

To map or not to map metadata. That is the question…
Welcome to the next episode of Whiteboard Wednesdays, our learning series where Coveo experts teach you how to build great search experiences.
Your search interfaces contain facets, display fields, sorting, and are probably using ranking expressions on different kinds of metadata fields. This episode will explain why, when, and how you need to map your fields to accommodate your search requirements. Follow along with Wim Nijmeijer, technical evangelist in the Coveo R&D Department.
Check out the transcript below for the full walkthrough.
Why Do You Need Metadata?
Metadata — for example, Author, Product Name, Price, Category, to name a few — is an important part of your documents in your repositories.
When designing a search experience, metadata plays an important role. Metadata is used as facets, display fields or sorting possibilities. In many cases, metadata used for a search experience is not even visible.
For example, when filtering (@catalog==FirstOne) or boosting (all @sales==true 10 points higher) results, often there’s metadata being used behind the scenes to do the heavy lifting.
Why Do You Need to Map Metadata?
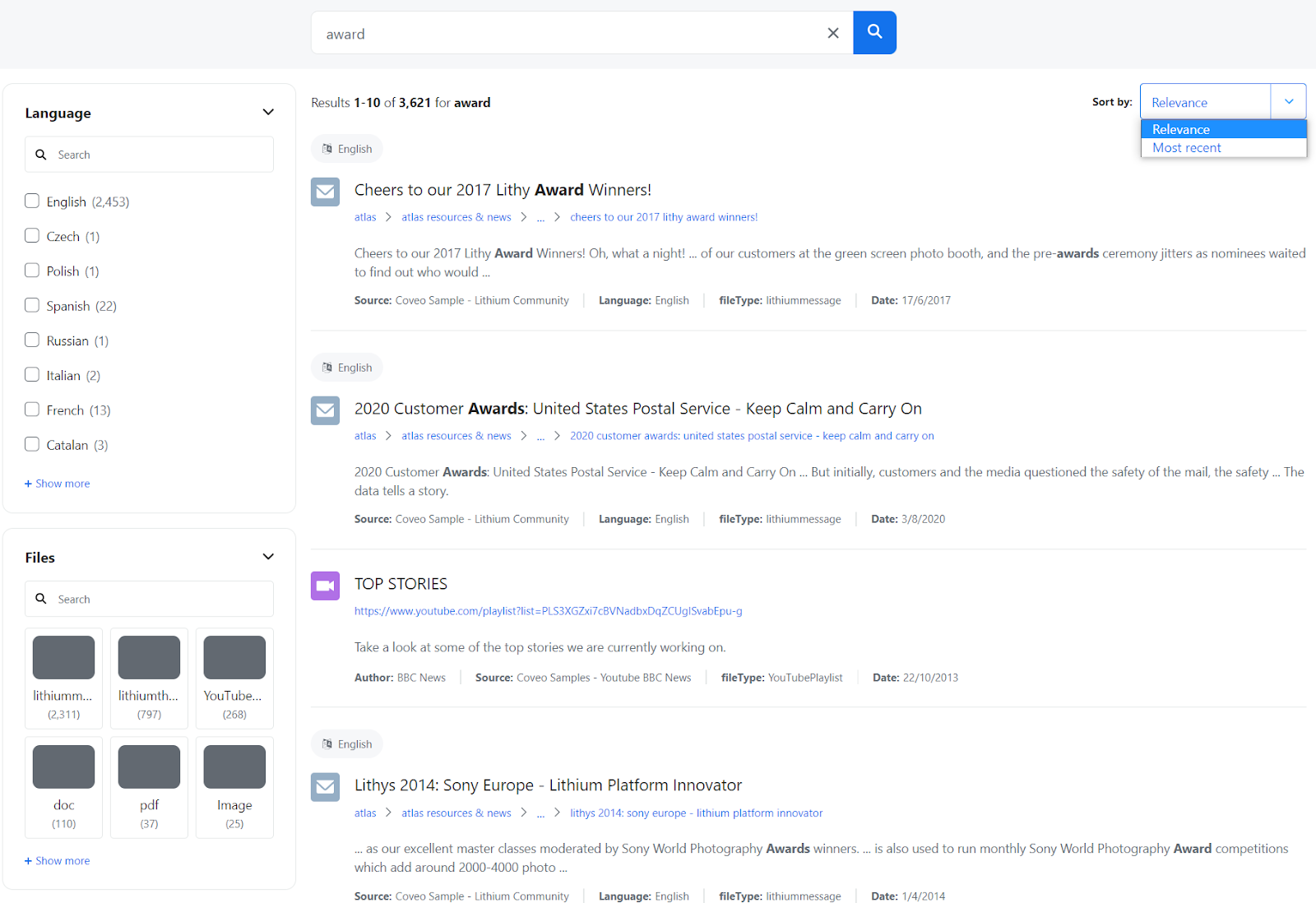
Mapping defines how a document and its associated metadata is stored inside a search index. The search index needs it to aggregate results and to provide detailed information back to the search APIs.
