


To each her own (query suggestion)
Before you (I) go, can you read my mind?
– (Almost) The Killers
Both Alice and Bob clicked on a Facebook promotion that brought them to the digital storefront of a famous sporting goods retailer.

Since Bob is interested in soccer, but Alice is interested in tennis, we expect their search experience to be different from this point onward. When they start typing in the search bar, Bob should receive “soccer suggestions” and Alice “tennis suggestions.”
This is, in a nutshell, the big – yet often unfulfilled – promise of personalization in the digital era.
An ecommerce site can in theory change its face in real time depending on shopper actions and underlying intent, but how does that work in practice?
So many vendors claim to provide systems that help you “get to know your customers over time.” But few will tell you that there are only a limited number of opportunities to learn about a given customer. Particularly if they bounce. And even the best marketplaces have a ~40% bounce rate, with very few recurrent users in a year (it’s not uncommon to have only 10% of users coming to a shop >2 times/year).
Personalization Before You Know Your Shopper
In other words, a digital storefront needs to impress users as quickly as possible to convince them to stay. Personalization is not just a matter of what, but also a matter of when.
In this article, we will explain how in-session actions can be used to generate relevant suggestions for users that have never been on the site before. Our method, based on ongoing lab research, is fast to compute, easy to generalize, and privacy-friendly – meaning no cookies required.
If you’re not quite ready for the nerdy details, jump off here to learn more about how to personalize from the very first interaction – without massive amounts of data – from the perspective of a non-AI scientist:
So, the real question, dear Artificial Intelligence, is: before (I) go, can you read my mind?
[NERD NOTE]: This blog post is based on our published paper for the WWW Conference 2020 – it contains all the mathematical details for those brave enough to look.
“You Complete Me”: Typo Tolerance Model
Consider a shopper that is typing “sh” into a search box on the website of a popular shoe shop:
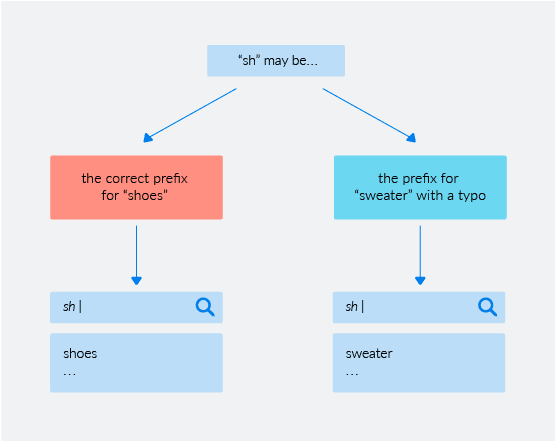
In this scenario, there are two hypotheses to consider regarding query intent:
- the user might be searching for something that actually starts with “sh” (such as shoes).
- the user might be searching for something whose root is “close enough” to “sh”, but not exactly (say, sweater).
Sometimes a query is so relevant that we are willing to “tolerate” typos. For example, on the same shoe shop site, a query starting with “sw” would most likely be a typo for “sh” – as in “shoes”. However, at other times we are more likely to accept a less frequent query as written if it clearly points to something else.
As rare as sweaters might be on that shoe shop site, it is very unlikely that the intent behind a query starting with “swe” would be to write and find “shoes” – and is instead a genuine, though misguided, attempt to write and find a “sweater”.
Good auto-completion should be able to determine the intent that a shopper has when they begin to type. Thank god somebody way smarter than us came up with something that perfectly fits our needs: the noisy channel model (NCM). Given that the user is typing a query in the search box, NCM picks the completion with the highest probability among all candidates as computed by:
NCM) P(completion|query) ~= P(completion) * P(query|completion)
P(completion) is the language model (LM) and P(query|completion) is the error model (EM), and they correspond to the two hypotheses highlighted above. LM is an estimate of how likely the occurrence of a given completion would be, regardless of user input; EM is an estimate of the likelihood that something is a typo.
However, if you followed the story of Alice and Bob closely, you may have already realized that the LM is not so straightforward. The same prefix might be completed differently in sessions on different sections associated with different intents. A quick look at some real-world commerce data – see table below – confirms this intuition: the idea of having a universal set of “top N queries” does not really make much sense, as different site sections may have wildly different “top N queries”.

