

Real-Time Personalization: Use Case
Meet Audrey, Coveo’s (part-time) director of marketing and (full-time) long-distance runner (notwithstanding the iStockPhoto-like picture, we swear she is a real person). As one of the ‘loyal customers, she is browsing products on a sports apparel website, looking at one recommendation after the other:

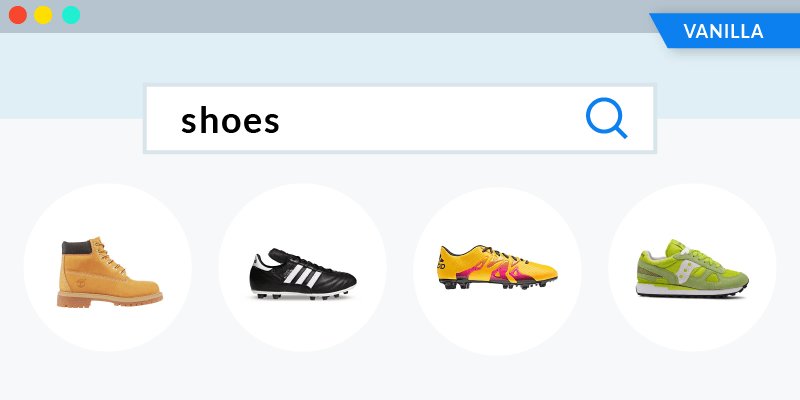
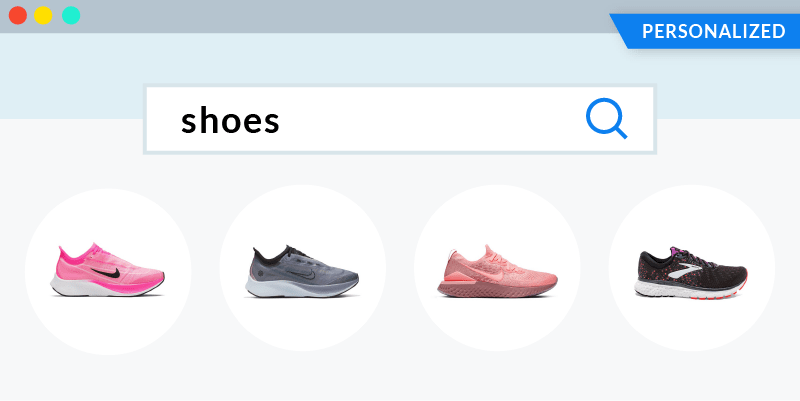
In search of a personalized experience, Audrey decides to use the search bar and starts typing “shoes”. Out of the two sneakers below, which product recommendation do you think would interest her?

