

Surfacing relevant information to audiences — quickly — is a complex task. One that requires hard thinking, exploration, and discovery of what your information ecosystem is made of. In fact, when we surveyed more than 600 enterprise search tech professionals, 54% cited lack of understanding by key stakeholders as a significant challenge.

As the steward and user of this ecosystem, you’re best positioned to not only identify important elements but also the relationships between them, ensuring a good user experience wherever information is accessed. This requires some level of data analytics.
The thing is, when we talk about data analytics, we’re really talking about turning data into wisdom. But before we can do that, there are two concepts we need to understand: Data Normalization and the DIKW Pyramid.
As a line of business leader here is why understanding both are important.
What Is Data Normalization?
In enterprise search, normalizing data is essential, but it’s also hard.
At Coveo, data normalization involves analyzing the names and values of metadata from various systems of information indexed in your enterprise search platform. Data normalization is essential to aligning unstructured and structured data to create a better digital experience, surfacing actionable information and knowledge to improve decision-making.
For example, I’ll start with something personal. My health is important to me, my weight in particular. Like all Canadians born under the metric system I count my weight in pounds. To this day, I have trouble going from pounds to kilos for quantities as big as a person’s weight. The same goes for miles and kilometers, although through some odd neuron connections I find it easier to refactor figures by 1.6 (mi to km ratio) than by 2.2 (pounds to kilo ratio).
For the life of me I cannot mentally convert Celsius to Fahrenheit. I invariably ask my smartphone to do it through voice command.
Without thinking about it, we do many data conversions like these in our daily lives. Usually because only one of two values is relevant to us. Machines deal with such conversions — and much, much more complicated ones — to make sense of all the data they process. And they do so by normalizing that data.
Now let’s scale my weight example up. To build an effective digital experience, such as an ecommerce site or a customer service site, you would want to transform your weights to one standard unit of measurement, allowing you to compare apples to apples.
You then align metadata that relates to the same thing, understand how each system formats its data, and decide on a unique format for each metadata. Ideally, this should be a format that’s understandable to all of your Coveo users. Once that’s done, you implement the normalized metadata into the Coveo index, without any change to your source systems.
I’ll show you more shortly, but first, this type of normalization is not to be confused with database normalization.
How Is Normalization Different From Data Standardization?
Standardization and normalization could be taken to mean the same thing here. However, standardization implies in-depth changes to the source systems themselves, whereas normalization occurs strictly within Coveo.
This lets you make all your systems speak a similar language on the Coveo Platform, without complex change management projects affecting all your software.