Even if typos were consistent across sections, P(completion) should indeed be modeled as the conditional probability P(completion | context). If we want personalization, we need to go from a vanilla language model (LM) to a conditional language model (CLM).
Solving in-session personalization depends on answering two questions:
- How can we build a CLM?
- What is a computer-friendly scalable representation of context for our CLM?
We will solve them in turn.
Computers That Speak Like…William Shakespeare!
Conditional language models are a conceptual extension of good ol’ language models, but we’ve only recently become able to harness their power in real industry use cases. The development of deep neural nets gave us exactly what we needed to do just that:
- The ability to model long-range dependencies effectively;
- General tensor-based architectures that work well even with a mixture of (possibly high-dimensional) data types and variable length.
Due to their enhanced memory, deep learning methods greatly outperform traditional Markov models in assigning probabilities to sequences of words in a sentence (e.g. the fake Shakespeare here).
Courtesy of their generality, models developed for image captioning (i.e. given a picture, what is a good description of the scene in English?) and machine translation (i.e. given “I like dogs” in English, what is the correct Italian translation?) can be repurposed for in-session personalization.
The “trick” is the encoder-decoder architecture, in which we encode the starting representation (input) in one conceptual space (English sentences into an “English space”, pictures into a “visual space”), and then we learn how to reproduce the target representation (output) in the second conceptual space (English captions, Italian words).
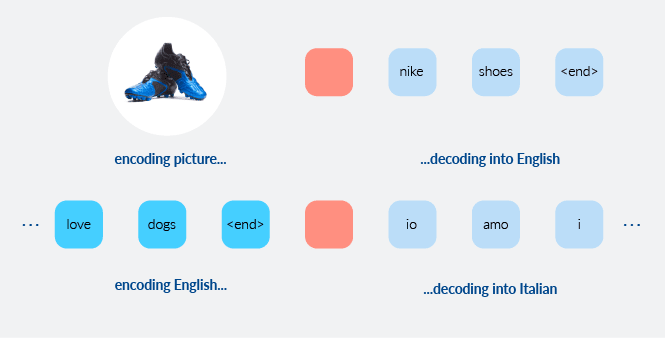
Image captioning and machine translation are both specific cases of a more general idea: how can we map representation from one space into another?
Different data types would require different encoding strategies, but the general idea stays the same: with enough data, we can learn how to produce appropriate output for (1) pictures or (2) English/Italian sentences that have never been observed before.
For “decoding” the graphic representation and producing a sentence of variable length, we use LSTM cells as the backbone of our neural language model. And to show how image captioning works, we built a quick “vanilla” language model with Keras. The code trains an image captioning model with product images and descriptions found online; after the training is complete, a tiny Flask-powered app will pick images from the test set and display what the model thinks is a good “product name” for that image. While not perfect, it is actually pretty impressive to see what our captioning architecture can do with such a small dataset:
So, now that we know how to make language generation dependent on some graphic representation, we turn to our second question: how can we properly encode a shopper session in the commerce world?
Injecting Session Information
As we have seen in our table above, shoppers’ queries differ greatly across sections. Sections are identified by the products they contain, so it is just natural to conceive of a shopping session as being a compilation of products browsed by the user. Looking at the recent advances in machine learning, there are three options to represent those products:
- Text embeddings. Using techniques such as word2vec or fastText, we can identify a product with the low-dimensional representation of its textual meta-data.
- Product embeddings. The loyal reader will remember we introduced “prod2vec” in our previous “clothes in space” post. Trained from user behavior on the target site, they are deep representations based on the skip-gram model from NLP.
- Image embeddings. Deep learning was a quantum leap for computer vision. By leveraging the general image features encoded by big pre-trained networks (such as VGG16), we can identify a product with the dense representation obtained by passing its image through a convolutional neural network.
(1) and (2) have shortcomings when it comes to developing scalable solutions. Text embeddings require the existence of models trained in the target language, and they don’t play nicely with vertical-specific language. Product embeddings are powerful, but require advanced tracking libraries to be in place for several months before deploying a smart NLP solution. From this perspective, image embeddings have several attractive properties:
- Product images rarely change, so all vectors need only be pre-computed offline one time, with no latency constraints or requirement of devoted hardware to complicate things;
- Image vectors are straightforward to compute using standard libraries that leverage big pre-trained networks;
- The quality of product images is, on average, vastly superior to other types of meta-data. A catalog may be written in a rare language or contain unique words, but, for example, fashion images will always be somewhat comparable across fashion brands;
- The quality of product representation becomes somewhat independent from specific user data, making images effective in situations with missing historical data or cold start scenarios.
If we pre-compute and cache an image vector for each product, we can quickly maintain a session vector for a given shopper in real time. We are then able to update that vector with each new product view simply by taking the average of all the image vectors seen so far in the session.
When the shopper starts typing in the search bar, this session vector will be injected into an encoder-decoder architecture, allowing natural language to be decoded from an image-based representation of the products viewed thus far in the session.
The following table uses a sports apparel catalog to compare an industry-standard popularity suggestion model (i.e. a model suggesting the same query to every shopper) to a personalized suggestion model (i.e. a model suggesting a query based on the current products in the session – first column):

By representing sessions with products, we solve the problem of “small-data” personalization – shopper intent is built by leveraging information not actually related to their current session. In other words, we can get a query suggestion API that is fully personalized – “a million people, a million experiences” – without needing shoppers to spend lots of time on our website first.
It is not “mind-reading as you type”, but it is close enough!
Conclusion
There are a growing number of studies devoted to accurately measuring the impact of personalization strategies on business goals: by 2020, smart personalization engines used to recognize customer intent will enable digital businesses to increase their profits by up to 15%. However, personalization means different things to different types of users and shops.
Whatever the industry vertical, a fundamental goal of marketing efforts is to bring new shoppers (for which no data is available, ex hypothesis) to an ecommerce site. If your personalization strategy only works for recurrent users, you are missing out on the chance to speak to a vast portion of your audience and grow your business by wow-ing first-time users.
In a world increasingly concerned with data treatment, it seems important to note that personalized query suggestions – along the lines of what we discussed – can be achieved with respect for user data. In-session data is, by definition, only useful within a session. Provided some random pairs <session vector, query> are collected daily, the vast majority of browsing data can be discarded at the end of the session without lowering the performance of the system.
See you, space cowboys
While we focused on the many virtues of image-based representations today, this is not the only choice. For example, product embeddings are known to produce accurate representations of the product space, and our preliminary simulations show that they outperform image vectors by 25% (as measured by a standard type-ahead metric, i.e. MRR).
If you want to learn more, read our published paper, check out what we were doing at the WWW conference and stay tuned for our next exciting work.
And don’t forget to watch the recorded demo of our psychic abilities Coveo AI-powered eCommerce search. Prepare to be amazed.
Acknowledgments
Thanks to our co-authors Federico and Ciro, and to Luca for precious help with data ingestion and data engineering, and Emily, for being able to encode-decode our English properly.