Humans can easily spot the “running” theme in the above session and choose the right – pink sneaker. But search engines struggle to understand that association (trained humans will also spot the “for women” theme: could you do it?). While many vendors claim to do , doing it for real is a highly non-trivial task at scale.
Two see some success from real-time personalization, you must get two things right:
- A coherent data collection or ingestion practice needs to be in place to be able to leverage all the real time data
- The retrieval system must be capable of handling the information in a principled way.
In this blog post, we show how to provide real-time personalization in something like 100 lines of Python.
This piece introduces how to apply powerful ideas from Natural Language Processing (NLP) to eCommerce personalization. You can use this as an open-source playground to test these ideas on your data or as a starting point for a deeper product discussion.
What is personalization, anyway? If you are already familiar with embeddings, skip through the first few sections and go straight to personalization at the end. If you need a more gentle introduction, clone the repo and tag along- the code is freely available on GitHub (check the README for all setup details).
And if you’re not quite ready for the nerdy details just yet, learn more about how to personalize for anonymous visitors – without massive amounts of data – from the perspective of a non-AI scientist:
It’s now time to make a runner/director of marketing happy.
[DISCLAIMER: This is a lot more fun if you have some real commerce data to play with (it should be seamless to plug them into the provided script). While we will mostly be discussing clothes, it is obvious that the same considerations apply to any other vertical. All the examples below are created with anonymized data sampled from real websites.]
Trailer: (Vector) Space(s): The Final Frontier
“The limits of my language mean the limits of my world”
— L. Wittgenstein
It’s often said that computers are good with numbers but stink at most everything else. In fact, if you want to feed them words, you first have to transform them into a numerical representation. For the longest time, we just lazily put a 1 in a vector full of 0s to distinguish between different words:
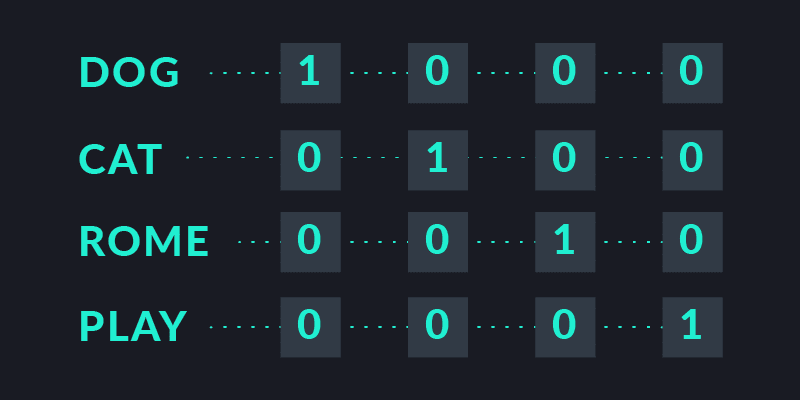
There are two problems with the lazy idea though. First, if we have more than four words, we will need very big vectors for all our 1s and 0s. Second, by looking at two vectors it is impossible to tell if they are actually related or not. DOG and CAT are intuitively more similar than DOG and PLAY, which in turn are way more similar than DOG and ROME.
One of the biggest discoveries in “modern” NLP is that we can substitute the lazy representation above with something that solves both problems simultaneously: word embeddings. The main intuition is that words that are “related” tend to appear in similar contexts:
- The cat was waiting for me at home.
- Have you ever wondered what dogs do at home all day?
- Rome has horrible traffic, but great museums.
- The best museums in Europe are in Berlin.
Cats and dogs are usually found in sentences around pets, Rome in sentences around Italy and cities, and so on. By looking at what is before and after a word, we can learn a vector whose entries are not just a bunch of 0s, but actual coordinates in an abstract space—it’s the Artificial Intelligence equivalent of “you can learn a lot about a man from the company he keeps.”
[NERD NOTE: For those that are interested, there are already many explanations of how the algorithms work. This video from our friend Piero Molino and the original Mikolov’s paper are great ways to get started.]
Once you learn better vectors, you can explore this “abstract space of words” to verify that similar words are indeed close to each other:
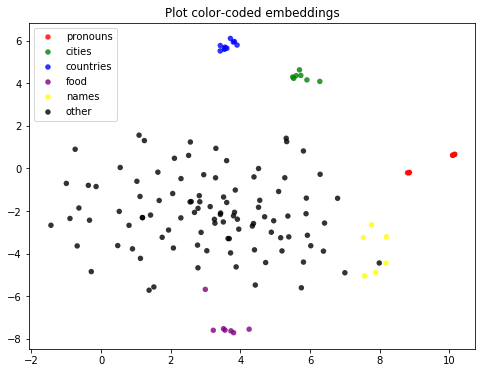
Moreover, this space reflects important properties about the meaning of words, allowing machines to reliably solve analogies like the following:
BOY : KING = WOMAN : ?
PARIS : FRANCE = BERLIN : ?

Cool, isn’t it? If vector spaces are so awesome, why stop at word embeddings?
While not everything that counts can be counted (as that guy said), most of what can be counted can be embedded: proteins, social networks, DNA, songs, sets, and, more to our point, products (e.g., lipstick).
As it turns out, learning product embeddings in digital commerce bear a lot of resemblance to the original challenge with the words above. If you think about our runner again, browsing can be seen as a sequence of events—going from product A to product B, etc. If a text is made up of sentences, which are made up of words, a digital experience is made up of sessions, which are made up of products.

