
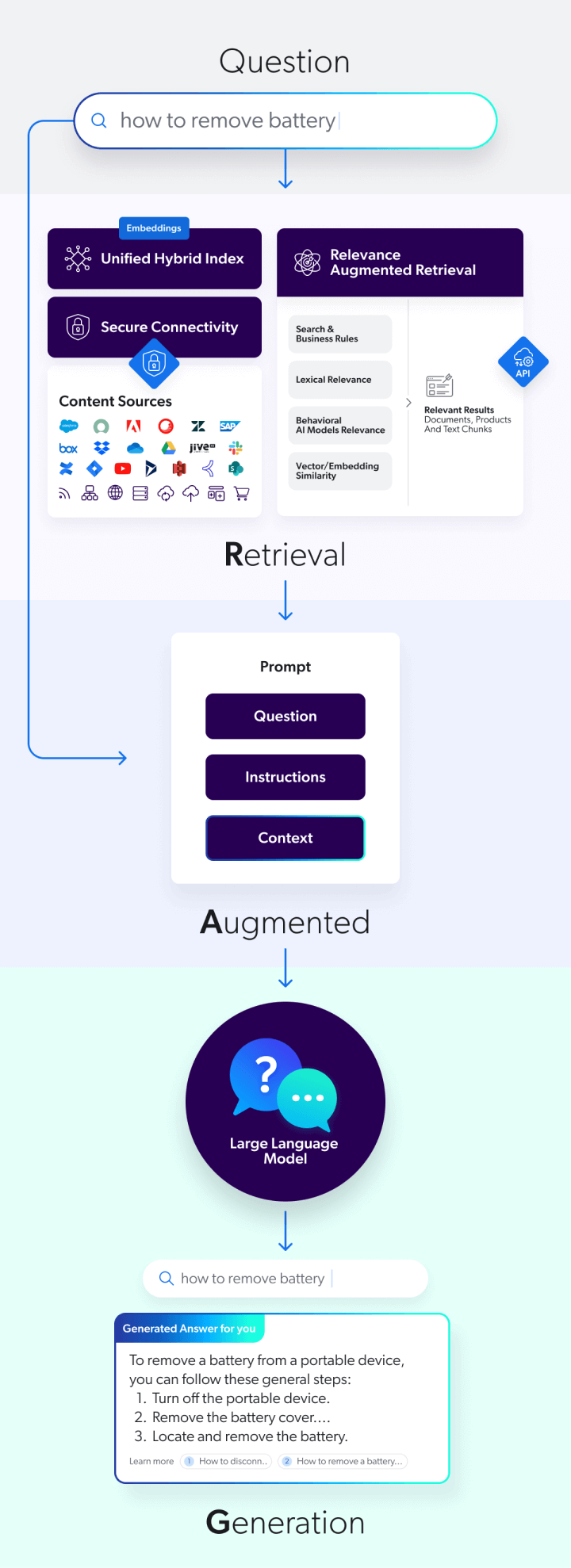
Unter Informationsabruf versteht man den Prozess, relevante Informationen aus einer Sammlung von Ressourcen, beispielsweise Dokumenten, in Form unstrukturierter oder halbstrukturierter Daten zu gewinnen. Ein leistungsfähiges Retrieval-System unterstützt die Identifizierung relevanter Textabschnitte für Anwendungen mit generativer KI.
Informationsabrufsysteme (oder IR-Systeme), allgemein als Suchplattformen bezeichnet, bilden eine Schnittstelle zwischen Benutzern und den Informationen in Daten-Repositorys. Sie ermöglichen es uns, die riesigen Informationsmengen, denen wir täglich ausgesetzt sind, zu verstehen. IR-Systeme begegnen uns in Form von Websuchmaschinen, virtuellen Assistenten und beim Sortieren von E-Mails.
