

Unstructured content.
As a writer, I hate that term. I remember the first time I heard reference to it — sitting in a meeting and technical people were talking about all the unstructured content that a publishing company produces.
Huh? Why would articles — pieces of information that are placed in a specific hierarchy, titled, subtitled, chunked, and limited in word count to be as succinct as possible — be considered unstructured?
After all, anyone who made it through primary school follows a linguistic pattern, or “structure,” in order to communicate effectively.
But in the lexicon of geekdom, any article, picture, PowerPoint, video, song, or any other piece of user-generated content (your kids’ text messages and social media posts, ahem) are all just that: unstructured. Any “data” that doesn’t fit nicely into a column or a row is considered unstructured.
And it’s a pain in the neck to search.
Unstructured Data vs Structured Data
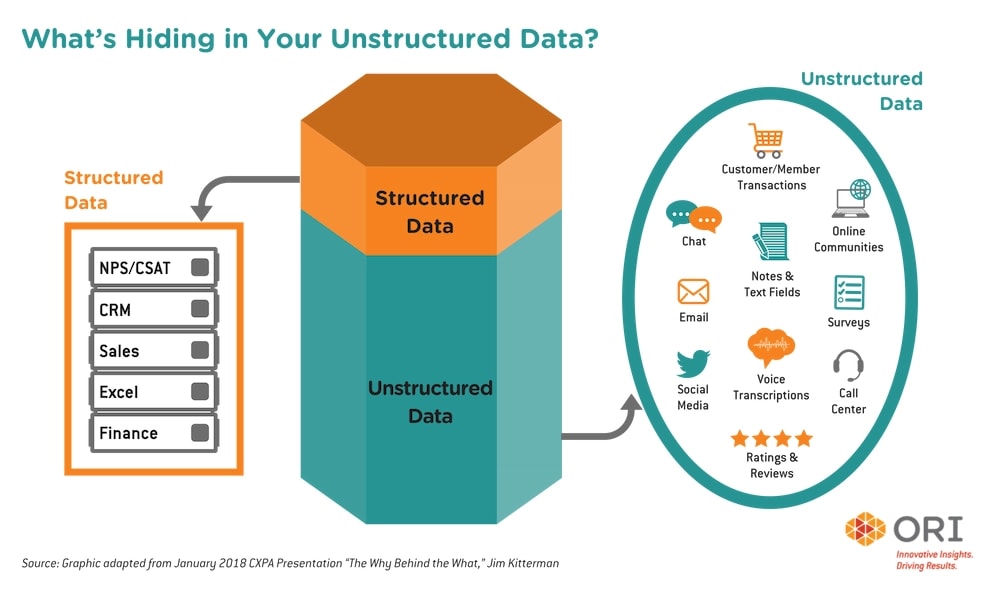
As much as I find the word ironic, there is a logic to labeling information as structured vs unstructured data: Data that is NOT tabular — that doesn’t fall neatly into the rows, columns, and cells of a table — is considered unstructured data. It lacks a predefined data model and is not organized in a pre-defined manner.
(They also sometimes use the term ‘semi structured data’ as data that is structured with self-defining metadata, like XML.)
Turns out though, all that unstructured data makes it very hard to search on. Don’t believe me? Go to Craigslist — which tries to impose structure on advertisements by putting it under broad categories and locations.
