Dieser Inhalt ist nur in englischer Sprache verfügbar.

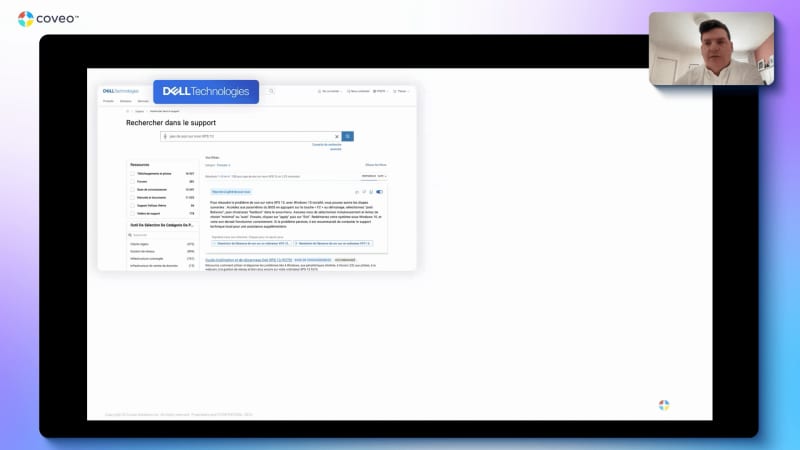
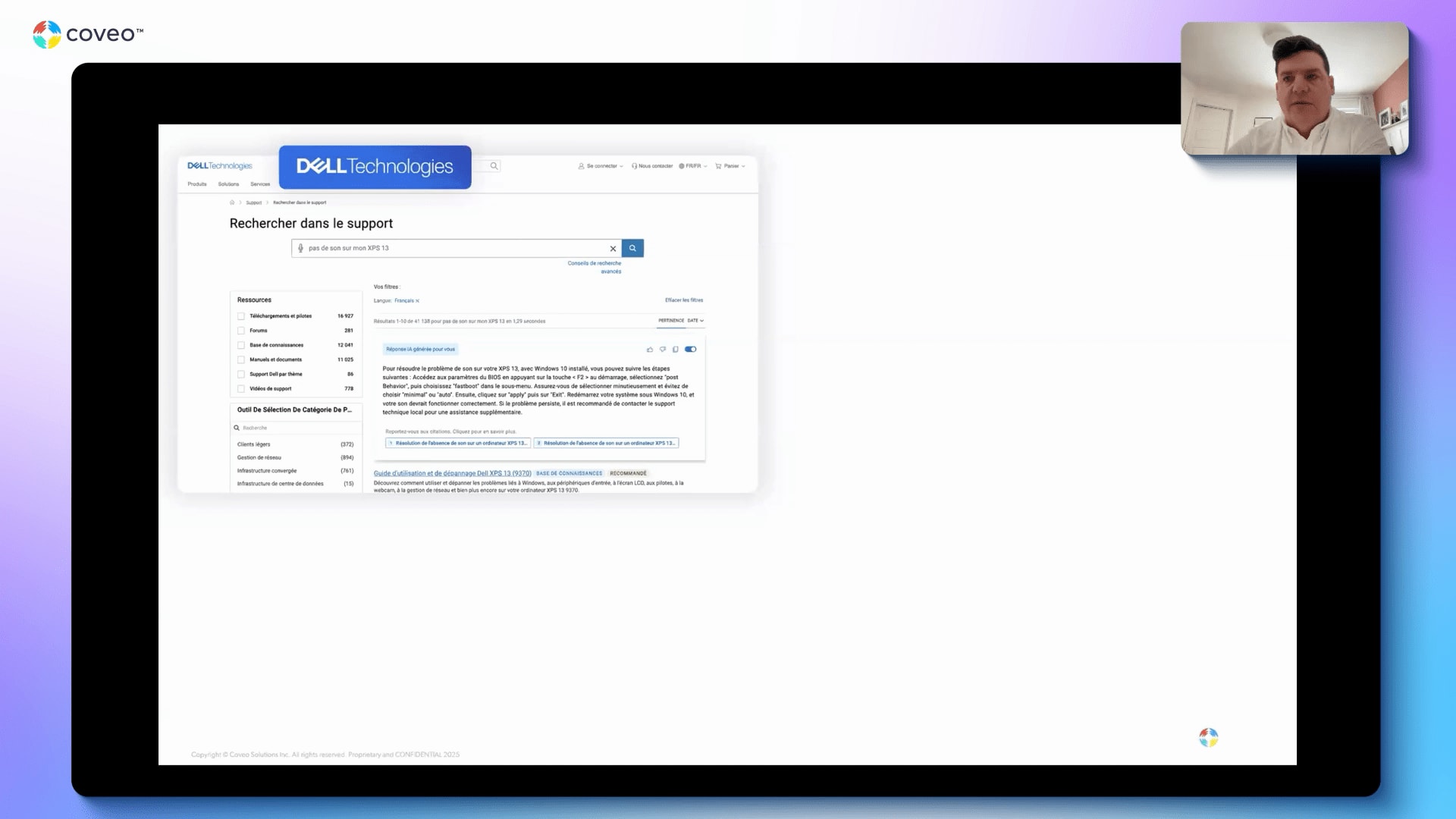
Welcome, everyone. Thank you for joining this webinar, Agentic AI masterclass with AWS, grounding Gen AI on enterprise data with AWS Agentcore and Coveo. My name is Vincent Bernard. I'm a director in r and d here at Coveo. I'm also thrilled to be with Nicolas Bordelot, head of relations at Coveo, and our guest, Brad Bafna, Gen AI ML ISV partner at AWS. I have a few couple housekeeping items just before we get started. First off, everyone is on listen only mode. If you have some questions, please use the question mode directly in Zoom, and we'll get them through at the q and a at the end. We'll be answering all of them at the end of the session. At the conclusion of the webinar, a brief survey will automatically appear upon your screen. We would really appreciate if you take a moment to complete as this feedback help us shape the future of these webinars. Today's webinar is being recorded, so you're gonna receive a presentation as soon as we reach a conclusion of the event. Now let's get started. Brad, up to you. Thanks, Vincent. Hello, everyone. My name is Brad Bafna, and really excited to be here. At AWS, I lead our technology partners for all our AIML services. And on today's agenda, we're gonna talk about, you know, future of AI agents from an AWS perspective, and Nick is gonna talk about, Coveo plus Agentcore best practices. So let's dive in. So, the big question that we get these days are, what are AI agents, and how are they different from, you know, other generative AI applications, etcetera, that we've seen over the past couple of years? So the key thing to remember is, you know, unlike foundation models, which, you know, lack the ability to, you know, solve problems and execute tasks, they're great at generating content, whether it's text or images or videos, but they inherently are not able to, solve problems, that's where AI agents come in. And AI agents are autonomous or sometimes semiautonomous software systems that leverage AI or these large language models to reason, plan, and act in order to accomplish goals on behalf of humans or systems, like, you know, compiling research, paying bills, writing and executing code, or managing enterprise applications. Now these agents can, you know, sense and interact with their environment, like, through APIs, tools, access data stores, and even work alongside other agents. They have the ability to decompose high level objectives into executable steps, and they can also continuously learn and improve over time. So that's really where AI agents, you know, really drive value. In terms of use cases or agentic use cases that, you know, that we see across a number of our key industry verticals, we are seeing these AI agents being deployed to address incredibly, you know, challenging and complex tasks that are that help these organization organizations transform their processes and their workflows. A few examples, you know, like in financial services, we are seeing compelling applications in, you know, underwriting. So traditional manual processes that are often, you know, slow and inconsistent, they're they're now being transformed through these AI agents. So financial institutions are deploying these agents that that make data driven decisions at scale. Sometimes, you know, that are that are doing work on behalf of, you know, humans or automating, you know, existing workflows and, you know, making them more efficient by ensuring, you know, fair and explaining outcomes as well as, you know, maximizing audit efficiency. All of this while leveraging, you know, existing models and frameworks and maintaining the highest levels of, security that's critical for handling, sensitive financial data. You know, another, you know, example that pops out is in the media and, and entertainment space where, you know, content management is super complex. And AI agents are now able to, you know, handle, you know, complex video processing tasks, do metadata tagging at massive scale in order to drive efficiencies. So these agents can automatically, you know, extract technical specs. They can create content summaries and ensure compliance, you know, across, vast content libraries. And these tasks are traditionally require either a significant amount of computing power or a lot of manual effort. So doing all of this while integrating seamlessly, with existing content management systems and maintaining, you know, the strict content security, that's really where these, AI agents shine. Now these examples illustrate, you know, how AI agents can empower organizations to bring, you know, groundbreaking AI solutions to the market faster while addressing, you know, the unique challenges, you know, within their, industry. Now although these, agents, you know, open up, you know, a really exciting set of opportunities and and use cases, getting agents to production is is still hard. In fact, Gartner predicts that, you know, over forty percent of Agentic AI projects, you know, could be canceled by twenty twenty seven. And reasons cited include, you know, growing costs, unclear business value, and, you know, insufficient security. So how do you translate the excitement and potential that you see when you're, you know, doing a proof of concept to, you know, actually making these agents run-in production and deliver meaningful business value? There are a number of steps you need to follow. First, to deploy AI agents, you know, and