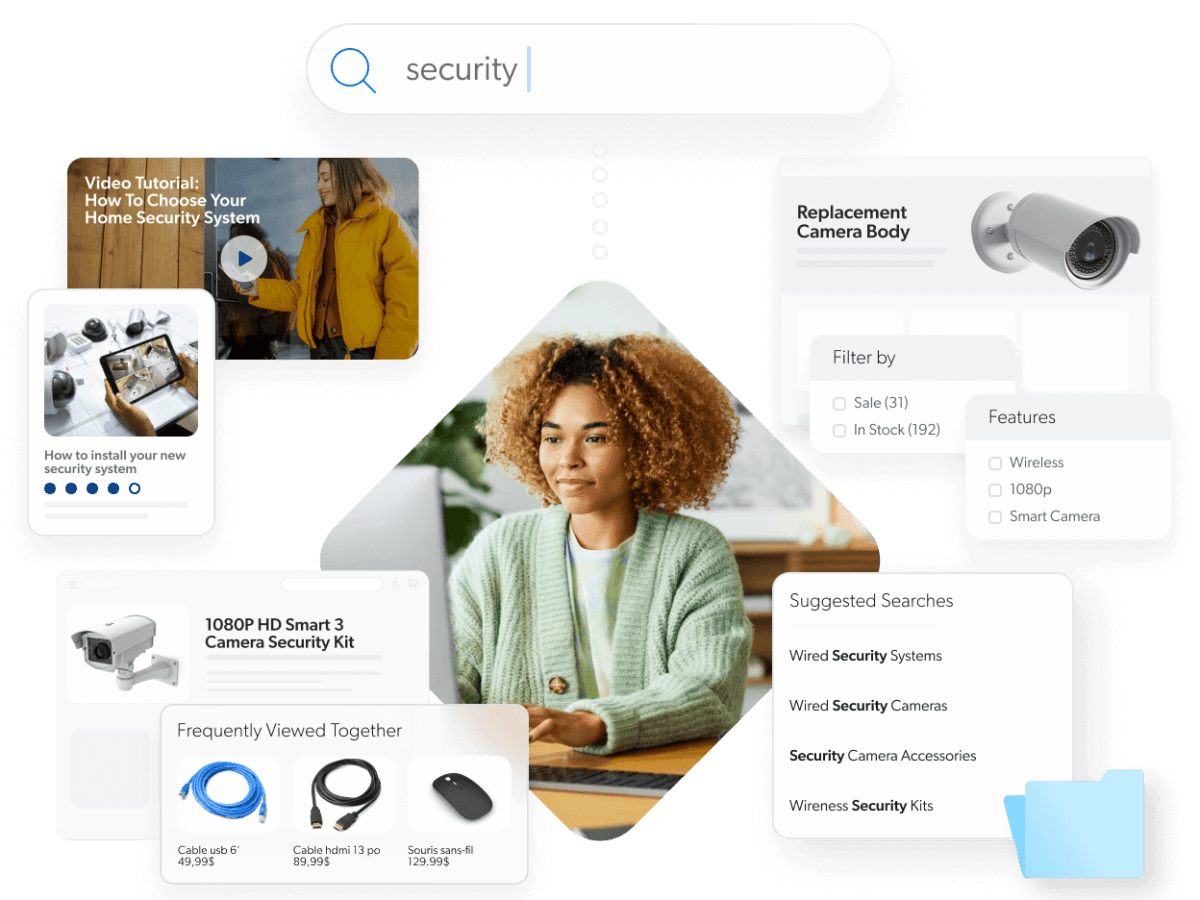
Der Informationsabruf bietet eine Schnittstelle, mit der Menschen auf einer Maschine gespeicherte Daten abrufen können. Wenn Unternehmen Daten an verschiedene Zielgruppen – Interessenten, Mitarbeiter, Kunden, Partner usw. – liefern müssen, kann es schwierig sein, die Lücke zwischen dem Speicherort der Daten und dem Ort, an dem Endbenutzer darauf zugreifen können, zu schließen.
Der Informationsabruf ist ein zentraler Bestandteil von Wissensmanagementsystemen. Institutionelles Wissen ist wertvoll, aber kaum nutzbar, wenn es im Kopf einer einzelnen Person steckt. Wenn sie dokumentiert und organisiert sind, macht der Informationsabruf diese Daten nützlicher.

Wenn Menschen Informationen abrufen, sind die gesuchten Informationen häufig in PDF-, PowerPoint- oder Word-Dokumenten usw. vergraben – im Fachjargon „unstrukturierter Inhalt“ – also Informationen, die sich nicht sinnvoll in Tabellen oder Zeilen abbilden lassen.
Diese Art des Informationsabrufs – das Verbinden amorpher Dokumente mit unscharfen Konzepten – ist am schwierigsten zu lösen.
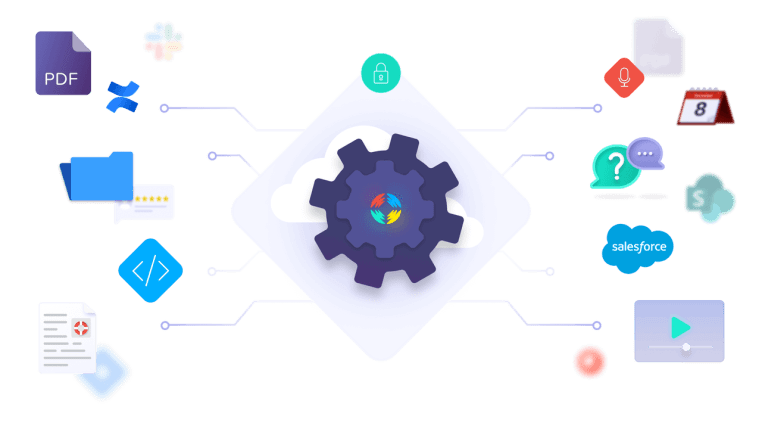
Werfen wir einen Blick auf die heute am häufigsten verwendeten Informationsabruftechniken, ihre Stärken und Grenzen sowie ihre Anwendungen in der Praxis. Informationsabrufsysteme nutzen häufig eine Kombination dieser Techniken, um die Genauigkeit und Effizienz zu verbessern.