In other words, the changes happen in your unified index, so source data provenance is intact.
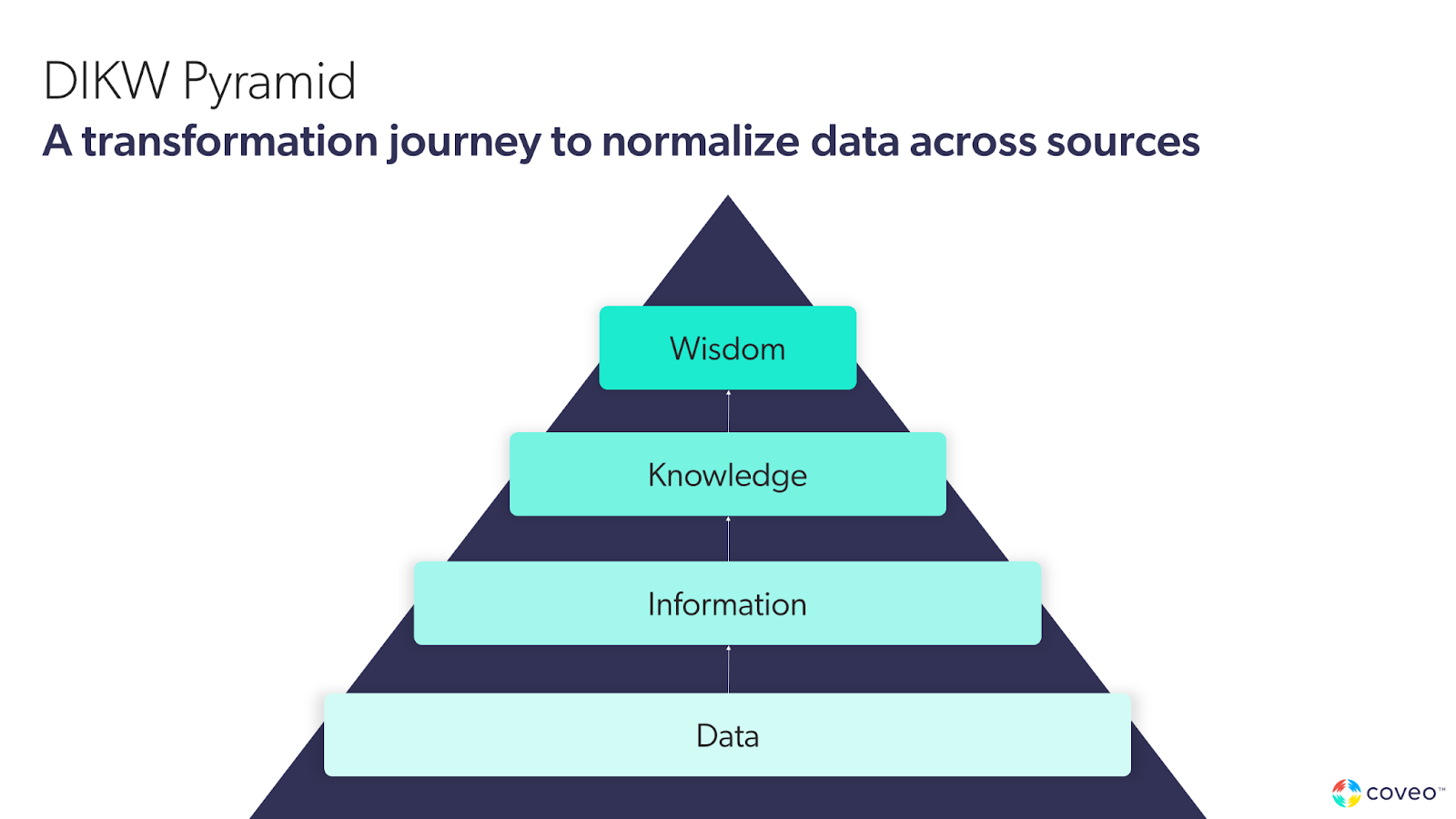
The DIKW Pyramid, Or How to Make Data Actionable
This data normalization process is but a part of the data transformation journey as a DIKW pyramid. The acronym stands for Data, Information, Knowledge, and Wisdom.
To illustrate what this pyramid and its different steps mean, let’s get back to my weight example. I weigh 185 pounds. 185 is merely data. The fact that it is a number that measures weight gives it one layer of meaning: transforming it into information. Cross-referenced with a body mass index chart that accounts for a person’s height, puts that information in the context of what constitutes a healthy weight for a person of a certain gender, height and age: that’s knowledge.
This knowledge enables me to make an informed decision – which in this case will be to keep training and eating properly most of the time.
The DIKW pyramid is a nifty tool to help visualize how wisdom, or insight — or however you want to call the power to make an informed decision — percolates up from knowledge. Which is often considered a series of conclusions obtained through information; which in turn stemmed from seemingly innocuous bits and pieces from an ocean of data. How you transform from one layer to the other can be automatic — or highly manual.
What Are the Benefits of Data Normalization?
Because data is normalized via your index, your audiences can place it in the context that makes the most sense for them. One example of this is through search facets, which empower searchers to filter large swathes of information.
So for a workplace context, you might have documents that come from Google Drive or SharePoint. Perhaps they’re PowerPoints, PDFs, or even XML files. With data normalization, your users can check a single facet to better sift through documents, bringing them closer to relevant information faster.
Where Data Normalization Fits in the DIKW Journey
The pyramid wisely does not say exactly how the transition between each step happens. The process is bound to vary wildly from one organization to the other — but the path to wisdom becomes harder every year.
In their book Organization Data Mining: Leveraging Enterprise Data Resources for Optimal Performance (Nemati, Barko. 2003), two enterprise data experts cite an already old (2002) study from the University of California Berkeley. It found “the amount of data organizations collect and store in enterprise databases doubles every year, and slightly more than half of this data will consist of ‘reference information,’ which is the kind of information strategic business applications and decision support systems demand.”
Organizations have been generating data faster than they can consume it for a good while now. AI-powered search offers a way to build a pyramid on top of which searchers can stand, seeing the bigger picture that this sea of data actually paints. This helps them ground their decisions on the right wisdom, provided at the right moment.
What’s really interesting to me is the next-to-last step in the DIKW pyramid: the one that goes from information up to knowledge. In a data normalization context, how do you take multiple systems that model the same information in different ways, and reconcile these bits of information so you can search across everything efficiently?