their tools, organizations need specialized runtime. Unlike typical applications that, you know, follow predictable paths, Agentic AIs or agents are nondeterministic, you know, by nature. These agents can operate, you know, over much longer time horizons, from several hours to, you know, even several days, And they can process multiple modalities, whether it is, you know, text, video, unstructured data, images, etcetera. And they can call different tools and services. So, you know, it needs a specialized runtime that has the ability to handle all of these requirements. Secondly, you know, as the underlying large language models or foundation models are stateless, these agents need memory to retain the context and to learn from past interactions and provide personalized experiences. Third, you also need fine grained identity and access control. This is to ensure that agents can only access the systems and data sources that they should. And you also need to ensure that your AI agents can discover and interact with custom tools and data sources with the appropriate security and governance. Next, we also need to ensure that to execute multistep workflows autonomously, these agents need to have access to a common set of agentic tools that can be leveraged in a consistent fashion. And finally, operating these agents requires, you know, monitoring systems that are specifically designed for autonomous systems. So taking a step back, you know, overall, operating AI agents in production requires a different set of infrastructure, capabilities, and controls as compared to any traditional enterprise application. And these are the clear challenges around, you know, making sure that these agents can, you know, perform, they can scale all within the constructs of security and governance as required by the organization. Now what we see as a key few key patterns emerging from, you know, the customers that we've worked with in order, to drive these Agentic AI applications into production, we can categorize these into four broad patterns. And these patterns, you know, they they coexist. In fact, they reinforce each other, and organizations often adopt, you know, multiple patterns simultaneously and thereby creating a multiplier effect. And success in implementing Agentic AI in production often comes from treating these as complementary capabilities that can mature together. Now, you know, you you have organizations that that make it that are adopting Agentic AI for improving workplace productivity or to improve software development processes or accelerate the software development processes through, you know, automatic code generation. Beyond that, we also see organizations that are automating, you know, business workflows with custom agents. And, you know, ultimately, the holy grail of, you know, Agentic AI is, you know, to transform your business with with Agentic operating system. So we're gonna dive into just a couple of these, you know, as part of this session. One of the key, key key places where organizations are seeing value with Agentic applications is around workplace productivity as this is this has become a most accessible entry point for many organizations. Here, the focus is, you know, primarily on automating your basic workflows across departments like, sales, marketing, HR, finance, and and customer support. You know, you have the ability to use out of the box solutions for these. Workplace productivity applications have matured, you know, fairly, fairly quickly over the last, couple of years. And, you know, Amazon, you know, we ourselves offer Amazon Quick Suite that taps into all of your data sources, all of your enterprise applications, and give you the necessary, you know, tools and, and features in order to drive, drive that productivity of your employees. Now, traditionally, you know, there is a, you know, cost that's associated with, you know, organizational intelligence that is spread across different applications or that reside in different silos. Employees spend a lot of time, you know, gathering data from multiple sources, you know, in preparation for any, any meeting or any, you know, putting together a business use case or a business plan, etcetera. There's a lot of time that's spent in, you know, consolidating all of this information, getting insight into this information, often going through, you know, multiple, you know, spreadsheets and documents in order to really surface the right next action item, etcetera. Also, employees spend a lot of time consulting with other experts to, you know, help analyze this data. All of this can be addressed through Agentic AI applications that, that help improve employee productivity. Another area that, that we are seeing, a lot of organizations, you know, adopt in order to drive, value through Agentic applications is around automated business workflows. Now for customers that have, you know, very specific and differentiated needs, the priority is to, you know, very quickly and easily build custom agents that can span, you know, different models, different frameworks, or even different clouds, all while going from POC to production with confidence. Let's dive into that a little bit. Like, what does it take to build a custom agent or to reimagine, you know, a workflow that uses custom agents. So let's look at the anatomy of a AI agent. A useful AI agent requires, you know, multiple components, you know, working together. As I mentioned earlier, you know, memory for context retention and learning is extremely critical, you know, for these