When you start mapping your metadata, you define rules on which data is transferred to which field inside the search index.
In some search engines, mapping can be done automatically. In others, like Coveo, you must manually map your data. By determining which metadata makes sense to map you can create a much better overall experience without forcing the limits of your indexers and search APIs.
Engines like Solr and Elastic offer dynamic, automatic mapping of fields. We don’t offer that because uncontrolled mapping can lead to index explosions or wrongly identified mapping types. Definitely something you do not want to experience!
Pros and Cons of Metadata Mapping
What are the pros and cons of (non-dynamic) mapping like Coveo does?
Pros:
- No index explosion
- The type of metadata field is properly controlled
- Manageable, cacheable
- Performant
- Advanced field queries available, without performance costs
Cons:
- Due to the needing to understand field mapping beforehand, this process takes longer
- Changing field mapping requires re-indexing
How to Determine Which Mappings We Need
The search experience predicts which mappings we need to configure. Some of them are visible, others are not. Let’s dig into the details.
Visible experiences which require mappings:
- Display fields at a result level. For example: Title, Price, Category

- Facet fields at the result list level. For example: Brand, Category, Author
- Sorting fields at the result list level. For example: Author, Price, Distance
Non-visible experiences which require mappings:
- Free text fields, not included in the body of the document. For example: description or notes.
- Ranking fields, adding more importance on certain fields. For example: boost all items where stock < 5.
- Filter fields, filtering based on fields. For example: @in_stock=true.
As you can see in the above, you don’t need a massive amount of fields.
A common scenario we experience often is customers with a huge amount of metadata that must be free text searchable. An easy fix for this problem is adding all contents of those fields to the body of your document.
If that’s not possible, you simply concatenate all the fields into a single one. No need (and also not recommended) to create a huge amount of fields in the index.
How Do We Configure the Mappings?
Once we know the mappings needed for our indexers, we start by adding them to the index.
Adding Fields to the Index
You can activate specific settings for every field. Read our extensive Manage Fields documentation for more insight, but for now we’ll provide a short summary about all the field settings available.
There are different settings for Fields:
- Facet (For filters which contain single field values, see the Example Fields table below.)
- Multi Facet (For filters which contain multiple field values, see the Example Fields table below.)
- Sortable
Let’s see the settings in effect with a few practical examples.
Example Fields
| Type of Field | Type of Content | Displayed in UI |
| Facet | Peter John Marie | Peter John Marie |
| Facet | Outdoors;Equipment Summer;Holiday | Outdoors;Equipment Summer;Holiday * The type is a Facet. The values are not split |
| Multi-Value Facet | Outdoors;Equipment Summer;Holiday | Outdoors Equipment Summer Holiday |
| No Facet selected | Peter John Marie | (Nothing, since the values are not populated as facet) |
Tips and Tricks for Advanced Settings
| Setting | Example | Tip |
| Search Operator | For use with advanced field queries like:@myauthor==Wim | Unless you really don’t want to allow any field queries, leave this on. |
| Displayable in Results | Display this field on a result template | If the field contains sensitive data that you never want to retrieve (but you do want to search on it), then disable this setting and enable the ‘Free Text Search’ one. |
| Free Text Search | Your field contains: Wim You now can enter “Wim” in the search box and the content will be found | Don’t enable this if the content is already in the body of your document. |
| Ranking | This impacts performance. In most cases, the content is already in the body of your document. If this is the case, you don’t need this setting. This setting has nothing to do with Ranking Expressions, which you can always enable. | |
| Stemming | Your field contains: search You want to enable stemming so that: search, searching and searched is also found. | This impacts query performance. In most cases the field is part of the body, which is by default stemmed. |
| Use Cache for Sort | If you sort often on this specific field, enable it for fast sorting. | |
| Use Cache for Computed Fields | You are calculating the average size on the field @size. Or you are using a query function to calculate distance. | When using heavy operations like in the examples. Enable the cache. |
| Use Cache for Nested Queries | When you are using advanced field queries like regex, wildcards (@myfield*=”coveo*”). Or you are using nested queries like: [[@prodid] @type=”XS”] | Enable the setting on the field used for the advanced queries or on the key field you use in your nested queries. |
| Use Cache for Numeric Queries | When you are using range facets ( [0..2, 2-8, 8-15] ) or numeric operations on numeric values. | Enable the setting when you are requesting ranges or if you perform numeric operations. |
When your fields are defined, they can hold your metadata from your repositories.
