

We’re in a “composable” world. A company can hand-pick and connect a set of components to make the solution that fits their business goals. The search industry has changed over the years — almost everything is in the cloud. You pay for month-to-month subscriptions and have choices. Best-of-breed, with the right value, wins when it comes to the technology you choose to leverage. It doesn’t make sense to build and maintain something when you can get packaged at a lower investment.
In this composable world, technology companies can deliver a lightweight integration approach. This contrasts with the past where you saw deep integrations, native installations, and heavy end-to-end prescriptions of how the solution should function. This was how one solution differentiated from another. Over the years we’ve felt the pain of this model: complex upgrades, dependencies, lagging new releases, and broken features from one release to the next.
A lightweight integration approach is a better solution in most cases. You don’t have to install native connectors, manage upgrades, or miss out on technology innovation and trends. This is why I propose Coveo Atomic and the headless approach as the better search architecture.
This strategy builds upon technology standards and patterns already in place. It gives you freedom to build your own UI and select what stack you prefer. It also delivers a full solution that can be implemented quickly.
What Is Coveo Atomic?
Coveo Atomic is a web component library for assembling responsive, accessible, and future-proof Coveo-powered search interfaces. Atomic components are self-encapsulated, composable, and lightweight.
In a recent speed test using Lighthouse, the Atomic library yielded a performance score of 99 for desktop with 2x improvement in blocking time and time to interactive and a 63% improvement in mobile blocking time. Under the hood, Atomic relies on the Coveo Headless framework to interface with the Coveo Platform™ and handle the search application state. The following diagram shows how Atomic is built on Headless.
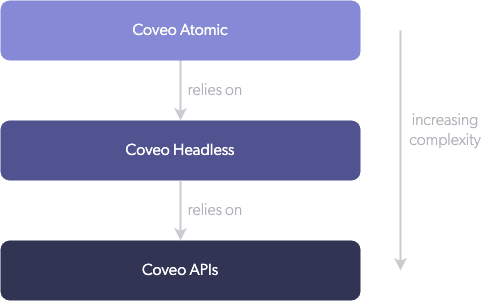
The Coveo Atomic Playbook
In this playbook I’ll cover the high-level steps needed to achieve this fast path to implementation. We will use what we call “pull-type sources”, like Sitemap and Web connector. They sit outside your content systems and read changes in your content, updating the Coveo Index as required. It also means, if any of the said content systems change tomorrow, the pull-type source will sit independently and require little ramp-up on your side when doing system-to-system migration.
I like using the sitemap connector as it can be faster and more powerful than the web connector. And, it doesn’t have to crawl all of the pages to find everything on your site. If you feel more comfortable with another generic connector, that’s ok, too.
Here’s how to get started:
- Create or verify that your website sitemap is available and has all of the content and documents you want to crawl. It’s usually at the root of your site, like this: https://www.coveo.com/sitemap.xml
- Log into your Coveo Cloud Organization, or create a trial/demo instance. The Coveo sales team can help you if needed.
