

In our last article we looked at some key features of enterprise search that make an insight engine so powerful. In this piece, we will take a closer look at how enterprise search software works and how you can make the most of it..
As a reminder, an enterprise search platform is an information retrieval system that allows the collection and classification of both structured data and unstructured data from all enterprise content sources. Some call it federated search – which is an older term. A more accurate – and desirable solution is Unified Search.
Enterprise search engines are actually made up of various subsystems operating simultaneously in the front and back ends. Thinking of the system as a process helps break through the complexity without getting bogged down by technical details. And the process to finding a solution starts with gathering content.
Enabling Knowledge Management
The promise of workplace search technology is that you can search everything. So if you are going to search through all your databases, you need to connect to everything. And that’s done through connectors.

A “connector” enables you to plug-in to a content source, and this can be done in two different ways. The first way involves pulling content from a data source using a “crawler.” As its name implies, a “crawler” crawls through all sources to extract data — regardless of whether structured or unstructured information. that data is structured or unstructured.
- Structured data is that which is formatted in a way that makes it easily searchable. For example: excel files, product inventory, and customer names.
- Unstructured data is that which is not formatted in a way that makes it easily searchable. For example: text files, audio, video, and social media postings.
The second way involves pushing content by forming an API connection between two content management systems, allowing content to be gathered from its source and sent to where it is being collected without the data source itself needing to be accessed.
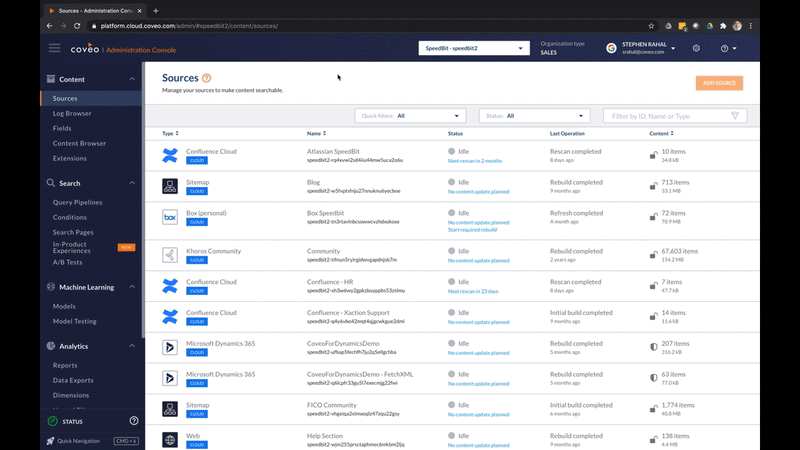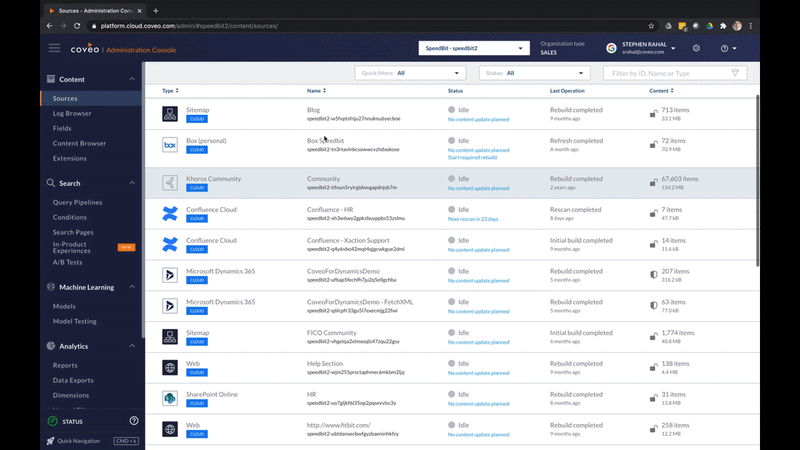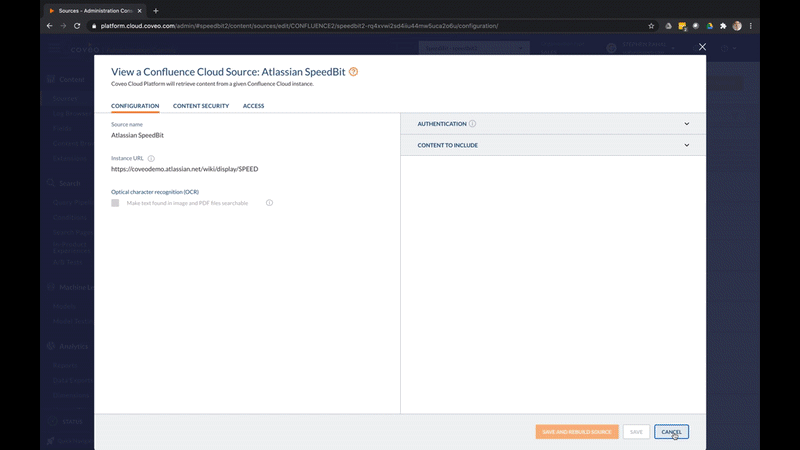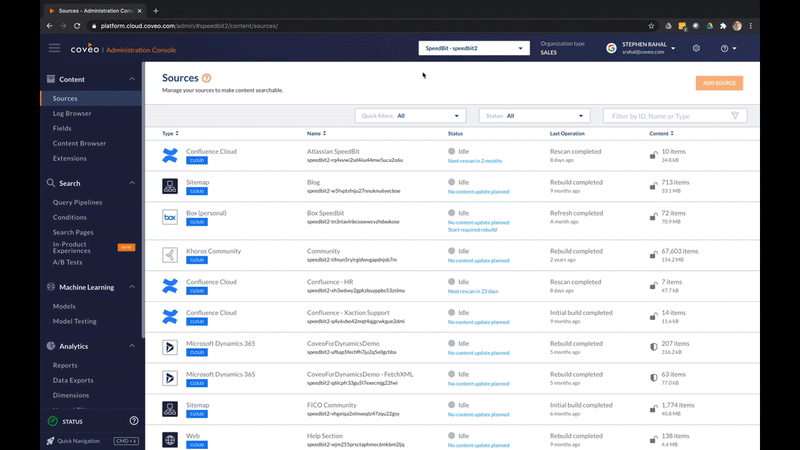
