

During 2023, Generative AI (GenAI) was the talk of the town. Yet applied AI research on ecommerce extended far beyond.
We’ve witnessed an array of insightful research papers pushing the frontiers of technology and strategy. The broad spectrum of research articles, from advanced recommender systems to neural networks enhancing query understanding, has charted a course for imminent innovations.
In the face of rapidly advancing technology, the “wait and see” approach is no longer viable. 2024 is the year business leaders will be tasked with adopting innovative technologies, with a keen eye on driving ROI. The cutting edge is here and now, presenting a prime opportunity for you to uncover its potential value.
Let’s explore some of the key research papers of the year that are guiding the ecommerce industry forward.
1. GNN-GMVO: Graph Neural Networks for Optimizing Gross Merchandise Value in Similar Item Recommendation
One major business metric for ecommerce companies is gross merchandise value (GMV). Unfortunately, traditional recommender models don’t typically account for this.
That’s about to change with Walmart’s new paper, introducing GNN-GMVO, a Graph Neural Network architecture. GNN-GMVO focuses on optimizing GMV in similar-item recommendation tasks, emphasizing the importance of revenue-related objectives.
By proposing a multi-objective decoder function and a refined edge construction framework, they enable the model to capture intricate item-item relations and enhance the recommendation accuracy without compromising revenue.
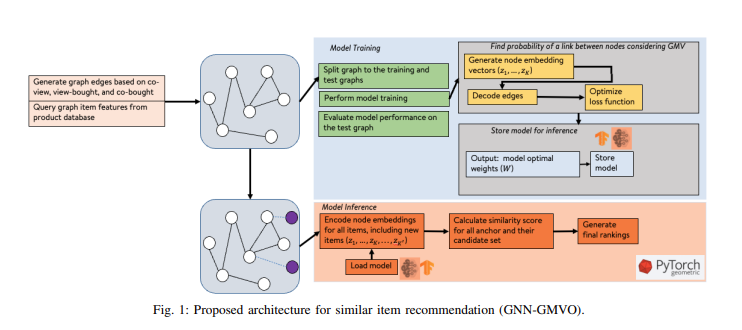
We’re really passionate about this topic at Coveo, as we’re a global leader in using artificial intelligence (AI) to transform search, recommendations and merchandising. We are currently working on a Scale AI project to develop machine learning and personalization algorithms that consider not only the revenue generated but also the overall profitability of a transaction.
These algorithms will use new data about margins, storage costs, shipping costs, disposal costs, return costs and others to measure and optimize the end-customer full basket’s profitability.
2. Universal Multi-modal Multi-domain Pre-trained Recommendation
Recommending socks with shoes isn’t too difficult — but offering recommendations to a science fiction reader who also happens to love classical music? That’s a whole other ballgame. Making suggestions across industries (or in ML parlance, across domains) is a topic this paper from Tencent attempts to tackle.
It proposes UniM2Rec, a pre-trained multi-modal multi-domain recommendation framework that learns universal representations of item contents and user preferences.
Unlike existing methods that use only item text, UniM2Rec incorporates multi-modal item contents (e.g. text and images) from all user-interacted domains. It constructs multi-modal item embeddings, projects them into a shared space using parametric whitening and mixture-of-experts, and encodes user behaviors chronologically.
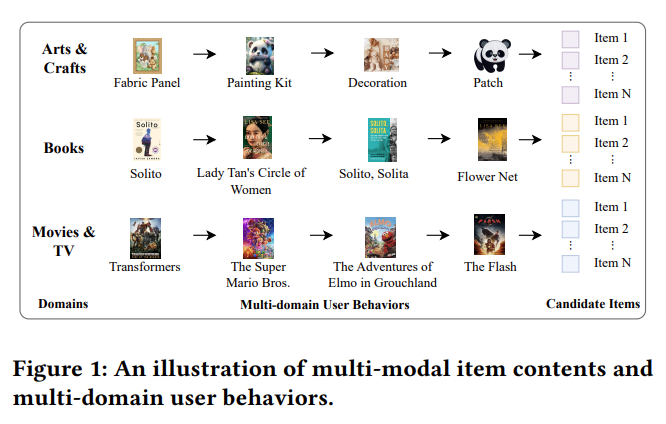
At Coveo, we’ve extensively researched multi-modality — a case in point is our paper, Contrastive language and vision learning of general fashion concepts. Based on research led by Coveo and featuring a joint collaboration with Stanford University, Università Bocconi, Telepathy Labs and FARFETCH, it was recently published in Nature Scientific Reports.