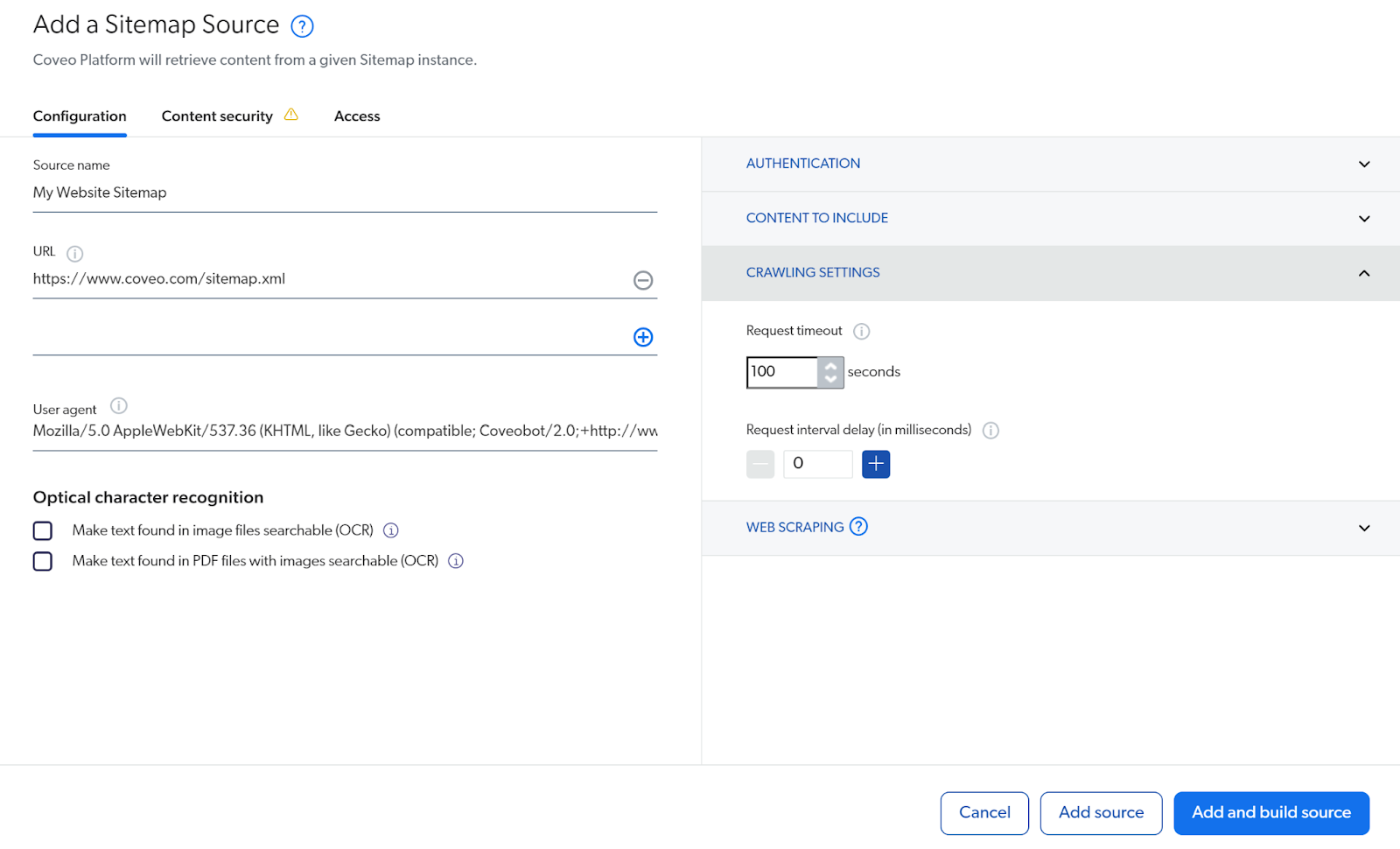
- Create a new source using the sitemap connector and add the URL of your sitemap.xml file. Save and rebuild your source.