After all the content is pulled or pushed out of its source system, its data needs to be processed and stored in a single location: an index.
Indexing
If you are looking for a topic in a book – you look at the index in a book. In information retrieval, if you are looking for answer, you need to have an index. The index can be simple: containing just the name of a piece of content, let’s say. Or it can be comprehensive: containing every word, number, or string within a piece of content. For the sake of this piece, we are assuming the more comprehensive type of index — called a Unified Index.
Add to your knowledge and learn more about the difference between Index-time and Query-time Merging, here.
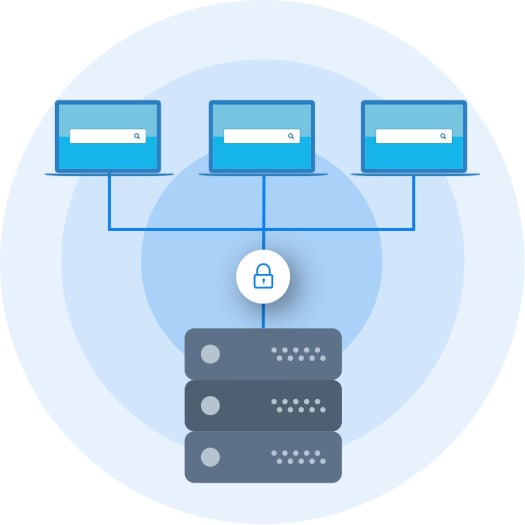
Once everything is brought into the unified index, further processing takes place in order to identify and categorize content so as to make it searchable. Essentially, content is analyzed and annotated based on the information it contains, so that it can later be used to gain insights by matching to a related search term entered by a user.
The “information” captured in this step is content metadata which includes the keywords, ownership, department, version history, etc. associated with a piece of content. Metadata helps to make specific content retrievable by telling the information retrieval system, “If you need to know something about x, choose me!
For example, a document meant to help someone find a solution for the poor battery life of the watch they just bought may be entitled “Common Customer Issues.” Neither “watch” nor “battery life” appears in the title, but they’re repeated constantly throughout the document itself. The metadata would use its powerful insights to indicate that this document would indeed be relevant to the query “issues with watch battery life,” so that it can be returned to the user that entered it.
After all content is collected and classified, and even further enriched through processes such as text summarization, concept extraction, and optical character recognition, search queries can then be processed and a relevant solution can be returned to the user as the search result.