To help machines “think” like humans, they must be able to master general concepts. Through extensive benchmarks and novel tests, our paper shows that CLIP-like models can learn an industry — for example, fashion — and not just “one dataset”. In other words, you can train once, and re-use the model multiple times.
Representing a significant advancement in the field, this means that by leveraging the approach detailed in the paper your ML model can recognize even improbable products such as “long nike dress” (Hint: it likely never appeared in any training set). The model discussed in our paper was trained on one of the biggest curated fashion catalogs in the world (Farfetch is one of the most successful shops in the world, with >800k items in store).
3. LLaMA-E: Empowering E-commerce Authoring with Multi-Aspect Instruction Following
No two ads are alike. In an era of uber personalization, what’s targeted to one group is tweaked to appeal to another. Sometimes these changes are time-consuming; other times, they’re simply tedious. Altogether, this labor intensive process is a difficult one to scale, but Etsy introduces a potential solution.
The paper outlines LLaMA-E, a series of large language models (LLMs) designed specifically for various ecommerce authoring tasks. These tasks involve creating compelling promotional content for products and services. The proposed LLMs are tailored to handle the complexities of ecommerce scenarios, incorporating domain-specific knowledge related to customers, sellers, and platforms. They are trained using an expanded instruction set created through a combination of domain expert input and a teacher model (GPT-3.5-turbo-301).
The rise of LLMs is an important trend we care about. Besides conducting research, over the past year we have focused on developing solutions to tackle key use cases. We released Relevance Generative Answering as a secure, enterprise-ready generative answering set of capabilities across commerce, service, workplace and website use cases. In ecommerce, this helps generate answers to complex customer queries while respecting permissions, ensuring answer freshness and limiting hallucinations.
4. Personalized Category Frequency prediction for Buy It Again recommendations
Buy It Again (BIA) recommendations are essential for retailers to enhance user experience and engagement. But what if you could expand those repeat purchases to similar items in a category, instead of just 1:1?
That’s what this paper from Target proposes by introducing a recommendation system called a hierarchical PCIC model for Buy It Again (BIA) recommendations in ecommerce platforms. The proposed PCIC model consists of a personalized category model (PC model) and a personalized item model within categories (IC model).
The PC model predicts which categories customers will repurchase from, and the IC model ranks items within those categories. The paper emphasizes the effectiveness of personalized category frequency modeling in BIA predictions and shows that category-based repurchase modeling is more effective in handling large datasets with sparsity issues.
This is a very important use case. At Coveo, many of our B2B customers use buy again recommendations, alongside other B2B specific recommendations, such as ‘complete my job’. You can find more details on B2B specific needs and use cases by reading this case study on Fleetpride, a leading distributor in the US.
5. Seasonality Based Reranking of E-commerce Autocomplete Using Natural Language Queries
Our product choices shift with the seasons — winter gloves, summer dresses, etc. — making this temporal shift important in ecommerce search. Popularity, however, can often overshadow seasonality, making this a sticky issue to represent in a digital space.
This paper from Walmart proposes a neural network-based approach to enhance the query autocomplete (QAC) feature in search engines, specifically focusing on incorporating seasonality as a signal. The authors introduce a ranking model for QAC and discuss the importance of considering seasonality in suggesting relevant queries, particularly in e-commerce.
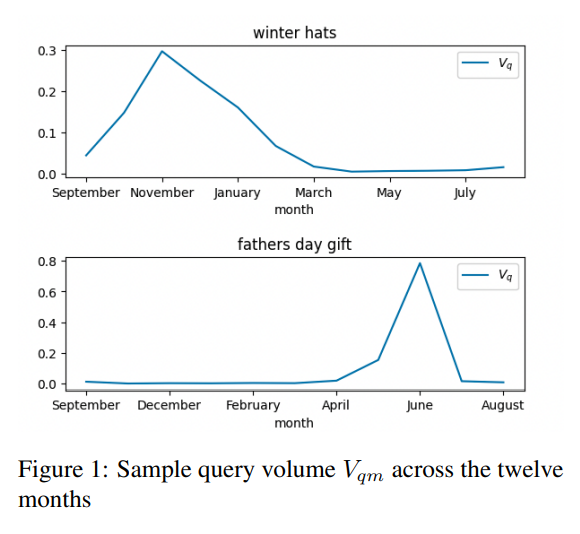
They define a query’s seasonality score based on query volume and use a feed-forward neural network to predict this score for different queries and months. The generated scores are integrated into the autocomplete ranking model to improve relevance and business metrics.