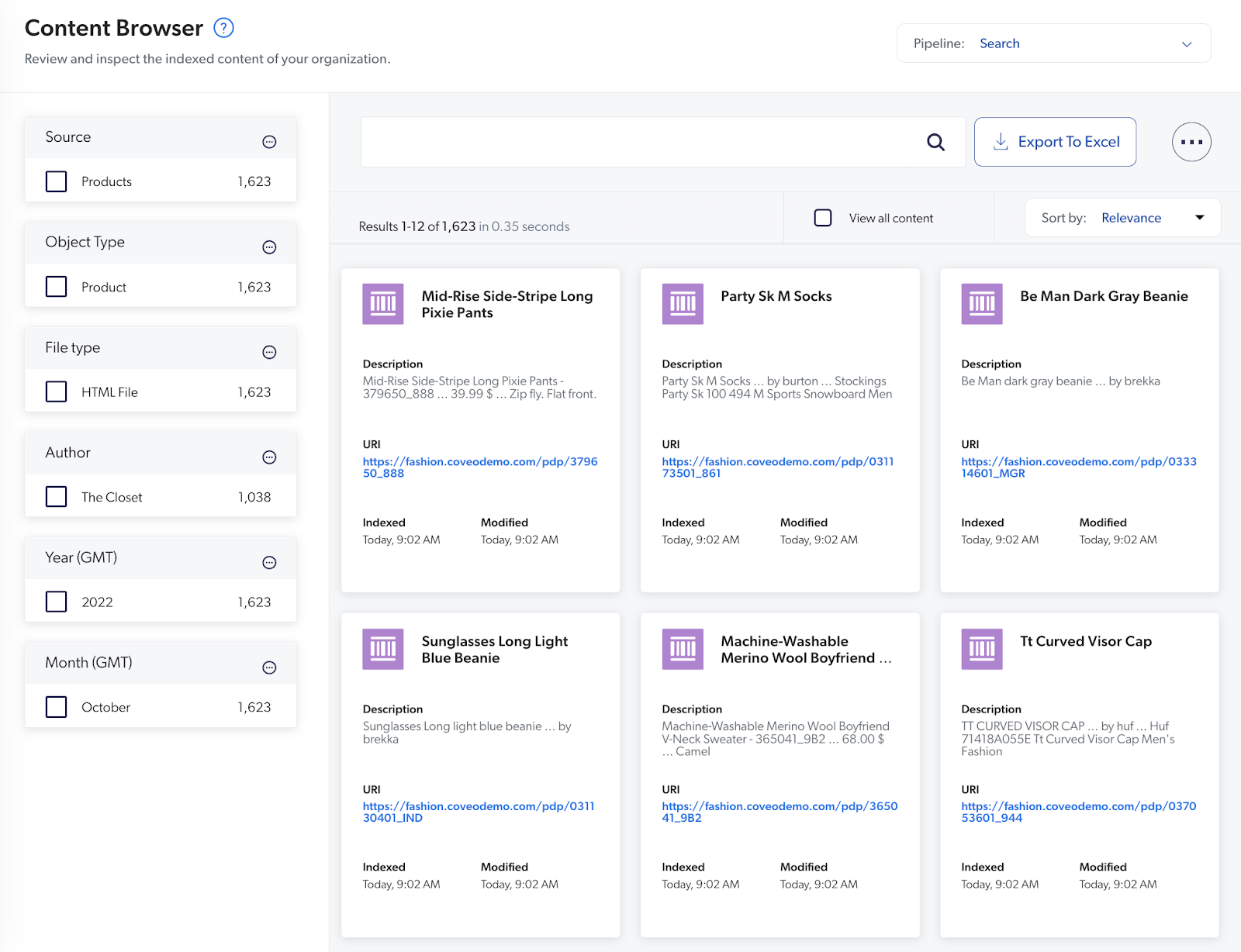
- You will now have all of your content in the Coveo Index. Open Content Browser to see your indexed content.