Processing Queries and Returning Results
Queries come in various forms:
- Natural Language Questions: “why isn’t my watch battery working”
- Phrases: “issues with watch battery life”
- Or even just Keywords: “watch battery”
An enterprise search tool processes any of the above query types and compare the terms used in the query (e.g., “issues with watch battery life”) to indexed information (e.g., “watch,” “battery life”) in order to match the query to any relevant content (e.g., “Common Customer Issues”).
All relevant content is then ranked based on its degree of relevance to the query in question and returned to the end user in that order as a list of search results on the search results page.
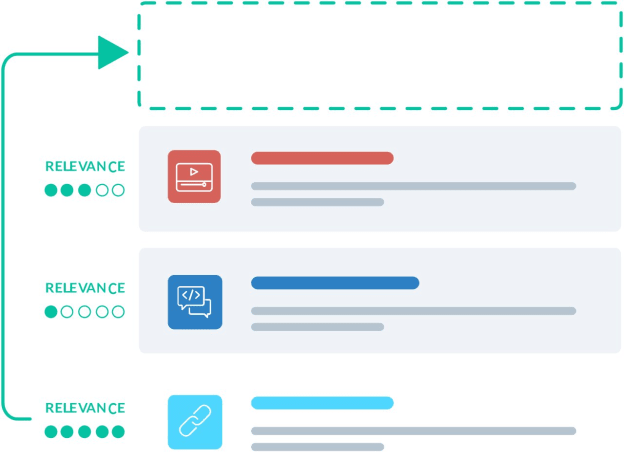
Why An Enterprise Search Solution Often Fails
If you have engineered the above system looking for a search solution, you may wonder why your knowledge worker brethren are still unhappy. Chances are it’s because the metadata you may have added at one time has become outdated and stale.
Enterprise search uses rankings to help users find content and information, which is valuable. However, static findability alone is not enough to improve the user’s search experience, as there is no guarantee that what users find is the result they actually need – especially as their needs change in different contexts over time.
For example, two different users might be looking for vastly different things when searching for “watch battery.” One may be looking for information regarding how long a battery will last and another may be looking to buy a new one.
If enterprise search operates at baseline functionality, as described above, both users will be presented with the same content first – that which is ranked as being the most relevant to the query “watch battery.” But that doesn’t take into consideration the context and intent of the individual that enters that query.
Creating Intelligent Search With Machine Learning
Individual relevance and personalized results is where the value-add potential of search lies, and that only becomes a guarantee when enterprise search is transformed into intelligent search through the application of artificial intelligence (AI) and machine learning (ML).
(This is also sometimes referred to as cognitive search, a step up from semantic search.)
Machine learning models are designed to process big data. It’s this method that enables users to get the relevant knowledge that meets their needs.
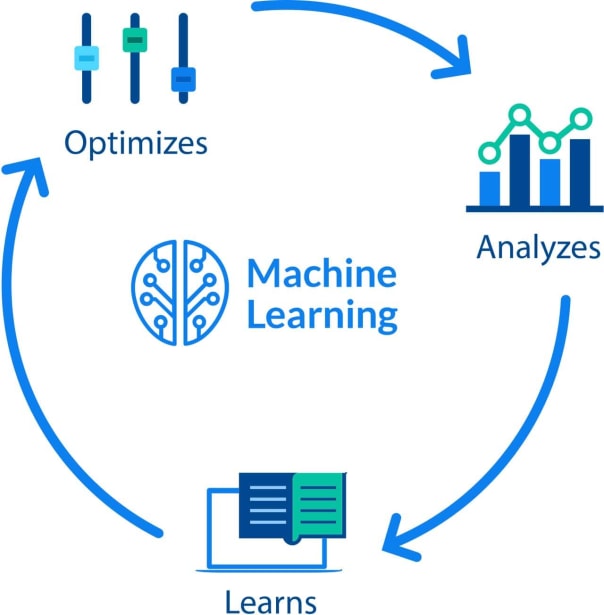
However, just as enterprise (or federated) search alone is not enough to achieve outcomes of proficiency and satisfaction, simply applying ML in name alone is not enough either. It must be done strategically to be effective.
This is why it is necessary to become very familiar with the process behind how it works in and of itself (as described above). Because only then will you be able to understand where and how you need to apply ML in order to make site search to the next level — intelligent search — and truly make it work for you and your business.
With 60% of shoppers reporting that they are frustrated when site search results aren’t tailored to their past online behavior or search query, it’s clear that this shift needs to happen right now to meet user expectations and make them stay. Your customers deserve the most relevant result.
To learn more about the transformative qualities of ML, check out our next post on intelligent search.