


The 2021 edition of SIGIR eCom is just past us. As typical for one of the leading venues for Information Retrieval in ecommerce, we had the chance to listen to great keynotes from Amazon, Google, and Adobe. And while last year we contributed with our research, we went above and beyond this year, organizing the Coveo Data Challenge, which featured the release of the richest anonymous dataset ever for ecommerce research.
The Challenge centered around a core principle in our roadmap: that is, the need for the machine learning community to focus on “reasonable scale” use cases. If the majority of research papers tackle datasets with constraints that apply only to Amazon-like shops, there’s very little that the industry as a whole can take home from the innovation of the last few years.
As always, effective A.I. starts with realistic data: datasets representative of a wide range of shops in the mid-and-long tail. While the challenge came to its natural conclusion, our dataset is forever available to researchers from all shops and countries. It is indeed the real legacy of this initiative.
The Ecommerce Data Challenge
The Challenge started in April and lasted two months of intense competition: thanks to our dataset and open source code, teams were able to iterate fast on the tasks at hand. To give you an idea of how close the race was, DeepBlueAI beat NVIDIA Merlin on the NEP board 0.2772 vs 0.2771—a difference in the fourth decimal place!

While leaderboards are fun and certainly important in giving us some sense of objective progress for the task at hand, we stressed the importance of ideas and qualitative evaluation for the whole initiative—and we weren’t disappointed. There were six final papers showcasing a variety of approaches and original analysis of the dataset and its peculiarities.
- “Comparison of Transformer-Based Sequential Product Recommendation Models for the Coveo Data Challenge”, Elisabeth Fischer, Daniel Zoller, and Andreas Hotho. The paper evaluates different transformer architectures for the recommendation task, including modifications of a BERT-like model that can directly integrate categorical metadata of the products.
HIGHLIGHT: The authors modify existing state-of-the-art (SOTA) model architectures to include search, browsing, and content metadata. - “Adversarial Validation to Select Validation Data for Evaluating Performance in E‑commerce Purchase Intent Prediction”, Shotaro Ishihara, Shuhei Goda, and Hidehisa Arai (video). The paper tackles data drifting, which is particularly important for production environments where the distance between the training data and the test data can change abruptly due to independent circumstances.
HIGHLIGHT: To tackle the problem, the authors adopt an adversarial validation methodology, creating a classifier for training and test data. - “A Session-aware DeepWalk Model for Session-based Recommendation”, Kaiyuan Li, Pengfei Wang, and Long Xia. This paper transforms product and page interactions into two types of interaction graphs and leverages graph neural networks to learn product representations, which are combined with search information for the recommendation task.