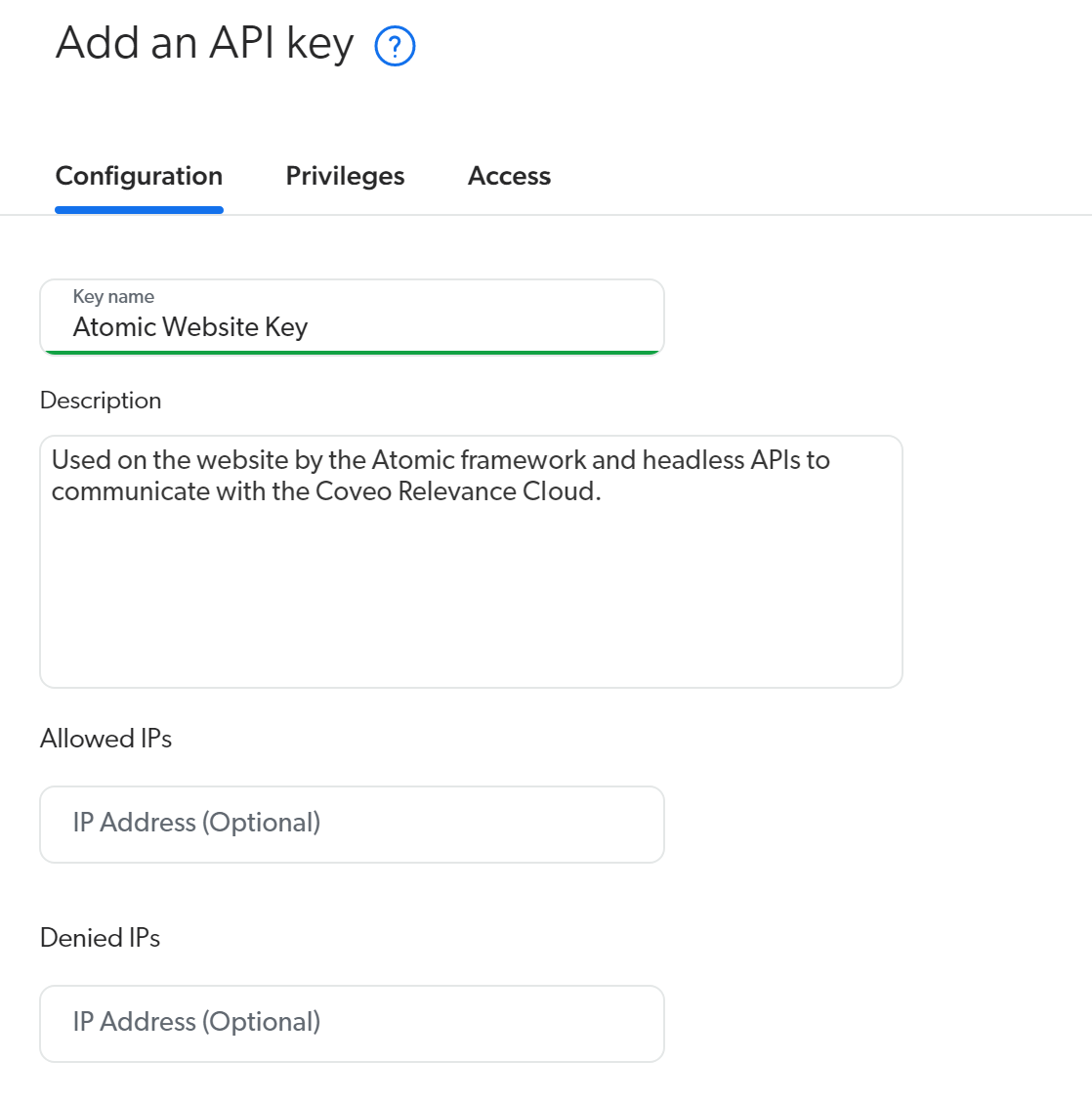
- Create an API key that your website will use to interact with your Coveo instance. We will use this later. In a full implementation you would make sure to secure this key.
- Add a reference to the Coveo Atomic JS and CSS assets on your site or add them through npm if you are using node. Leverage this quick guide if needed.
<script
type="module"
src="https://static.cloud.coveo.com/atomic/v1/atomic.esm.js">
</script>
<link
rel="stylesheet"
href="https://static.cloud.coveo.com/atomic/v1/themes/coveo.css"/> - Use the Atomic Components to Create a Search Interface on a search results page of your website. This adds the Atomic components and initializes it using the API key from step 5.
- Enjoy your new search experience!