AI agents to be more useful and more relevant. We also need to have, you know, tools to take actions in your systems, whether these are connectors or different integrations that are required in order to, you know, let these agents, access, all of your systems. We need to provide these agents with very specific goals that help provide the right direction or that help define the problem that the agents can then, break it down into simple, actionable steps. All of this has to interact or has to leverage your foundation models or, large language models as the intelligence layer while these models are tapping into your your enterprise specific data for the domain knowledge for more context so it can ground the answers in your in your specific business. For these agents to then, you know, take actions and perform user interaction, all of that has to be done within the purview of, you know, the necessary, you know, observation layer as well as guardrails in order to make sure that these agents are performing as expected. Now builders have to make a number of choices, you know, across models, across tools, across frameworks, etcetera, in order to build an AI agent that aligns with the use case. To make all of this simple and easy and to remove the heavy lifting from this, we have a couple of key services that we offer, and Coveo uses these services as part of their platform in order to, make it more consumable for for its customers. So Amazon Bedrock is a comprehensive, scalable, and a secure platform for building both generative AI applications and AI agents. It provides the broadest choice of leading models, whether it's from Anthropic or Meta or, or any of the even open source or open weights models from OpenAI or or Google are available through Amazon Bedrock. You can customize your Agentic AI application with your data through RAG workflows or fine tuning. You can apply the necessary, you know, safety and responsible AI checks within your workflows. You can optimize either for cost or you can optimize for latency or you can optimize for accuracy depending on your use case. And last but not the least, you can really use Amazon Bedrock to, you know, build and orchestrate agents. And specifically for agents, Amazon offers you know, through Bedrock, we offer Amazon, Bedrock Agentcore. Now what Agentcore really helps you do is, you know, in order to accelerate from, you know, prototype to production, it takes away all of the underlying infrastructure complexity that I just spoke about in terms of what's required for a AI agent to to be to be efficient. Secondly, Agentcore provides all the flexibility and interoperability that you need. We've designed Agentcore in a way that makes it more composable so you can just use the features and capabilities that you need without having to leverage, you know, all of it. And Agentcore is designed to work with, you know, any framework or model, that's that's out there. And last but not the least, Agentcore helps you, you know, deploy these these agentic workflows, you know, with confidence and scale, along with the enterprise grade security and controls that, that Amazon provides. Now the true value lies, you know, in the fact that, you know, Bedrock AgentCore offers infrastructure that is purpose built for dynamic agentic workloads. And it does that along with, you know, all the powerful tools that are essential to provide, you know, controls for real world deployment. Now agent core services, as I mentioned, can either be used together or independently. So, you know, if you just wanna use the agent core runtime or you wanna use, you know, some, some other tool for the observability or identity layer, you can absolutely do that, or you can use, you know, different components of agent core, you know, as appropriate. It offer also works with any kind of framework, including, you know, CrewAI or LLM index, and we also offer agents SDK, as well as any foundation model, in or outside of Bedrock to give you the ultimate flexibility. The bottom line is that Bedrock Agentcore eliminates all the undifferentiated heavy lifting of building specialized agentic infrastructure so you can focus on, you know, building your agents and moving them to production with confidence. Now just the last couple of slides, you know, a few things that we've learned, from working with our customers. We've developed a, you know, a customer tested framework for Agentic AI, and this can help you, you know, both get started quickly with, creating AI agents on Amazon Bedrock when you leverage Coveo as well as to think about, you know, some of the more critical areas that you need to invest as you scale these AI agents over time. So some of the key things, very Amazonian, work backwards from the business problem. Try to define what is the problem that you're addressing, what is the ROI that you plan to deliver, and how are, Agentic AI application or your AI agents gonna be used in order to deliver that, deliver that outcome. Secondly, tap into your data as your differentiator, both for grounding these outcomes in your data in terms of, the the actual state of the business as well as to power their differentiator. Without your data, all of these models or agents are the same as what everyone else outside of your organizations have access to. By integrating these agents or agentic workflows with your data, you're making them more powerful and giving them more context, of your business and your domain. Always think about, you know, trust. How are you gonna create trust within your