
Years ago, if an employee at a large organization needed to find a piece of data on one of the organization’s information sources, their search process would look like this.
First, they would need to try and remember which data source the information they were looking for could be found in. Then they would have to log into each database independently and search each one until they found the relevant information. Needless to say, this process was very inefficient. Not only was it time-consuming, but it also required users to remember the passwords and logins for multiple platforms.
All that changed when federated search came along.
What Is Federated Search?
A federated search tool allows users to send a single search query to multiple data sources from a single search interface. No more jumping between data sources and trying to remember the login info for each one. No more wasting your time trying to find a needle in one of the many haystacks at your disposal. The system does it for you.
Federated search technology has become the foundation of enterprise search, and for a good reason: it completely transformed the organizational approach to information retrieval and knowledge management.
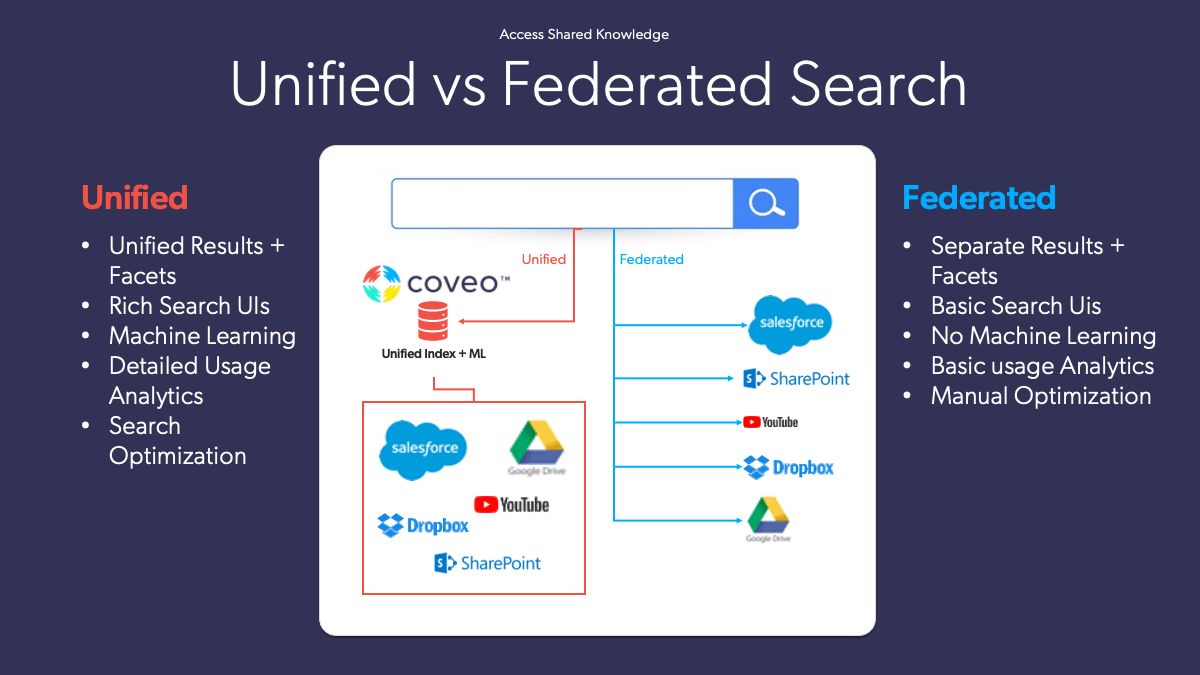
For a while, as many organizations grappled with content across multiple sources – cloud-based and on-prem and ecosystems of record – a federated search interface seemed like the perfect solution.
However, the world has changed drastically in recent years, transforming how we interact in the digital space. People spend more time on screens than ever, which makes it essential that their digital interactions be as effective as possible.
What the Covid-19 “pause” and the aftermath of the pandemic first revealed, and what the recent advances in artificial intelligence have confirmed, is that federated search, advanced as it is, no longer meets users’ expectations for digital experiences.