In a full implementation, you would have more work to do, but as a high-level guide this playbook is a great start to quickly see results, iterate, and improve. The point is you can quickly get your content into Coveo using a generic connector. You can easily add the search user interface by adding a few references, inserting Atomic markup, and a few lines of JavaScript. The Atomic library is a full interface that comes with all of the search components you would need.
Coveo also has a CLI and supports Angular, React, and Vue. Check out the “where do I start” section in the documentation.
The other parts of an implementation could be:
- Deciding on metadata you want to search or filter on and adding fields to Coveo.
- Mapping the metadata to fields, or leveraging web scraping to gather details.
- Setting up Coveo query pipelines for machine learning, featured results, ranking rules, and other great features to help build outstanding relevancy to your results.
- Implement a Coveo search box to drive users to your search results page.
- Review Coveo analytics reports for insights and tuning.
Full Integration Approach Using Coveo for Sitecore
Coveo does have what I call a full integration approach. One example is Coveo for Sitecore. I find it is a great product — and one I have implemented several times.
Once installed and configured you can author search pages in Sitecore as a content author. If you have Sitecore content authors that are creating search-driven pages and want that authoring ability it makes a lot of sense. It is more prescriptive in how you implement and leverage the Coveo JavaScript UI. It is a heavy integration and requires more effort in an upgrade due to this approach. It comes down to where you want to invest your time.
I believe Atomic is a more modern and future-looking solution. So if you are a Sitecore customer using Coveo for search results, you should consider the lightweight Atomic approach. If you already have Coveo for Sitecore implemented you could migrate to an Atomic approach. This would be a good topic for a future post.
The future of Coveo will be in Atomic. The product team at Coveo is investing their time and resources into this as the modern approach. You can see that Atomic wins in this comparison matrix.
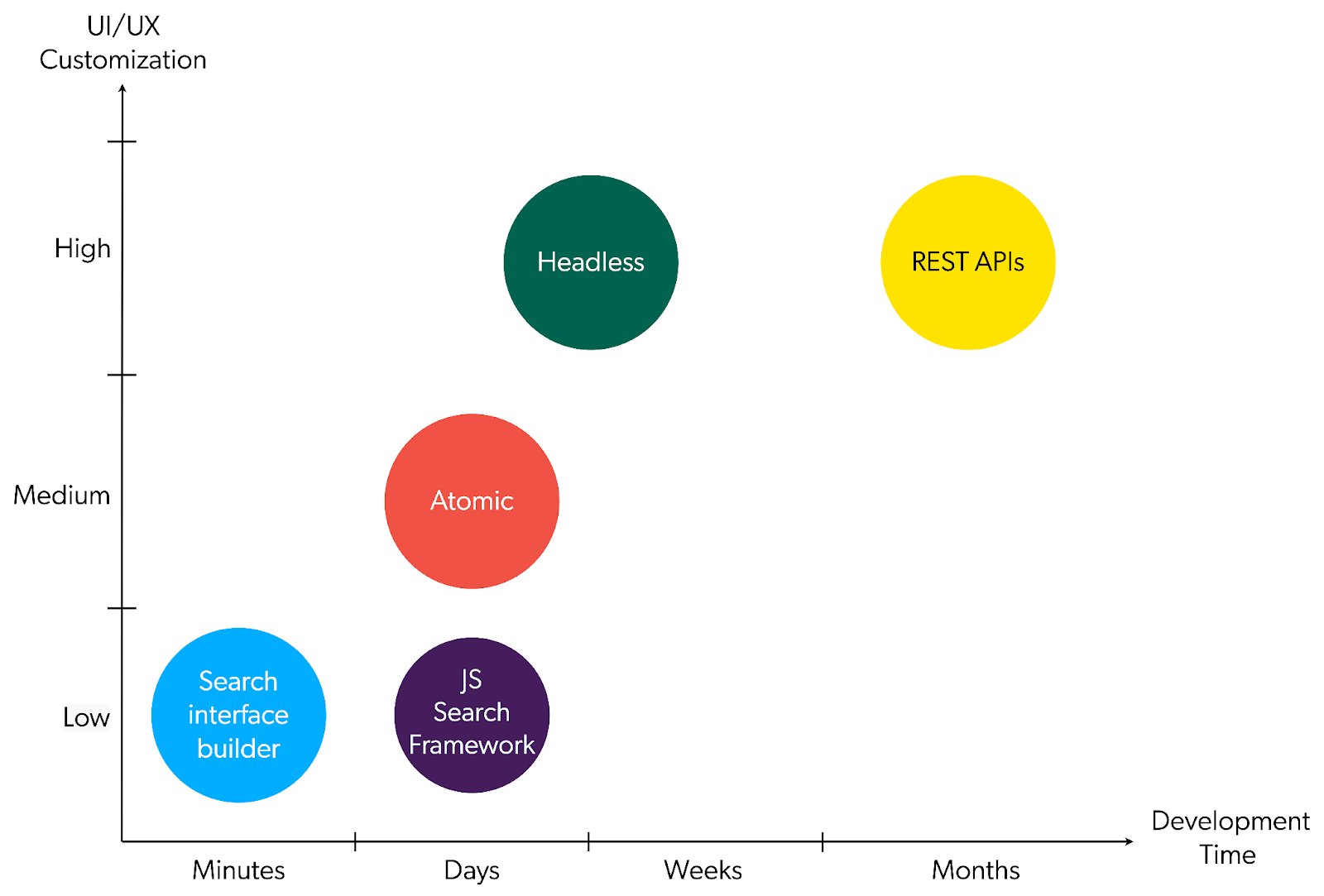
One potential limitation of Atomic compared to a full integration is the lack of tools for creating search pages in your CMS. A full integration includes this functionality, which can be helpful if your authors often work on search-driven pages. From what I’ve seen, most websites prioritize the main site search, which is set up once and then refined over time.