users? And creating that trust will drive the user adoption, which can otherwise be a big challenge. Fourth, with with the number of different models that are available, you know, demand the best price to performance ratio based on your use case. So it's not necessary to use the latest and greatest or the largest, frontier model that's out there. A lot of use cases can be, delivered, you know, with high levels of accuracy by using, you know, cheaper models or there are more price performance models. Amazon Nova itself, you know, offers a, you know, wide range of models ranging from Nova Micro, Nova Lite that have really low latency that can, you know, generate responses very quickly to our frontier models like your Nova Pro and Nova Omni. And last but not the least, you know, embrace and plan for multi agent environments. You know, having that, you know, as a consideration while you're designing your systems is gonna help it, you know, help you scale, in production much, much faster. Lastly, AWS provides everything, when it comes to Agentic AI creating Agentic AI applications. It provides built prebuilt agents, all the necessary tools, access to all leading models. It handles all the infrastructure automatically underneath, and we also bring the necessary expertise. And all of this is being leveraged by Coveo as part of its, AI platform. And to talk about that platform, I wanna now hand it over to Nick who can take you through the rest of the presentation. Nick? Thank you, Brad. Truly appreciate your, your presence here. That's, really, really great to have you on board. I really also appreciate the perspective that that AWS and and you all have on on on Generative and Agentic. I think it's really close to how how Coveo sees things. I wanted to start by by leveraging what actually, one of your slides that you've presented a couple of weeks ago on a workshop that we did with with customers where you were mentioning that Agentic AI will actually help realize the true potential of LLM's. I truly believe so. I think we are at the stage now where we are seeing real benefits from Generative We are interacting with with Generi, with ChatGPT, with q with with, sorry, with QQ Business, with QuickSuite, and and this this type of a these type of applications. We are able to get more productive, but I think that the real future is about Agentic where those systems are gonna be much more autonomous. And and I really like that slide because I see in in both case, there is a strong dependency on on data. And you also mentioned it across across the presentation. Being able to to get to to give access to those system to your enterprise data is, is extremely important. It's it's actually vital, help you differentiate yourself and also make those those tools really, really useful and really more autonomous in the case of Agentic AI. And that's what I'm gonna be talking about today. So how can you, connect Coveo to to Agentcore, to be able to ground, those LLM's either to generate plain content, like in the use case here for GenAI, or to, to to to use that data to provide a a better informed course of action in the case of Agentic AI. I wanted to start with a few customer example, not to brag, but just to establish a bit of credibility, the fact that we are helping our customers go to production with Generative Our customers are going from POC to production by leveraging our technology, by being able to ground those LMs, and by being able to leverage all the knowledge that we have around those. This is an example from from Dell Technology. Dell is using Coveo to power multiple of their use cases, internal or external use cases. Obviously, what I'm gonna be showing today are mostly external use cases external use cases. Sorry. Dell, if you go to Dell, if you're looking to buy a laptop or buy a server or a peripheral that that they sell, You're gonna be served by Coveo. The platform is gonna be there helping you find the right piece of of an of of tech that you're looking to buy, also helping the vendor, Dell, in this case, optimize revenue by optimizing what content is shown to what to who. And if you have a need for support for those products, they have a huge catalog of products. They have huge pro a huge, complexity in that catalog as well, many variant for the same products and everything. If you're having issues with, let's say, wanna update the BIOS for for something or if you wanna simply understand how some feature work on on on this material, they decided to use Coveo to answer complex question for their users. So if you're going there as a user, I wanna fix that thing on my XPS thirteen laptop. Coveo is gonna be the one looking at all their data and bringing it to to you so that you get the answer to your specific questions. NVIDIA has also also decided to partner with Coveo. NVIDIA has pretty much all the money in the world these days. They could definitely be building that themselves, but they decided to partner with Coveo. So if you're looking to to optimize your GPU deployment or basically use their product one more time, they decided to to use Coveo to generate Answer so that users can get to their their objective faster. Another example this time in the financial industry, Intuit Intuit decided to use leverage Coveo inside of their application. So if you're in the app, if you're having an issue, or if you're just wondering how some functionality work, Intuit decided to integrate Coveo inside of the application to be able to answer their user questions so that they're more efficient. Not an