Let’s see why.
How Does Federated Search Work?
Federated search retrieves information from different content sources via a search application built on top of search engine(s). When a user enters a query, the federated search engine simultaneously searches the connected index of different systems and information sources. The federated search system then presents the search results in a single interface.
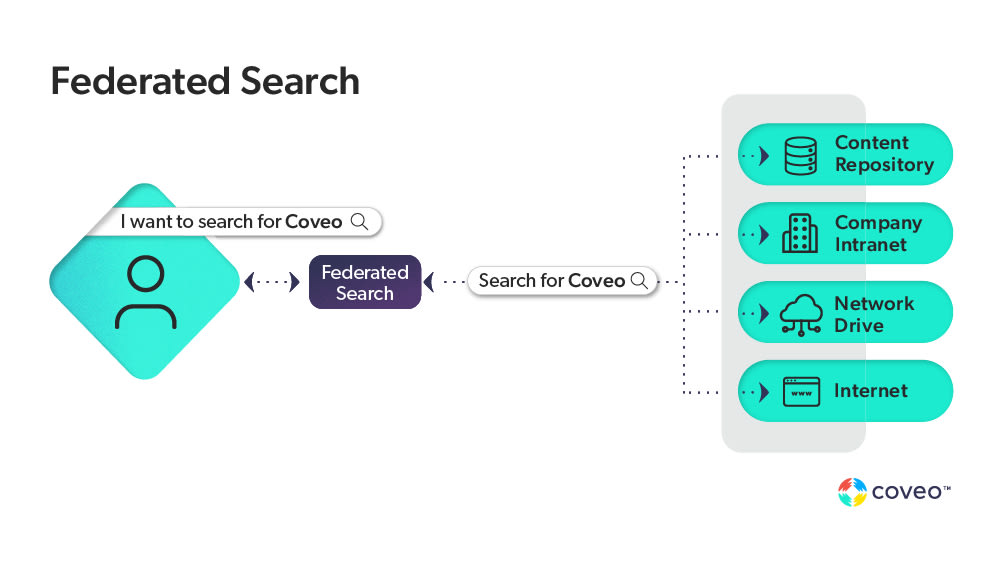
In addition, some federated search engines can also pass along the users’ credentials in the search query. For example, a manager at a tax advisory firm may want to find previous years’ tax returns – but that manager should not have credentials to access other firms’ forms and information resources. By enabling the search engine to pass the end user credentials in an authenticated user setting, the security model of the content is still enforced.
This is invaluable in complex organizations with thousands of sources in the cloud and on-premise — as long as the federated search engine can understand a corporation’s labyrinthic permission schemes!
However, federated search as it is implemented in most organizations today falls short of users’ expectations.
What Are the Limitations Of Federated Search?
Users’ expectations around search have changed in recent years. As digital experiences have advanced and the ever-increasing time we spend interacting with screens, people’s expectations of search are sky-high. Simply put, they want to get to the relevant result as quickly as they can and with as little friction as possible.
Traditional federated search technology is not designed to achieve that.
The main limitation of federated search comes from the fact that it is based on search time merging.
Search time merging (also known as query-time merging) means that when a query is sent to several different systems it searches multiple indexes at once. After each data source is searched, the query generator presents an aggregate list of search results.
It is a simple enough solution that’s easy to implement and is of course a huge step forward from traditional search. But it comes with limitations:
Slow response times
Because each index needs to be searched and maintained separately, response times may be slow because the response for the results automatically defaults to the slowest data source.
Poor search relevance
Since each database is searched independently and the different sources don’t talk to each other, ranking results across multiple databases based on relevance is impossible. In practice, that means that organizations end up ranking the result list according to a deterministic attribute such as date, price, alphabetical, etc.
Poor search user experience (UX)
Most people assume that the search experience only involves the search box and the result page, but today’s users expect much more than that. Think of the best search experience you’ve had and all of the different capabilities that included: autocomplete, query suggestions , filtering and faceting … the list goes on. In a federated search scenario, unless all “federates” (i.e. the multiple indexes) support each of those capabilities, your federated search interface won’t be able to either.