We’re excited to see more research into this topic. On multiple occasions, we’ve defended that ecommerce search is sui generis and online shopper queries often don’t provide enough context to truly understand intent — where seasonal relevance nicely illustrates this point. Interested in the topic of seasonality? Don’t miss our post discussing how local climate has an influence on consumer behavior.
6. Domain specificity and data efficiency in typo tolerant spell checkers: the case of search in online marketplaces
Misspellings — aka, typographical errors — are a major source of frustration for online marketplace visitors. Due to the short search queries used and domain-specific nature of these marketplaces, traditional spell checking solutions don’t perform well. This paper from Microsoft addresses the challenge by presenting a solution that utilizes a neural network-based typo correction model trained on synthetic data.
The study introduces a method involving data augmentation and a multi-layer LSTM model. The model’s context-limited domain-specific embeddings are deployed in a real-time API for Microsoft’s AppSource marketplace, resulting in improved clickthrough rates and reduced instances of no search results. The paper highlights the significance of synthetic data for improving model accuracy and demonstrates the feasibility of such an approach in real-world applications, emphasizing its potential for experimentation and privacy-conscious data usage.
At Coveo, we agree that typo-correction is a foundational capability that an ecommerce search engine should master. Unsure if your search is competitive enough? Request a site assessment from Coveo. Our strategists and ecommerce experts will audit your capabilities for free.
We have also released a key feature, Query Suggestions Automatic Fallback, that helps decrease the chance of dreaded zero results pages with a new model which automatically displays products based on the last successful set of suggestions.
7. Representation Online Matters: Practical End-to-End Diversification in Search and Recommender Systems
As technology becomes increasingly integrated into the daily lives of billions of people globally, it is crucial for online platforms to reflect the diverse communities they serve. This paper from Pinterest addresses the issue of representation in online platforms and introduces an end-to-end diversification approach to improve the diversity of content in search results and recommendations.

The approach consists of three components:
- identifying requests that require diversification,
- retrieving diverse content from a large corpus,
- and balancing the trade-off between diversity and utility in the ranking stage.
We agree that improving recommendations is a critical endeavor. Yet the key related question is how to assess them in the first place.
In the past, we published EvalRS: a Rounded Evaluation of Recommender Systems. Presented at CIKM, this paper features a collaboration between Coveo scientists and researchers from academia (Università Bocconi) and industry (Microsoft, NVIDIA).
It introduces EvalRS as a new type of challenge, in order to foster a broad, fruitful discussion among practitioners and build in the open new methodologies for testing recommender systems “in the wild.”
8. Diversify and Conquer: Bandits and Diversity for an Enhanced E-commerce Homepage Experience
In ecommerce, screen placement is power. It shapes user experience, engagement, and conversion rates. According to research, users scroll down the homepage up to three times, clicking on widgets within the first two scrolls.
How can retailers make the most of their limited screen real estate? Myntra aims to personalize widget rankings by addressing this challenge as a contextual multi-armed bandit problem with delayed batch feedback.