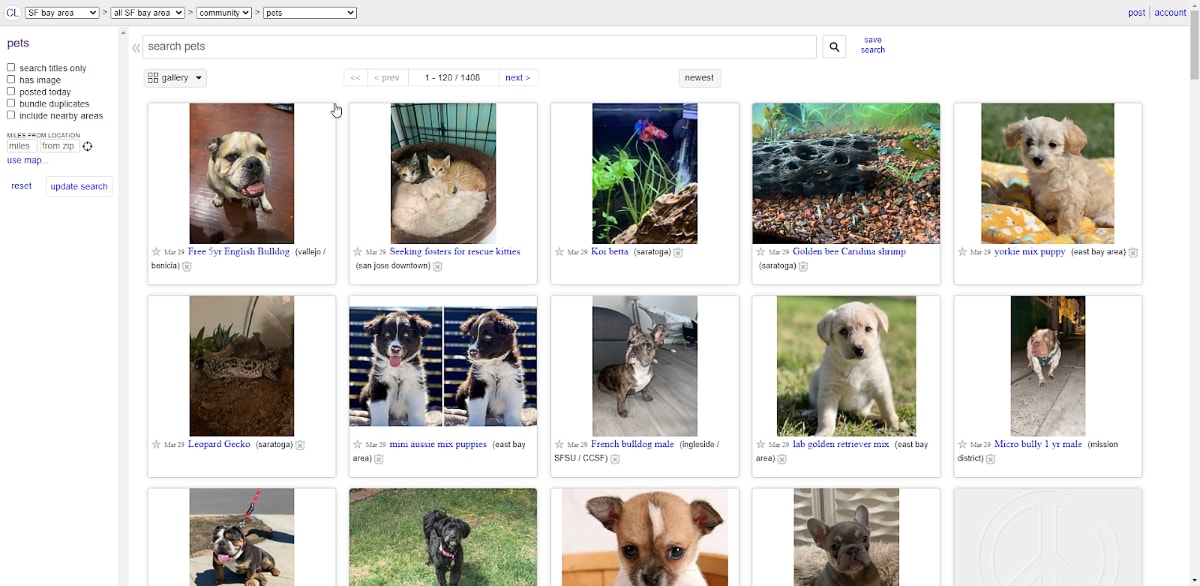
Other than that, it’s pretty freestyle. Nannies are caregivers are sitters (baby or otherwise) — and plural or not. And search on one of those terms at the peril of not finding it under the other. Not quite the Netflix customer experience we’ve all come to expect, is it?
On the flipside, are the sites that allow only structured content. Consider a real estate site where the data fits neatly in a table and has descriptive titles like Type of residence, # of Bedrooms, Exterior, Price, MLS # etc. Having that structure makes it easy to query or search on that information.
SQL is the acronym for Structured Query Language. A relational database uses SQL to find content by looking in the appropriate fields. Which is all well and good for customer, accounting, and inventory systems from a technical data management perspective. But what about people?
Unstructured Data Examples
Now think about all the unstructured information that flows around enterprises. (Or worse; is siloed or hidden.) Google Docs, Microsoft 360, Slack messages, emails, PDFs, articles, and even all the comments in your CRM. These are things that we refer to simply as: Content.
Finding anything among all these different content repositories is time-consuming and aggravating. You likely need to know where it is stored and what it is named. And that’s if you even know it exists.
Searching unstructured content is one of the reasons why enterprise search became so critical.
6 Things To Know About Unstructured Content
- It’s everywhere. Analysts, pundits and people in the know estimate that more than 80% of content produced in an enterprise is unstructured. That’s massive amounts of business intelligence from which your business could be drawing valuable insights, but is instead sitting in data storage somewhere.
- Content is containerized. Unstructured content resides in containers like .doc, .ppt, tiff, .html — and you must have the right software application to read or edit that enterprise data.
- Managing unstructured content is hard. Because content resides in containers, it’s hard to know what’s in each one.
- Good metadata is essential.Like the label on a can, metadata can tell you what’s in the container without you having to open it. (Good metadata, anyway.) Having a strong taxonomy can assist with embedding metadata. Creating metadata – manually, by machine, and ideally both – is a critical step so knowledge workers, customer service agents, marketers, readers, whomever! can find the most contextually relevant information.
- Using a unified index makes searching across all that feasible.Instead of having to go into each cupboard, and through each can, a unified search system gives users a single interface through which they can query and retrieve their desired results.
- Apply machine learning (ML) and natural language processing (NLP) to scale this system. ML models can be trained on user behavior signals to establish context and learn relationships between different pieces of content. NLP enables users to search in the same way they’re used to conversing. In the end, this helps humans create and curate relevant experiences, at scale.
Putting Unstructured Content to Work
As I stated, everyone has tons of content that doesn’t fit neatly into tables and rows. But that seeming lack of a structured format doesn’t make that content any less valuable.
Connecting silos and unearthing your PowerPoints, Google Docs, PDFs, and much more is how you can provide relevant experiences for different audiences — employees, customers, partners, and more. And with artificial intelligence, curating these experiences in a one-to-one fashion becomes a lot easier.
While I don’t like the term ‘unstructured content,’ the acronym CTDFWICAR (Content That Doesn’t Fit Well In Columns And Rows) is hardly memorable. So while it may be “unstructured,” it’s not unimportant.
Finding ways to unlock that value is crucial.
Dig Deeper
An intelligent search platform powered by machine learning that ingests behavioral data and serves up relevant interactions can help resolve unstructured content problems. Learn more about the Coveo Platform™ today.