Difficult to implement generative or agentic AI
Traditional federated search makes it difficult to implement generative AI or adopt AI agents. Because relevance is different across search engines it is nearly impossible to fine-tune and provide accurate answers curated for a specific audience.
The search UX, fast response times, and relevance are too important in today’s user or customer experience to be ignored, all the more because, thanks to the digital giants — Amazon, Google, Netflix — users have access to these superb frictionless search experiences in their everyday digital lives.
For better or for worse, digital-first companies have set the bar high, and enterprise search has no choice but to keep up with that.
Federated Search Examples: What It Looks Like In Practice
Federated search is often deployed in industries where content systems are fragmented, regulated, or difficult to unify. It offers a path to access, often at the expense of experience. Below are common scenarios where federated search may seem like the right answer, and the limitations that typically follow.
A Global Consulting Firm with Decentralized Practices
A global consulting firm maintains a wide range of content systems across its practice areas. SharePoint, Google Drive, Box, and legacy CRMs house everything from proposals to project playbooks.
Federated search seems like a straightforward solution — a way to connect the dots without overhauling systems or disrupting team autonomy. But what begins as a convenient bridge soon reveals cracks: duplicate results from multiple repositories, inconsistent metadata, and an inability to fine-tune relevance based on user intent.
Over time, it becomes clear that while access has improved, discoverability hasn’t — and consultants still rely on tribal knowledge to find what matters.
A Multinational Bank Navigating Regulatory Fragmentation
A multinational bank faces a familiar problem: data locked in regional systems, constrained by legal and regulatory boundaries. Customer support logs in the EU can’t be indexed alongside U.S. transaction records, and compliance platforms vary by jurisdiction.
Federated search appears to offer a compliant workaround, enabling analysts to query multiple environments without centralizing the data. But this model quickly hits its limits. Results arrive out of order. Connections between systems remain invisible. And with no shared ranking logic or machine learning layer, the bank can’t surface patterns, personalize insights, or scale AI-driven compliance analytics.
Access is no longer the bottleneck — relevance is.
A Health System with Merged EMR Platforms
A health system, mid-integration following a merger, operates multiple EMR platforms across regions. Content lives in different formats, under strict privacy controls.
Federated search emerges as a way to unify clinician access without triggering data migrations or compliance concerns. For a time, it works: care teams can retrieve patient education materials, protocols, and support content from across systems. But the experience is fragile. Metadata inconsistencies lead to irrelevant results. Load times lag. And in moments where every second counts, clinicians are forced to sift through scattered, duplicate, or outdated content.
Federated search made information findable — but not fast, and not reliably relevant.
Relevant reading: Customer Experience or HIPAA Compliance? Finally, You Don’t Have to Choose
A Telecom Provider Supporting a Complex Tech Stack
A telecom provider supports its customer service agents with documentation that spans Jira, Confluence, Zendesk, and vendor knowledge bases.
Federated search provides a quick fix: agents gain visibility into all repositories without waiting on IT to consolidate systems. The initial impact is promising — fewer blind spots, broader coverage. But as case volume grows, so do the cracks. Search queries return inconsistent results. Knowledge gaps persist because no system learns from usage. And without unified data, the provider can’t deploy AI-based case recommendations or personalize agent experiences.
What began as an integration shortcut becomes a ceiling on service efficiency.
A Multinational Manufacturer with Siloed Technical Content
A multinational manufacturer stores its technical documentation across a patchwork of systems: product manuals in legacy databases, service protocols in shared drives, engineering notes in wikis.
With limited IT bandwidth and global complexity, federated search is chosen to bridge these silos. Engineers gain a single search bar, and for a while, that feels like progress. But version control issues creep in. Critical documents are buried under less relevant results. And with no central structure, the search experience varies wildly by source.
What’s findable isn’t always trustworthy — and without a unified foundation, AI-driven quality control and predictive insights remain out of reach.