Agentic way, but, that's that's just the that's just the beginning for them. They might they might go Agentic at some point with with Coveo as well. Vanguard, Vanguard, again, in the financial industry, they also use Coveo across multiple use cases. Some of the public use cases they're using Coveo for is their personal investor, portal. So if you're an investor, if you wanna learn about their product, if you wanna learn how these product work, not get financial financial advice, but get get information around their product. If you go on the personal investor website from Vanguard, you're gonna be served answer to your question using Coveo technology. So all that to say that Coveo is able to get POCs of GenAI in production. We are seeing many of our customer also experimenting with Coveo in Agentic framework. I don't have any example to show here, but I'll show you in the next couple of slides how to how to do it and how we are suggesting our customers to do so. So so far, what I've been showing you is the left side of that slide here. Basically, when customers are using the full Coveo stack to build Generative AI interfaces to answer customer questions. So they use our our atomic library or quantic libraries. They use basically our library to build that UI. They use the platform under the under it that is able to access all your enterprise data, and, we we manage the prompt. We manage everything to generate those answers. Many of our customers have custom use cases where they wanna be able to to have more flexibility around the prompt, around the use case, around the UI, around basically how they want to to offer a GenAI to their customers or to their employees. On the side here, we see a couple of framework from from AWS. So BandRock, Agentcore, Q Business, QuickSuite. Coveo is able to be integrated with all those framework to an MCP server that expose the main functionality, the main tool from Coveo to to users looking to build their own application, and that's what we're gonna be covering more in more detail today, more precisely later on in this presentation around the agent core framework. Now let's jump into the beefy part of the presentation. I wanted to cover briefly why LLM needs to be grounded. I think it's important to understand that LLM are not factually accurate by default accurate sorry, by default. They are built with a dataset, and they don't know if what's in that and and we don't know if that's what's in dataset is always true. The way they work is that by statistics, by pattern, they're gonna return a piece of information according to what the users typed in. They don't know if it's if that information is factual, if it's true. And moreover, they don't know if that information is what your brand wanna talk about. If something that's out there on the Internet, many many people talking about a specific topic, might come back out of an LLM. But if you don't ground them, that might come back on your on your own premises premises. Sorry. So by being able to provide a source of truth by grounding the LLM on your own information, you're now having a a much more efficient LLM at providing factual accuracy. Contextual relevance is also important. LLMs don't know by default who they are talking to. Yes. There is a way to to provide a larger context window to an alarm. Yes. There is a way to provide memories and everything. But by default, these LLM don't know who they are talking to. So if you want to be able to provide a personalized and relevant experience to the user in front of them, you need to ground them in relevant information that is that is applicable to the person in front of them. If you wanna be able to provide action history, project detail, basically, what they've been doing recently, that can be done by by grounding the LLM. Traceability and trust. Basically, grounding enables, you to do source attribution. So when you are reading an a LLM answer, if it's just plain text, you kinda you kinda doubt. We all do that. We kinda doubt a little bit what is coming out of that LLM. Should I be trusting it? How do I validate that information? If there's a list of of links that goes along with the text, so you know that that piece of information is coming from a specific source of information, you can also go and validate that information to gain additional trust in the answer. But, basically, if you're grounding in the LLM, if you're grounding in prompt on enterprise or on on specific data, now you're able to do source attribution, and you're able to trace where that information is coming from, and you're also able to establish more trust with the users on the other side. Dynamic knowledge update. Basically, those LMs, as I was saying before, are trained, but they're trained on a fixed set of data that is fixed on time. If you wanna augment that that that LLM based on factual information, based on up to date information, you need to ground them with a with a recent set of facts so that they can be now up to date and answer based on up to date information. That is extremely important in domain where the the facts change quickly, thinking about legal, thinking about health care, thinking about financial services, where the reality has changed really quickly. And if you're providing answer based on information coming from yesterday or even a few hours before, it's not gonna be good enough for your LLM to, to take the good course of action or simply provide accurate answers. The the main reason why we ground LLM is to reduce hallucinations. LLMs are really good, at