Um Inhalte in Ihrem gesamten Unternehmen mithilfe des Informationsabrufs zu durchsuchen, müssen Sie eine Verbindung zu Datenquellen herstellen. Und dies geschieht über Konnektoren, die es Ihnen ermöglichen, sich über einen Crawler oder Push-Mechanismus mit einer Inhaltsquelle zu verbinden.
Ein Crawler durchsucht alle verbundenen Quellen, um Daten zu extrahieren, unabhängig davon, ob diese Daten strukturiert oder unstrukturiert sind.
Eine Push-API stellt Dienste zum Senden von Elementen und ihren Berechtigungsmodellen an eine Quelle und von Sicherheitsidentitäten an einen Sicherheitsidentitätsanbieter bereit, anstatt diese Inhalte von Standard-Crawlern von Coveo übernehmen zu lassen.
Das Ranking im Informationsabruf kann so einfach sein wie das Zählen, wie oft eine bestimmte Suchanfrage oder ein Keyword in den gefundenen Daten vorkommt. Für ein anspruchsvolleres Ranking muss ein Relevanzwert auf der Grundlage zahlreicher Faktoren erstellt und diese Ergebnisse dann in absteigender Reihenfolge angezeigt werden.
Maschinelles Lernen
Um modernen Erwartungen gerecht zu werden, sollten Information-Retrieval-Systeme künstliche Intelligenz und maschinelles Lernen nutzen, um Inhalte so abzubilden, dass die Maschine erkennt, dass ein PDF zum Beispiel zum Thema „Unified Search“ einem Dokument zum Thema „Index-Time Merging“ ähnelt. Dies verbessert die Suchergebnisse, sodass die relevantesten Inhalte immer ganz oben angezeigt werden.
Zu den maschinellen Lernmodellen von Coveo gehören:Rollenbasierte Zugriffskontrollen
Es ist von entscheidender Bedeutung, dass ein einheitlicher Index die Berechtigungen eines Benutzers zum Zugriff auf Informationen verstehen kann. Moderne Enterprise-Suchsoftware verwendet Zugriffskontrollen, um Sicherheitsrichtlinien für jeden Unternehmensbenutzer durchzusetzen und so die Sicherheitskonformität innerhalb der Suchfunktion zu gewährleisten.
Benutzerabsicht
Durch die Erfassung jeder Benutzeraktion können moderne Informationsabrufplattformen die Absicht ermitteln. Durch die Berücksichtigung personenbezogener Daten (einschließlich geografischer Standort) kann die Plattform eine Suchanfrage mit zugeordneten Inhalten abgleichen und die relevantesten Ergebnisse abrufen.
Maschinelles Lernen und Deep-Learning-Algorithmen haben jedem Benutzer einer Informationsabrufplattform eine neue Ebene der Relevanzanalyse ermöglicht. Jedes Ergebnis ist individuell auf den einzelnen Benutzer zugeschnitten.
Ebenso werden Funktionen zum Abrufen von Informationen für externe Anwendungen wie die Websuche und die App-Suche genutzt. Eine Informationsabrufplattform sollte alle diese Anwendungsfälle sowohl intern als auch extern im Unternehmen unterstützen.
Headless
Da Informationen von einer immer größeren Zahl von Geräten aus zugänglich sein müssen, bietet Ihnen ein Headless-Framework die ultimative Kontrolle und Flexibilität über Ihre Schnittstelle zum Informationsabruf. Die Coveo-Plattform fungiert als Zwischenschicht für Anwendungen und öffnet eine Kommunikationslinie zwischen den UI-Elementen und Ihrem Index. ICH
Informationsabruf als Service
Die Coveo-Plattform ist eine unternehmensweite, mandantenfähige SaaS/PaaS-Lösung, die eine einheitliche, skalierbare und sichere Möglichkeit bietet, in vielen Unternehmenssystemen nach kontextrelevanten Inhalten zu suchen.
Wie finde ich das beste Informationsabrufsystem?
Branchenanalysten bewerten regelmäßig Anbieter von Informationsabrufsystemen. Gartner hat die Kategorie „Insight Engine“, während Forrester sie als „Cognitive Search“ bezeichnet.
Im Gegensatz zu Elastic Enterprise Search, Solr, Amazon OpenSearch oder sogar Amazon Kendra, bei denen Entwickler den Informationsabruf von Grund auf neu erstellen müssen, enthält die Coveo Platform gehostete Suchseitenvorlagen, mit denen Sie sofort loslegen können. Sie können schnell sehen, wie ein typisches Informationsabrufergebnis für einen Benutzer aussieht.