Since we are reusing the same model, we can reuse the same code (check the repo)! With a bit of training on our laptop, we finally have product embeddings.
Interlude: Traveling the Product Space
“Logic will get you from A to B. Vectors will take you everywhere”
A. Einstein (almost)
Just as the word ‘space’ reflects human intuitions about meaning, the product space reflects important intuitions about sports apparel. This is made clear when inspecting which products are close together in this space.

The following 3D representation is made by projecting down to three dimensions the embeddings learned from session data.

To help with visual clustering, we color-coded products by sport/activity. The ability to learn the sports affinity for products based solely on user interactions is indeed pretty impressive. When the TSNE plot stabilizes, sports clusters become easily identifiable, proving that our embeddings naturally capture a lot of the latent properties of products.
Of course, analogies are still a thing, and it is indeed incredible how accurate they can be. Our AI can even match the pants and jersey of a soccer team, as displayed in the following example (Juventus pants to Juventus jersey as Manchester pants to Manchester jersey). Talk about personalized recommendations!

The ability to automatically capture subtle aspects of sport, gender, and style, purely based on user behavior and customer data, can power many use cases in commerce at scale. It’s now time to apply all these ideas to the hot topic of website personalization.
Finale: Personalized Search (And, Well, Everything Else)
“Real luxury is customization.”
L. Elkann
Now that we have product vectors, we can use them as building blocks across all our architecture and machine learning models.
Do you want to improve item-item similarity (say, for product recommendation)? No problem. Cluster products together based on their position in the latent space. Cold start problem for a new pair of sneakers? No problem. As a first guess, take the centroid of vectors from the same category (e.g., all other sneakers).
The case we want to present is slightly more complex. Consider Audrey’s session again:
Assuming we have real time marketing setup along with available product vectors, how can we personalize the search results for “shoes”? The answer is straightforward:
- We create a “session vector” representing the user intent. To do that, we average the vectors for all the products in the session.
- We employ a retrieve and re-rank strategy (as is typical in the industry). To do that, we first retrieve the top-k items according to our retrieval strategy and then re-rank them based on how similar they are to the session vector we just calculated.
[NERD NOTE: In the shared notebook we wanted to show how to put together the end-to-end use case with “realistic” tools. We picked Coveo and Elastic as inverted indexes and Redis to store/retrieve vectors, but obviously other setups are possible.]
Math aside, the best way to understand session vectors is, unsurprisingly, a spatial metaphor.
If you consider the entire space of products we built, browsing a website is exactly like walking in that space—exploring products is tantamount to exploring the vector landscape.
The crucial insight here is that by moving from one product to the other, we are walking around this abstract land, implicitly expressing our interests (in the same way as spending your vacation in Hawaii or Aspen reveals a lot about your preferences). The only thing we need to do now is to use this data to create a buyer persona and provide personalized search results along the customer journey.