HIGHLIGHT: To handle the cold-start problem, the authors use a session-URL-product graph to extract contextual information without having seen any product clicks. - “Session-based Recommender System Using an Ensemble of Multiple NN Models with LSTM and Matrix Factorization”, Yoshihiro Sakatani. This work relies on extensive feature engineering and two models to recommend products, targeting both sessions that did and didn’t feature products in the first interactions, using a combination of LSTMs and Matrix Factorization.
HIGHLIGHT: Using ablation studies, the paper shows which pieces of information contribute to the recommendation task the most. - “Utilizing Graph Neural Network to Predict Next Items in Large-sized Session-based Recommendation Industry Data”, Tianqi Wang, Zhongfen Deng, Houwei Chou, Lei Chen, and Wei-Te Chen (video). The paper discusses several methods for in-session recommendation, comparing different methods and showcasing strengths and weaknesses of the various approaches.
HIGHLIGHT: Results show that graph Neural Networks outperform other deep architecture, possibly because items’ dependencies and relationships can be implicitly represented. - “Transformers with multi-modal features and post-fusion context for e-commerce session-based recommendation”, Gabriel Moreira, Sara Rabhi, Ronay Ak, Md Yasin Kabir and Even Oldridge. The paper applies state-of-the-art transformer models to the recommendation task, and achieves great performance through some careful design choices and a final ensemble.
HIGHLIGHT: Aside from the quantitative and modelling considerations, the authors went above and beyond with interesting qualitative analysis on popularity, metadata and intent shifting in shopping sessions (they have their own blog post too!).
Not all teams submitted a paper, but all of them deserve our gratitude: our initiative would not have been so successful without their enthusiasm. Final leaderboards, source code, and docs are archived for posterity in the challenge repository: go check them out!
‘Comparison’ as Recommender Systems
Following tradition, we unveiled one research paper at the conference. The paper, “Are you sure?”: Preliminary Insights from Scaling Product Comparisons to Multiple Shops, is co-authored by Patrick, Jacopo and Christine, and presents the lessons we learned from building comparison tables in a multi-shop scenario, with a mix of behavioral and catalog data, and extensive investigation of feature importance.
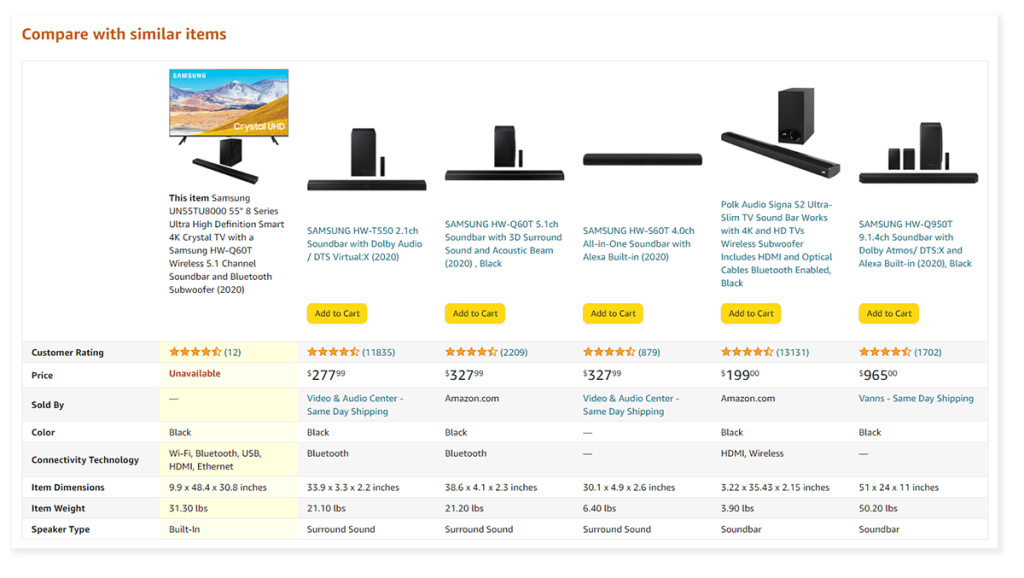

The paper turns out to be full of firsts: it is our first publication leveraging our new MLOps stack, the first one citing Metaflow as our DAG tool, and, finally, the first to include a MTurk-based user study as offline validation for some modelling choices we made. As comparison tables gain more and more shoppers’ trust, we look forward to the next iteration of this recommendation system, including insights from our personalization roadmap and lessons from behavioral economics.
Additional Materials
- Data challenge paper: https://arxiv.org/abs/2104.09423
- Data challenge repository: https://github.com/coveooss/SIGIR-ecom-data-challenge
- Data challenge slides: https://drive.google.com/file/d/1O0BSAhgJFzx1ddeExxAEGnP_836AftNT/view?usp=sharing
Acknowledgment
The organizers wish to thank Luca Bigon for his outstanding support in data collection, and Surya Kallumadi, Massimo Quadrana, Dietmar Jannach, Ajinkya Kale for precious feedback on a previous version of this paper. Finally, special thanks to Richard Tessier and Coveo’s legal team for believing in this data sharing initiative.
— Jacopo & Ciro, on behalf of the Data Challenge committee.