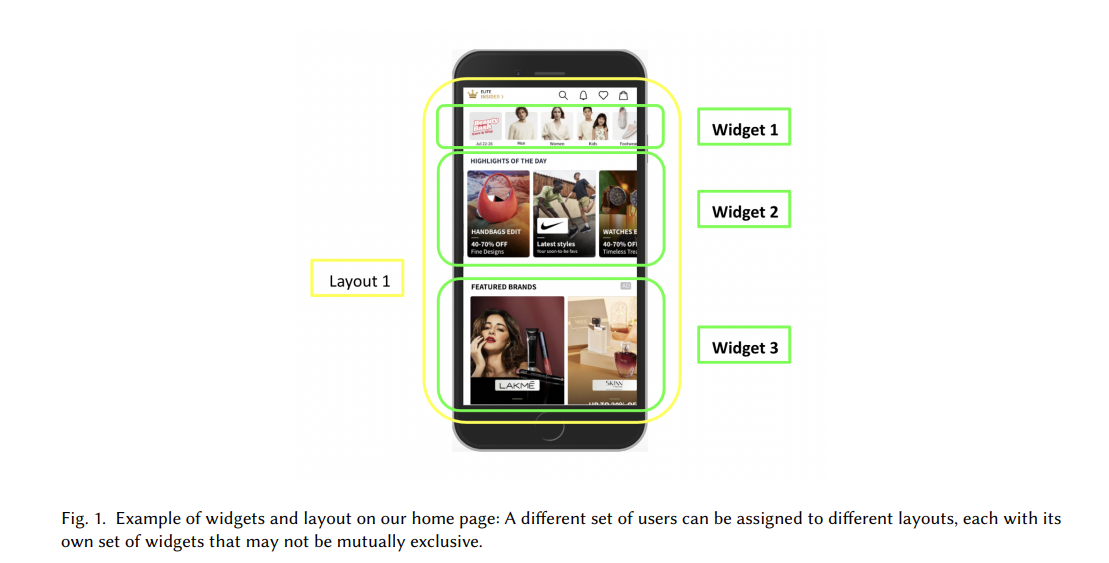
They propose a two-stage ranking framework that combines contextual bandits with a diversity layer to enhance overall widget ranking. This approach considers the heterogeneity of widgets, even when limited historical data is available, and introduces features like Core theme and Widget intent to identify widget content types.
This is a truly fascinating topic. Coveo scientists have been applying techniques based on Reinforcement Learning to improve the experience of product discovery, so we are pleased to see further interesting research on Reinforcement Learning applications in information retrieval.
9. Cold & Warm Net: Addressing Cold-Start Users in Recommender Systems
With 86% of ecommerce shopping sessions originating from anonymous users, and given challenges like profile data availability, third-party cookie deprecation, lack of user authentication, and the “cold start” machine learning problem, delivering personalized experiences for cold start users has become increasingly complex for retailers. Yet common solutions fail to specifically and practically solve this issue.
This paper from Tencent addresses the cold-start recommendation problem, focusing on users who have limited interaction history. They propose a model called Cold & Warm Net that leverages expert models to handle cold-start and warm-up users separately. A gate network is used to combine the expertise of these models based on the user type and state. Dynamic knowledge distillation is introduced to assist experts in learning user representations effectively. Additionally, a bias net explicitly models user behavior bias, selecting relevant user features through mutual information.
At Coveo, we released Personalization-as-you-go as a specific solution to the cold start problem for both product search and recommendations. You can read more here about its application to product search specifically. This is also why Coveo was awarded top honors by the UK Ecommerce Awards in the Ecommerce Innovation category.
Also, our researchers have used an approach based on product embeddings, which have actually become a cornerstone for a considerable amount of machine learning models by ecommerce innovators and rely on deep neural networks. They have been used by the companies that are investing the most in AI innovation, such as Amazon, Walmart, Pinterest, Yahoo, Alibaba,Microsoft, Criteo, and Coveo.
10. Unified Embedding Based Personalized Retrieval in Etsy Search
While lexical or keyword-based search is still an important part of today’s search systems, it’s known to suffer from a vocabulary problem. That is, the way a consumer describes a product might not match the product’s actual description.
This paper from Etsy presents a novel approach to address this and improve personalized semantic retrieval in product search. The authors propose a unified embedding model that combines graph, transformer, and term-based embeddings.

They discuss their design choices to balance performance and efficiency and share insights on feature engineering, hard negative sampling, and transformer model application.
Coveo has leveraged embeddings for personalization for many years. We have discussed the differences between semantic and cognitive search, as well as the role of personalization, in several blog posts (e.g. Is Semantic Search Enough for Ecommerce?)
We are also prepared to demonstrate the impact of our AI solutions for semantic search and personalization through our new AI Experience Pilot.
Dig Deeper
Experience is today’s biggest differentiator. Discover Coveo’s unique capabilities to inject AI across every touchpoint of your customers’ journey.