In the next section, we will see how you can configure a connector to map your metadata to your fields.
Configure the Connectors to Consume your Content
Every connector has their own set of configurations. Refer to our Connector Directory documentation for details on specific connectors.
We’ll discuss a few basic connectors and how to determine metadata for each.
Web or Sitemap Connector
Website pages often have meta properties like: <meta property="mywebcategory" content="Support Article"/>. These can be used directly in your mappings.
Content available as HTML on the page itself can also be indexed using a Web Scraper configuration file.
For example, you would want to index the breadcrumb shown in the following example page:

This could be configured by using a Web Scraper Configuration file like:
"metadata": {
"BreadCrumb": {
"type": "XPATH",
"path": "//div[@id='react_breadcrumbs'] //a[2]/text()"
}
} Generic REST Connector
When you have a REST API, you can use our Generic REST Connector to index the content. In the Generic REST configuration, you can map each JSON property to a metadata field.
Here’s an example configuration:
"Metadata": {
"id": "%[case_id]",
"ownername": "%[case_owner_name]"
} The above will map the field from the JSON response case_id to the id field sent to our converters. If you want to avoid any confusion, name your metadata in your JSON exactly as the metadata from your repository.
Sharepoint Online Connector
In Sharepoint Online, you can create custom list properties. Those properties can be indexed by the Coveo connector. Finding the name of the field is not always obvious. Use the following guideline to find the exact name of your field. Once you have your exact fieldname, you can map it accordingly.
Map the Metadata to Fields
Now that we have the fields created, we know where our repository metadata is located, time to map the data in our source.
We should have a table like this:
| Coveo Source | Original Metadata | Coveo Field |
| SupportWebsite | mywebcategory | my_category |
| SupportWebsite | h2 | author |
| SupportCases | case_id → maps to id (in REST) | my_case_id |
| SupportCases | case_owner_name→ maps to ownername (in REST) | my_case_owner_name |
| KnowledgeLibrary | topics | my_topics |
| KnowledgeLibrary | KB_category | my_category |
| SharepointOnlineSite | Order Number (Sometimes ows_Order_Number) | my_order |
Advanced Field Mapping
When your mapping is ready, now it’s time to add even more enhancements. Fields can be enhanced by using a pipeline extension script.
A few common procedures, in addition to our other samples:
- Reporting all metadata retrieved from the repository. When you want to get all the metadata fields listed in a field called ‘allmetadatavalues’ (For debug purposes). Download.
- SKU decomposition. When you want to enable partial partnumber (SKU) searches, you need to decompose the SKU. For example: 2905LM will be replaced with: 290;2905;2905L;2905LM;905LM;05LM;5LM. Download.
- Reject documents based upon a metadata tag. Download.
- Calculate and assign GeoHash information. Download.
- Unit decomposition. When you want to enable unit conversion searches. For example if someone searches for 100g they should also find 0,1 kg. Download.
- Get URL Parts and store them as facets. Download.
- Fix Sharepoint metadata/Managed metadata fields. Download.
- Assign Color Family. Download.
Using Fields in Queries
Now that your fields are available in the index, you can start using them in your queries.
By default, you can use our Atomic components. Using those components you can quickly build your search experience. The fields from the index now can be mapped to UI components:
Facets:
<atomic-facet field="language" label="Language"></atomic-facet>
Display fields:
<atomic-result-text field="author"></atomic-result-text>
Sorting:
<atomic-sort-expression label="most-recent" expression="date descending"></atomic-sort-expression>
When there is a need to customize queries through code, then you can alter the advanced query using this example.
In your Query Pipeline, you can control the ranking and additional filters to apply to your results. Here you can also define your advanced field queries to support the specific requirements of your search interfaces.
And that’s it! In our next episode, we will look at troubleshooting your queries and mappings.