Upgrade Your Federated Search Tool with Index Time Merging
There is a different approach to federated search. One that is based on index time merging instead of search-time merging. At Coveo, we call it unified search.
Index time merging is a type of federated search system that creates a single, unified index of all content from multiple databases and content sources that is searched at one time. It has several clear advantages over the traditional federated search technology:
Faster response times
Unified search returns search results much faster than federated search because everything is centralized in one unified index, as opposed to having to search multiple sources with a query-time merging solution.
Modern search UX
In the traditional federated search the search UX depends on the capabilities of each data source. If one database lacks the ability to use facets or filtering, these won’t be there in your federated search solution. On the other hand, index-time merging only takes the content, while capabilities such as filtering, faceting, and other features of the search user experience are built on top, ensuring a best-in-class search experience.
Better relevance
Because all the content from multiple sources is unified in a single index, the system can employ machine learning and use behavioral signals to help find key highlights and bring the most relevant result to the top.
Better foundation for generative AI and AI agents
Index time merging ensures that relevance is applied across all data sources. When there’s a unified index, then generative AI implementations like Coveo’s Relevance Generative Answering can fine-tune and provide accurate answers curated for that specific audience. Relevance Generative Answering uses our unified search platform to ground content by retrieving relevant content from trusted sources that a user is allowed to see. Access controls protect proprietary and private information. Only approved documents will be fed to the LLM to generate the answer.
Relevant reading: Make AI Work: Unified Search & Retrieval for the Enterprise
What Is the Right Enterprise Search Tool for You?
On the surface, it may look like a search time merging solution (traditional federated search) is faster and easier to implement than an index time merging solution (unified search.) Without having to set up a central index, you can quickly get this method set up. If you’re using separate indices, they do not have to be standardized, which further saves time and effort. If your dataset for one index is in one format, and the other is another, it is not an issue for a search-time merging solution.
Index-time merging solutions may take a longer time to implement. The initial setup – creating the unified index, navigating connectors, and ensuring the single data model is set up – takes time and resources.
However, even though the effort to implement an index-time merging solution is high, its enhanced functionality is worth it for user experience when compared to query-time merging. Most tech-savvy organizations end up choosing an index-time merging solution solely for that reason.
Users today expect more than federated search. They expect relevance.
As knowledge workers and consumers, we have been trained by digital-first companies, from the most engaging e-commerce sites to our favorite streaming sites, to have the most relevant information queued up front and center. As stated above, relevance is nearly impossible to achieve with query-time searches.
Fortunately, you can reduce the time and effort involved in setting up an index-time solution, by finding a vendor that does this for you.
To understand how Coveo approaches this, request a demo.
How to Go Beyond Federated Search?
The Coveo Relevance Maturity Model lays out a clear framework for understanding the maturity of your organization’s digital relevance and enterprise search. While index-time merging is a step above siloed search where each source is searched separately, it still fails to meet user expectations for predictive, intelligent digital experiences. As you move up the CRMM, the value to the business multiples.