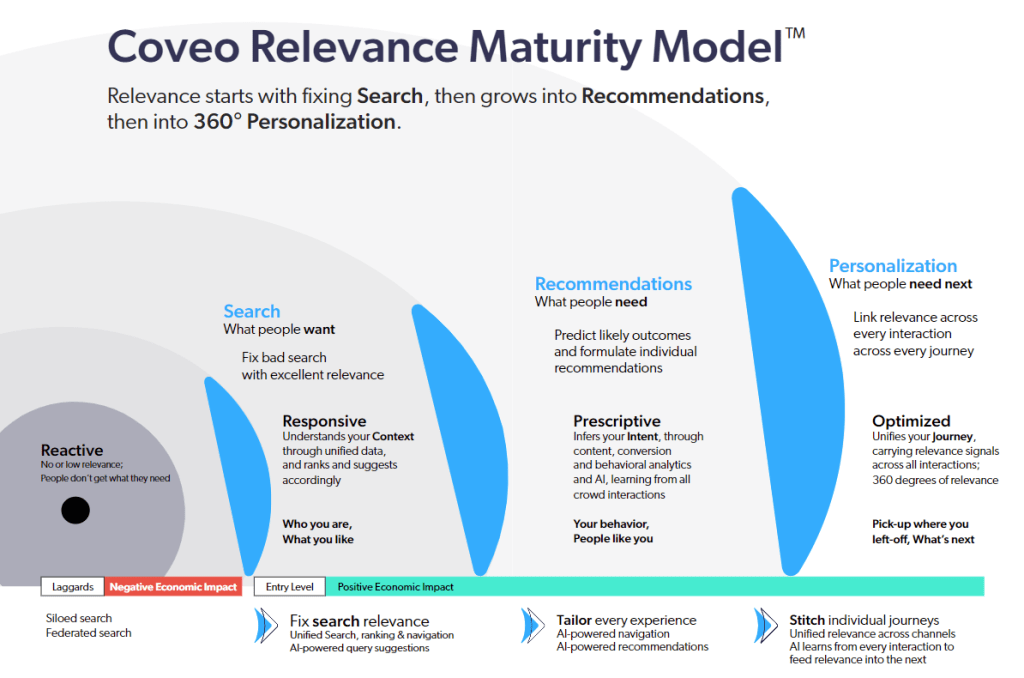
At Coveo, that’s the process we call data normalization. Within the Coveo Relevance Maturity Model™, this applies at level 2, when organizations have moved from federated to unified search. It is crucial to get this step right to have a solid foundation upon which to build the next.
How Coveo Handles Data Normalization During Implementations
Typically, our Professional Services team and/or implementation partners build this foundation when a solution is implemented for our customers. Like the Egyptian architects of old, they bring experience in design and marvelous tools to help shape a vision. And they get to work with the materials that are available.
There’s data sitting across multiple ticketing systems, wikis, file shares, CRM systems, CMS systems, product catalogs, and so on. Of course, a lot of that data is already arranged in finite sets of elements, so that you have a measure of data already structured into available information. It’s never ‘just a primordial soup of data’. What we usually find, however, is that information is structured and expressed in different ways, depending on where you look.
Parts that are bought from a distributor in Europe may use kilos and Euros. Whereas from a distributor in North America, the products might be in (U.S.) dollars and pounds. A person wanting to compare would want to see all products one way (or the other) so they could make an informed decision.
The beautiful thing about normalizing within metadata is that if you are a global site, you can give users full control over their experience. If I am in Europe, I can filter on metric. If I am in North America, I can filter on the imperial system.
So how do you sort it out?
Enter data normalization, which helps through the tricky part of taking data and shaping it into information, and then knowledge. The gist of it is to find common elements among, say, knowledge articles from a CRM, PDFs sitting in a file share, and JIRA support tickets.
Once you’ve pinpointed those elements which represent the same concept in different ways, they have to be made the same at the level of Coveo’s unified index. Let’s illustrate this.
Since Coveo is often used by businesses who sell products, many of Coveo’s implementations naturally revolve around product information. Sometimes there is existing metadata in documents that clearly state what product(s) it relates to.