providing answers to whatever they're they're being asked. That's that's what they're for. If you want to, reduce hallucination, you need to be explicit in the prompt that you wanna answer question or decide on a course of action based on a specific set of information. So by providing grounding information, but also by providing a prompt that is explicitly saying to to to, to leverage only the information used, provided as grounding information to answer a question, you're gonna reduce hallucination this way. And enterprise integration, your enterprise data, even if it's public, has probably not been used to train those LLM or only partially. And you also have lots of private information that was most likely not used to train those those LLM. So if you want your enterprise information to be, used for an LLM, it needs to be in the grounding information. So that's really important for enterprise to grab LLM based on their own enterprise information. Now, a bit about the retriever. So, we know that we need to ground LLM. We need to provide information to the prompt so that it it knows what to leverage to to answer or decide on course of action. What makes a good retriever? There is multiple out there. What are the characteristic that we should be looking at as to what is a good retriever? The depth of knowledge is is extremely important. We are seeing that people are interacting differently, obviously, with a search engine than with an LLM than with a chat chatbot or things like that. In the good old days of of of search engine, people were going, were typing in a query, getting results, and then navigating to that research results. Most likely, they were on their way. They were somewhere else reading the information, consuming, and making their mind around what they were trying to achieve to to the the answer to the question they were they were looking for. Now with LLM, people spend way more time in the tool that already are asking the questions. They ask a first question. They might add a follow-up question, or they might need to refine their question. So they spend a lot more time in the interface trying to trying to solve their issue or trying to resolve the the integration that they had. So if you have a limited scope, if you have a limited set of of knowledge available to to your retriever for your LLM, chances are that sometime you're gonna end up in a dead end where you don't have information to to generate answers. So, yeah, that might start to hallucinate, or it might simply say, I don't have information to answer this question, and people are gonna be needing to go some somewhere else to to complete the to complete their their their what they were trying to do today. So depth of knowledge is is is important, and it's a good drastic characteristic for a retriever to have a good depth of knowledge. Contextually aware, just like LMs need to be contextually aware, the retriever needs also to be contextually aware. Relevance is dependent on who's asking the question. Different user, different background, doing different things might might mean different thing by the same exact keyword. So if a retriever is able to be contextually aware, being able to pro to to to retrieve personalized information, that also makes a difference in in the quality of the retriever. Relevance quality is probably the most important one here. When you are grounding an LLM, you're basically instructing the LLM to use its linguistic capabilities and to leverage information that is provided to him to answer or to to do whatever job he has to do. If you're providing wrong information, he'll provide an answer. He'll do he'll do whatever whatever he he was asked to do, but now this time with the wrong side of information. So the better relevance, quality you have, the better outcome you're gonna get out of that LLM. So relevance is extremely important here. It will make a a huge difference. Execution speed is also important. Retrieval in the RAN pipeline is is the first part happening. We are used to see LLM streaming Answer or streaming their their their their their thinking about what they're gonna be executing as a course of action for agent, But all of that start by a retrieval. If your retrieval takes takes one minute, two minutes, five minutes, that's time to forty eight. The the end user starts to see information and starts can start to consume the information. So the faster your retriever are, obviously, they need to be they need to have a large amount of data. They also need to be relevant. They need to be conceptually aware. All of that mixed with speed makes it extremely important so that users on the other side don't wait too long before they see they start to consume information. This the type of information format supported by the Retriever is also is also important. Some some some Retriever offer only chunks of information, which is a good way to ground an LLM if you're looking to generate answers or if you're trying to do a simple task. But sometimes there's different form of information that are required. Good good old list of results can be useful if you wanna if you wanna, if you wanna get people to navigate to those link and do some exploration. And often and some some other times, the the whole documents, let's say, procedure to rebuild an engine or something like that might be required if the task at end for that LLM is to provide guidance to attack trying to rebuild that user. If you get only chunks of information, you're gonna miss the big picture. So by having various formats of