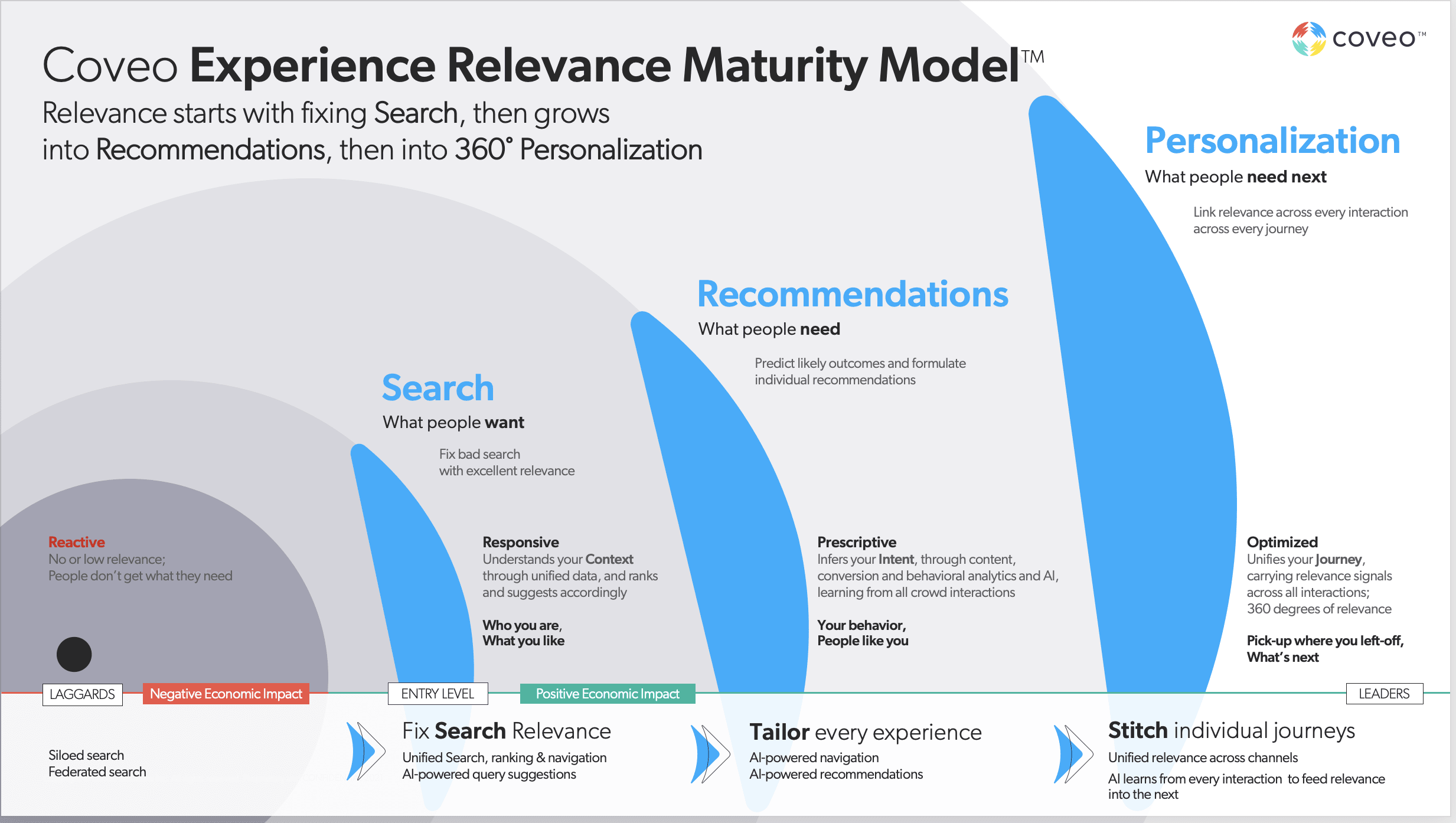
Reactive
- Siloed search: Information lives in separate silos and needs to be pursued and evaluated by the person searching. Lots of work, poor results.
- Federated search: One search that spans silos, but the results are still not ranked against each other, and the person searching has to do the work of determining relevance.
- Digital experiences like websites, intranets, chatbots, and so on are static, offering one universal experience for everyone — one-size-fits-nobody.
- No tailoring for the individual who is interacting with the experience.
Responsive
- Give people what’s helpful to them.
- Make search easy: One place to search, with useful features like query auto-completion and query suggestions.
- The experience considers who you are and what you like.
- The experience considers what has worked for other people like you in the past.
- Results are unified, and ranked against each other, based on relevance.
Prescriptive
In addition to relevant, satisfying search:
- Prescribe what people need
- Predict outcomes and formulate individual recommendations
- Tailor every experience, including AI-powered navigation
Optimized
In addition to relevant, satisfying search and tailored, contextually useful recommendations:
- Prescribe what people need next
- Link relevance across every interaction of every journey
- Pick up where you left off, across every channel and platform.
Ready to take the next step? Discover how you can have relevant search on day one.