Sometimes the information is there but it’s unstructured, as is illustrated by the data element in the following table. On the SharePoint row, the product name and version are clearly there — but all bundled in one single string. More often than not, there are subtle differences in the way Awesome Product v1.2 is tagged in a SharePoint page, a JIRA ticket, and a Salesforce Knowledge Article.
| Source | Data element | Content |
| SharePoint | Item Metadata (name: ows_productfull) | AwesomeProduct v1.2 |
| JIRA Ticket | Field (name: product) | Awesome Product |
| JIRA Ticket | Field (name: version) | 1.2 |
| Salesforce KB Article | Field (name: productid) | 0000AgZxyz12355446 |
| Salesforce KB Article | Field (name: productversion) | 1 |
| Salesforce KB Article | Field (name: productsubversion) | 2 |
Take it from a former Solution Architect: this is not an extreme example.
Tapping the Right Team Players
It’s fairly common for the Coveo Professional Services team to have such discrepancies to reconcile, so that information that pertains to the same concept gets tagged correctly in the unified index. This is a team effort, one that requires valuable input from the customers’ system owners, administrators, and users.
Through workshops, our Business Architects and Solution Specialists help you decipher what and how to normalize information elements within your unified index. This automates common structuring among these systems and builds the foundation that allows you to achieve peak relevance.
For example, the customer and Coveo teams could likely decide that two fields in the Coveo index are needed to organize knowledge in a meaningful and structured way: @productname and @productversion. Those two fields would then be populated with homogeneous data, using different mechanisms based on the Source being processed.
Once populated, these fields can then be used as facets that allow users to narrow results by selecting values that are meaningful to them.
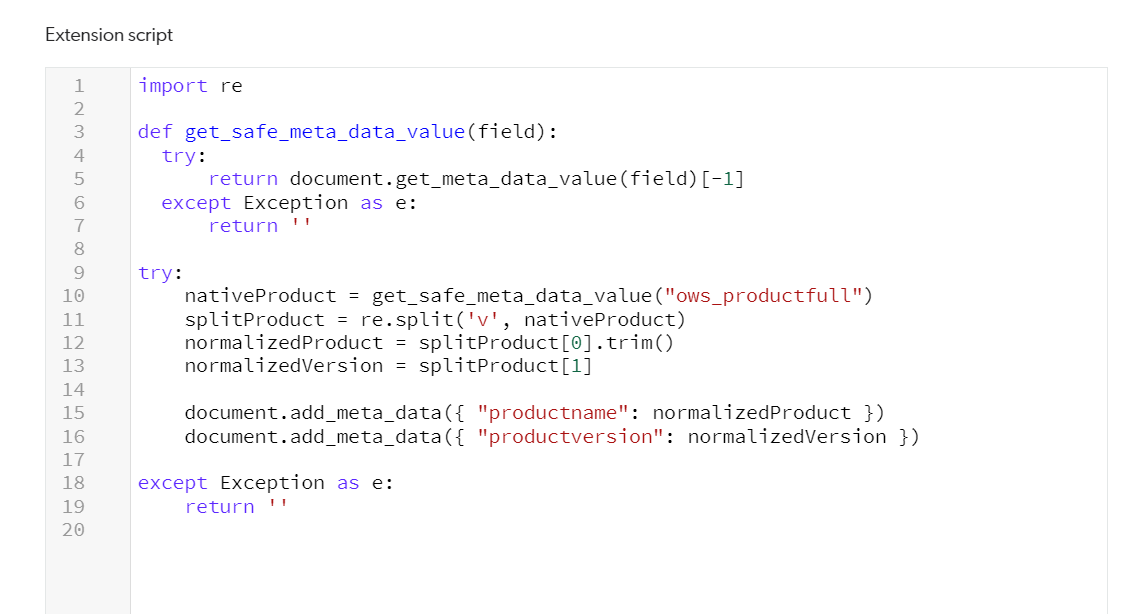
SharePoint: Use an Indexing Pipeline Extension (IPE) to parse the ows_productfull metadata and extract the product name and version from the character string. Then apply it to Coveo fields.
JIRA: Apply direct mapping in the source’s configuration. Simple!