information to be able to do multiple jobs, that's quite important for a good retriever. And then last but not least, concise and precise information. The more precise your retriever are, the most the the cheaper it's gonna be to run your LLM because those those passages of information or the information that is being returned by the LLM are actually constituting forming the the input tokens for your LLM when they're gonna be executing that that prompt at inference time. So the the the smaller the information that you that you that you return is, the better it's gonna be on on the cost for execution, though executing those LM prompts. But, also, the the smaller the information and the more concise and the more precise that information is, the easier it is for the LM on the other side to decipher that information and make sense out of it. So for cost, but also for precision, it's really good to have concise information out of an LLM. Now a bit of a a bit of promotion for Coveo. We we obviously have a retriever available for you that that's that's the retrieval toolset. So we have a a set of retrieval tools that are available for our customers either as APIs or, via an MCP server that is currently available in beta soon to be soon to be GA in a couple of weeks. That that that MCP server and those API offer package retrieval if you wanna get packages of information to ground an LLM based on chunks of information. That's the the classic use case. We can obviously make that available to you. That's actually the the the the the the same tool that we use to build the full interfaces that I've been showing before for that and to it and others. We also offer an answer generation API. If you want to get a full answer from Coveo, maybe for more complex question, we have we have expertise in answering complex question. If you want your your bot or if you want your agent to be to be specialized on something different, but you wanna be able to answer come and yeah. To answer complex question, you can use the answer generation API from Coveo to to provide information to your to your bots or to your agent. And then the last two, one search and document retrieval, as I was saying before, those are different format of information. If you're looking to get a list of links to provide exploration exploration tracks for for your users, or if you're looking to get the whole documents maybe for more complex task or for deep research, We also are able to offer that data via via the MCP and the APIs. This is a simple architecture that we provide to our customers that when they are looking to build a basic agent, this is pretty similar to what Prad was talking about before, leveraging a few of the agent core services. So the center, you have an agent. That agent is connected with an LLM. Obviously, that's that's the core. We we we recommend users to leverage long term and short term memory to be able to get that contextual information effect so that you know that there's a session currently happening with that user. You can know what he's been doing before. And, also, you have a long term memory to remember high level patterns of what people have been doing with you in the past. And we connect to Coveo the the tools that we have just been talking about, the Answer, Passage, Search, and Document tools via the via the gateway from Agent Core. And that agent that gateway is connected via identity to Coveo so that we execute task on the Coveo tools with the identity of the user who's connected to the agent. Basically, if you're if I'm connected to an agent and I'm asking him to do something, it's gonna do it in my behalf. And when it asks for information from the Coveo platform, it's gonna perform those query and that information retrieval on my behalf, limiting to what I have access to versus providing too much information and leaking information. That that's also quite important. Now the the secret sauce the secret sauce to make all of that work perfectly, it's a matter of of a prompt and MTP description. No surprise. In the LLM war and everything is is about, writing descriptions and writing prompts. So you need to have global directive. I won't get into it, but you basically define who you are, what is your main what is your main goal and objective. You define that in a global directive. And then we recommend our customers to go with a few guiding principle, a few core principles. Basically, how to manage grounding, how to manage memory, and also what to do with sources. So grounding, how to behave, when to ground, when to ground, when to when to use the different services. So that's important to to to mention. Memory, you wanna make a clear distinction about what is memory and what is fresh information. LLMs can make sense of it, but you're really better if you're explicit explicit about that. And then what to do when you get source of information, you want to you want them to cite their sources. You want them to include the source of information in their in their answers, so you wanna be explicit about that. We also have some customers who go out far as far as defining some types of questions, some knowledge question, memory question, and defining specific behaviors for for a specific type of question, but let's not go into that right right now. Last part I wanted to talk about is the the second part of the secret sauce, which is basically MCP description. We've been experimenting with a few customers around the around that, and, we realized that it's it's also quite important to, do a definition of the