You can build your own Sitecore components that leverage Atomic and give that experience to your authors. Using the Atomic approach you have more control of how it is implemented and the complexity of options you want to expose.
What About Non-Production Environments?
As I prepared this playbook, one issue I struggled with was consideration for the non-production environments such as Development, Test, Staging, and Production.
Clearly, we want search results in those environments and need to follow our development and deployment lifecycle to test what we are building. What if your non-production environments are behind a firewall? Do we need to adjust the strategy since these generic connectors wouldn’t be able to communicate from the cloud? Technically, you could also make exceptions in your firewall rules if your security team approves of it.
The great news is Coveo has a solution: the Coveo On-Premises Crawling Module.
The crawling module is a smart solution to this issue. You install the module on your server (or in your network that can reach the servers) and it acts as a proxy and pushes content to the Coveo cloud. Coveo did a great job on implementing it in a way that it looks like and has the same features as the non-crawling version.
Once it’s set up, you use it like you would any other connector. You will want to review your licensing and make sure you have this option, or contact Coveo to get pricing on adding it in. I have a quick tutorial on my personal blog if you are interested in understanding more about this approach.
Helpful Resources
If you’re new to the Atomic UI, here are a few resources I recommend:
- Coveo Level Up: This is the training platform for Coveo. It is full of amazing and easy-to-consume content.
- Coveo Atomic Tutorial: A specific training module on Atomic.
- Coveo Atomic Documentation
- Coveo Atomic Storybook
- Web Components
Atomic Runs on Any CMS
This Atomic playbook will work on any CMS platform including Adobe AEM, Sitecore, and Optimizely. That is the remarkable thing about Atomic! It can run anywhere that you have control over the HTML and JavaScript. I’ve implemented Atomic recently on a SharePoint project for content and people search. It ended up taking less development time than we planned.
If you try running this playbook, let me know your thoughts!