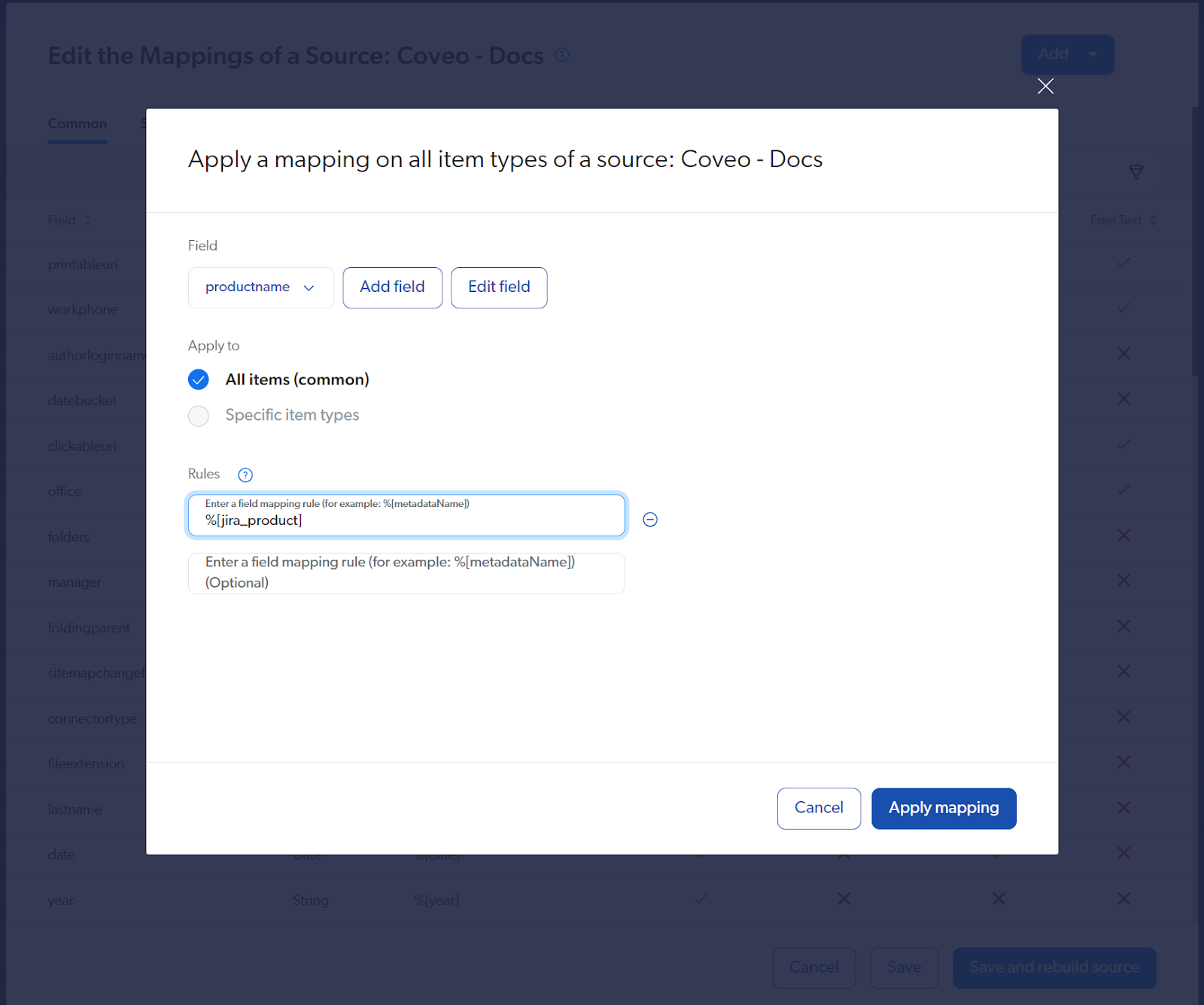
Salesforce: Easily taken care of by concatenating the version and subversion information into the @productversion field. The product metadata element in Salesforce, however, does not contain a name but an ID. We can solve in at least three ways:
- Manually change the Salesforce source configuration to retrieve the product name instead of the ID.
- An IPE makes a call to Salesforce to retrieve the product name based on the id, then mapped to the @productname field. This guarantees best precision, but can add a significant amount of time to the indexing process.
- Use a static id/productname mapping to populate the @productname field in the IPE.
Use Coveo to Shape Knowledge in Your Organization
Looking at all this, one cannot help but ask: so I basically need to be an expert on my own data if I want to get all the value out of it?
Although having someone in a knowledge management role in your organization definitely helps, the short answer is no. You don’t need to be an expert, and for two reasons.
The first: should you wish to change the metadata that your index manages, you can explore what’s available and what it looks like through our View Metadata page. This came out in 2022 and allows you to look at all of your Coveo indexed data points.