MCP, MCP tools that are offered to your agent. By default, the Coveo description are generic description. So we offer you a passage retrieval API that retrieve passages, but we don't know what's in your index. We don't know specifically what you wanna There's a few naming standard that should be that should be respected. Avoid dots in the name of tools. Go with snake case and maybe maybe use dashes. Tool description should be short and simple, maybe one, two sentences, three if it's a complex tool, stick to verb and type of object, create a case, front load the information, create a case, require an indication. Required indication is secondary. The main job is to create a case, so you want that to be second in the in the in the in the sentence. We have more best practices in the sake of of time. I'll I'll skip those, but there's a couple of best practices around that. And the schema versus description, the whole schema is what the MCP server is offering to the agent when he wants to register tools. A lot of that is is for runtime. And, so what are the procedure? What are how to call your function? What arguments are required? That is extremely important, but that that's for runtime. If you wanna optimize the way, an agent are gonna be using your your tools, you need to make sure that descriptions are really well written and really explicit so that the the prompt and the MTP description make a unique a cohesive total, and the agent is able to make sense of the tools that are made available to him. And that's what I had planned for today. Vince, back to you. Thanks, Nick. Very appreciated. I really love the, the diff not the difference, but the different points of view between the the provider and infrastructure side of AWS and the more tangible use cases Coveo shared. We have a few questions. First one is for Unique. How do you ground the, the answers of these different agents? So we understand that you have access to enterprises database or enterprises knowledge, but how do you make sure that the LLM doesn't go back into the fundamental learnings that he had, when he got trained initially? It's a it's a combination of prompting and also guardrails. One service that is available in in AWS is guardrails. So in guardrails, you can specify, you can specify that you want to to answer only based on the information that has been retrieved. So that's one way to do it. Another way to do it is is in prompting. Basically, when you're prompting your LLM, you can tell them to be explicitly using the information provided below in a specific section. So it's an it's it's a mix of both. Probably probably you probably should be using both actually as a, as as a way to be double sure that you're not, providing false information. Thanks. Another question here. Can Coveo handle unstructured semi structured data like emails? Yeah. Actually, that's that's the that's the sweet spot of Coveo, and that's not exactly email, but unstructured information. We can handle also structured information, but our sweet spot is to extract unstructured information from values from various sources. And then when you're querying for passages, for answer, for whatever whatever format you're looking for, we're gonna be returning the most relevant information. Yes. So, yes, it can handle emails and other formats. Thanks. Question for prod. What LLMs are available in Bedrock Agent core? Is it only Nova models? No. So we have, all all kinds of, foundation models that are available in Bedrock. So we have the Nova models. We have, open source models from from Meta, DeepSeq, etcetera. We have all the models from, Anthropic that are available, and we also have very specific models that are available from partners like, Writer or Stability AI, etcetera. Within Agentcore, if you wanna access OpenAI models or, you know, any other models that are, outside of Bedrock, you have the ability to do that as part of your agentic workflows through Agentcore. So it gives you the flexibility of, you know, having, you know, of of of, you know, deploying it, however you want to within your, use case. Thanks. So, unfortunately, it's all the time we had today. We, if we didn't get to your questions, because I see there are still, some of them, we'll make sure to follow-up with you by email. Brad and Nick, it was a pleasure. Thanks to you both, and have a, good rest of the day team. Bye bye. Thank you. Thank you very much.
Grounding GenAI on Enterprise Data with AWS AgentCore + Coveo
Building chatbots and GenAI experiences for regulated industries like healthcare and financial services requires more than a prompt and an LLM. It demands an architecture that enforces data access control, auditability, and precision—at scale.
In this technical session, we’ll walk through how large corporations design and deploy secure, high-performing chat experiences using AWS AgentCore and Coveo’s Passage Retrieval API (PR-API).
Attendees will learn how to:
- Integrate Coveo Passage Retrieval API as a secure RAG layer for Bedrock that enforces document-level permissions and ensures GenAI responses that are grounded in relevant, verified content.
- Align with compliance requirements (HIPAA, FINRA, GDPR) while maintaining real-time performance and enterprise-grade observability.
We’ll also cover lessons learned from real-world deployments—including how teams across healthcare organizations and global banks are using this architecture to support high-confidence GenAI workflows for patients, advisors, and support agents.










Make every experience relevant with Coveo
