order patterns across document sets. In search, NLP helps identify user intent, which helps ensure search results meet what a user is actually looking for rather than just a string of keywords.
Information retrieval and NLP are naturally mutually influential fields that also involve machine learning (ML). ML can devise systems that can better evolve towards information understanding at the semantic level.
Information Retrieval vs Data Querying
Another useful way to think about information retrieval is in contrast to querying a formal system like a relational database with structured query language (SQL). SQL databases offer a consistent, structured way to model data that allows for expressively querying with a degree of after-the-fact flexibility.
For decades, relational database management systems (RDBMS) have been the flagship store for data-driven applications, with ideas in the NoSQL space like document stores, key-value and graph databases relaxing or modifying certain structural aspects of the model in recent years.
The main difference to devoted data stores systems like RDBMS and NoSQL stores is the rigor of the data model and the query result precision. Information retrieval is focused on addressing diverse and inconsistently structured artifacts and figuring out how well they represent the desired aim of the queries. Compare this to the more strictly match/no-match way most database queries work.
Databases are very good at telling you exactly which tables or documents hold an actual reference to “pets,” but require something else to figure out which ones might be relevant to a query about the popularity of different pets.
Relevant reading: Improving Customer Experience with Advanced Information Retrieval
Why Information Retrieval Systems Are Critical
Information retrieval systems address several classes of hard problems. These problems are of the data scope, data fragmentation and data meaning types, involving architectural considerations and issues of scale. When enterprises and organizations look at who needs what information and where the information resides, the difficulty is bringing the people and the data together in the most effective way. Information retrieval is the main systems-side response to that challenge.
Information retrieval is a core component of knowledge management systems. Put another way, when an enterprise is capturing and storing data in large and heterogenous ways, information retrieval systems step in to make that data more useful..
While it’s fundamental to all computer systems and the organizations that rely on them, information retrieval has taken on a central importance in the context of web-oriented applications, e.g, for a variety of applications – corporate intranet, customer service, technical support, compliance and governance.
Information retrieval devises human-machine interfaces that improve the ability of people to find data, influencing data architecture and persistence models. Because the ability to access data effectively affects every digital business process, information retrieval is a core consideration in modern digital business strategy.
Relevant reading: Information Retrieval Trends: What Does The Future Look Like For Search?