{kind=link}
{kind=link}
To simulate a toy search engine, we prepared a bunch of matching conditions to fake product retrieval. When we query the index for “shoes” in the vanilla, non-personalized scenario, the results are good but obviously completely removed from the “running” theme above.
When we query the index in the personalized scenario, by injecting the session vector in the ranking mix, results are incredible.
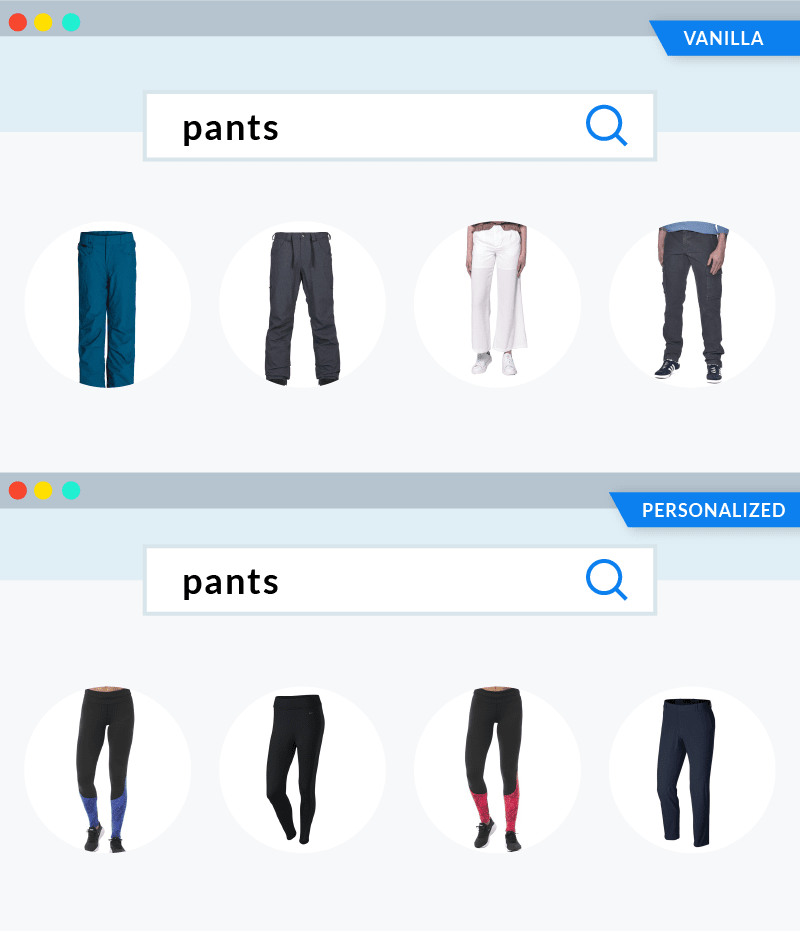
Something even more impressive is that the ability of embeddings to capture the intent of the user extends to queries not directly related to the products seen in the session. If you search for “pants” after browsing for running shoes, the difference between vanilla and personalized results are again impressive, showing how well the “running” theme is captured by the search engine.
If we strive to make all the interactions on our commerce site as memorable as possible, personalized search can get even more relevant.
What Next for Web Personalization
“In theory there is no difference between theory and practice. In practice, there is.”
Y. Berra
In this post, we showed how AI can learn a lot of things about products automatically and how it can reason effectively at the subtle interplay of concepts, such as style, sport, gender, team affiliation, etc.
We’ve barely scratched the surface of what can be done to build and exploit a “product space.”
How far back in the life of our users should we go to provide relevant real time personalization? Can we inject our product embeddings in other dense architectures to, say, generate personalized type-ahead suggestions?
Moreover, we did not address all the challenges that go into deploying a product that actually works reliably at scale, starting from data ingestion. All the power of embeddings is lost if we don’t engineer data collection, aggregation, and retrieval with real-time, web-scale use cases in mind.
What to explore first mainly depends on what we are trying to achieve in a given scenario, as “personalization” may mean very different things in different contexts. At the very least, digital commerce should leverage the nature of digital shops to provide a different (good) customer experience to everyone, with AI helping your website visitors more and more. The rise of the “online shopping assistant” is real.
Physical stores cannot change their appearance in microseconds like websites can, but they can use human assistants to understand people, trends, and fashion concepts. Any AI that wants to truly match this human expertise cannot avoid learning “deep” concepts about the products involved. In the end, whatever your final use case, the path to provide a million personalized experiences to a million people – and not persona – is likely to be a path through the fascinating (vector) spaces we built today.
See you, space cowboy
At Coveo we help leading companies to personalize millions of digital experiences for customers, partners, dealers, and employees. Interested in our product? Get in touch to learn more about personalization at scale. Interested in building AI systems at the intersection of human behavior and natural language? Get in touch to learn more about our job openings.
Acknowledgments
No director of marketing has been harmed to write this post. Thanks to our clients for proudly being a part of the AI-revolution in commerce, Andrea for the usual editorial help, Jean-Francis for scientific feedback, Francis for IR support and Audrey for not taking herself too seriously: all the remaining mistakes are mine and mine only.