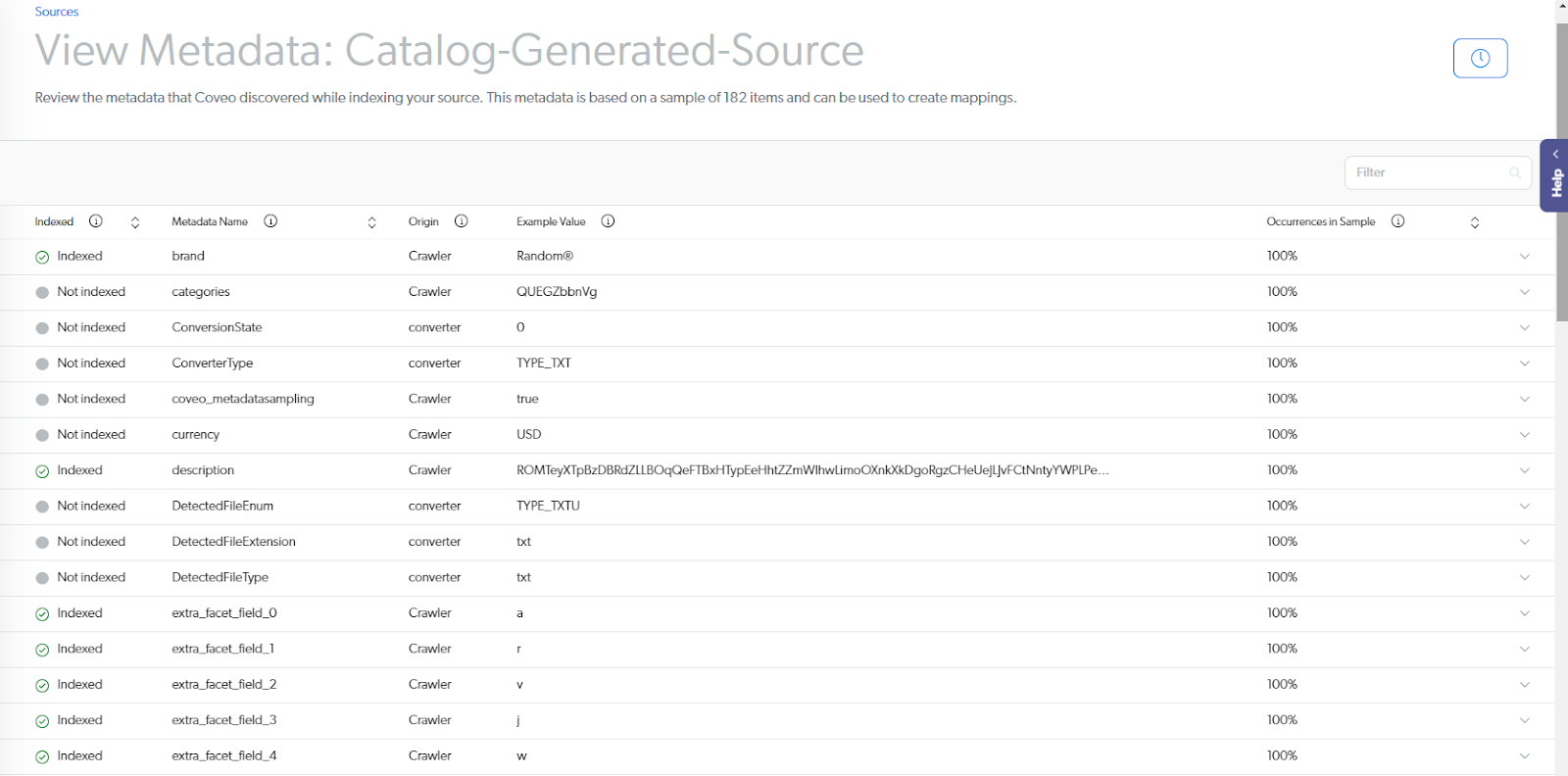
Then, you can make informed decisions about whether to remove some elements or add new ones to your unified index. From there, by comparing how data belonging to field 1 in source A and data stored in field 2 from source B might be remapped in field 3 in a streamlined fashion that resets the way knowledge is represented.
2. Our Professional Services team knows what questions to ask. These questions can suss out how to figure out what matters to you in your daily work and what data should be marked as measurable information to make actionable knowledge out of it.
Then Coveo can normalize and present that data to you and your organization in the right context for you to make insightful decisions.
Dig Deeper
If this blog whet your appetite on the technical aspects of AI search, check out our white paper.
This free, 15-page read gives you a high-level technical overview for evaluating platforms that create frictionless, personalized experiences.