


The WSDM (pronounced “wisdom”) conference was scheduled to be in Tel Aviv this year, but as with everything else, it ended up being turned into yet-another-zoom-week for all participants. Virtual fatigue aside, we were honored to speak at one of the best research venues for search and data mining.
Our talk – “When One Model Must Fit All” – given by our colleague Jacopo Tagliabue, addressed the opportunities and challenges associated with doing machine learning in a multi-tenant setting.
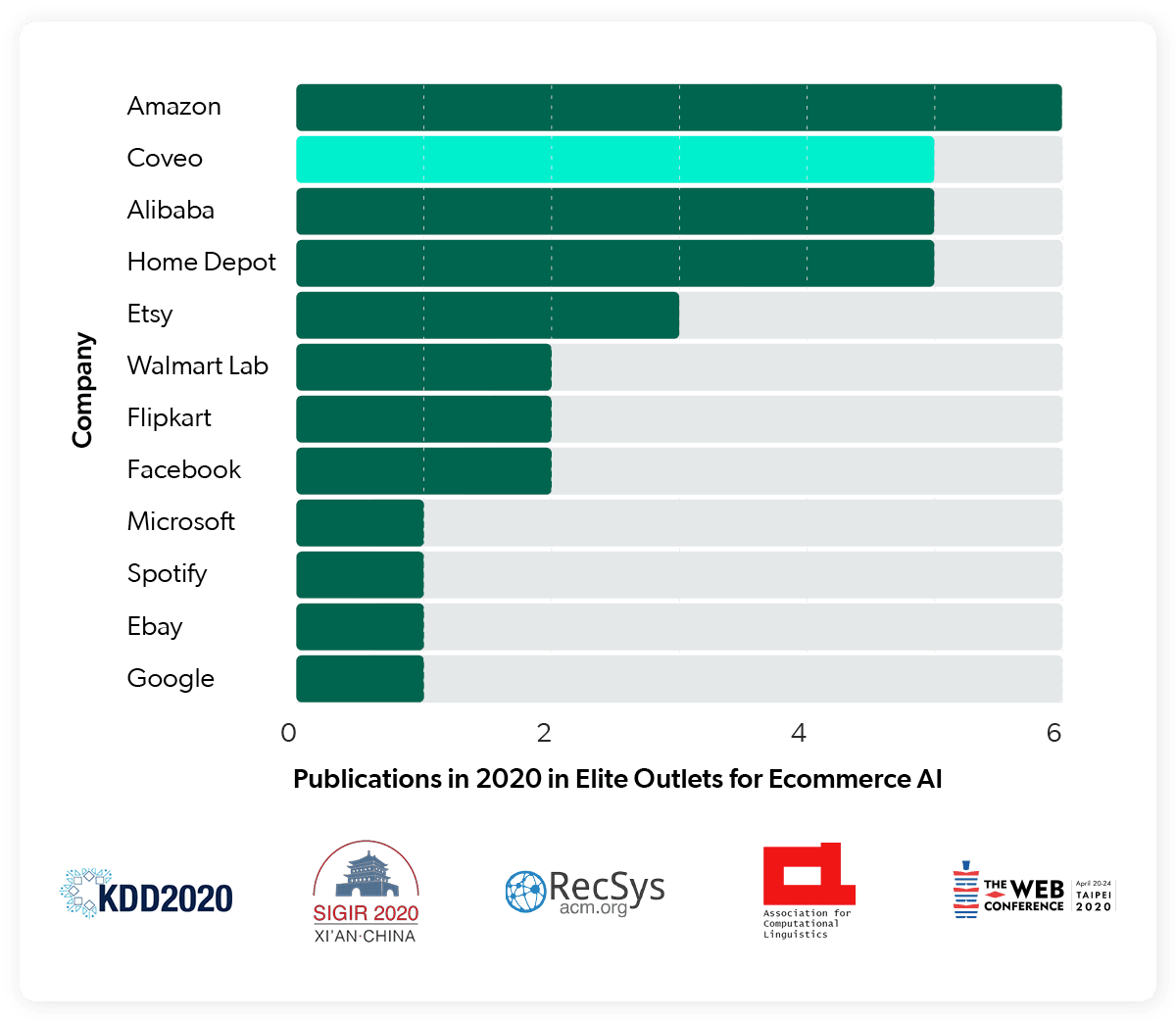
The story behind our talk goes like this: the eCommerce market has reached an unprecedented scale in recent years (in 2020, 3.9 trillion dollars were spent globally in online retail) and driven an explosion of high-quality AI/ML research in Information Retrieval, Recommender Systems, etc., as a result.

While this growth is impressive, investments and gains have been all but evenly distributed in the market, with a few eCommerce tech giants – Amazon, Alibaba, Walmart, Etsy – taking the lion’s share and the majority of other retailers being left behind. Leaving aside the broader societal implications, this imbalance creates two issues:
1) research themes are heavily influenced by tech giants incentives;
2) even when use cases can theoretically be relevant for mid-sized digital shops, computing constraints make findings irrelevant for a large fraction of practitioners in reality.
At Coveo, we try to do cutting-edge AI research, but with a multi-tenant agenda. In a multi-tenant scenario, the goal is not to optimize a model for a given shop that you control (say, Amazon researchers improving the Amazon recommender system). Rather, the goal is to build a robust model that works well across dozens of deployments, with target shops varying wildly in size, catalog quality and shopper behavior. At Coveo, we deploy machine learning models to hundreds of customers, making our multi-tenant research particularly complex.
Our talk aside, premier conferences are always a good time to catch up on the latest trends, do some (virtual) networking with our peers, and attend tutorials on topics we are working on at the moment (or planning to work on in the near future – shhhh). The field is evolving so quickly that learning moments such as this one are precious and indispensable. To reference Socrates, true WSDM is knowing you know nothing.

Our WSDM talk was focused on machine learning in a multi-tenant setting.
As usual, we are happy to present our proudly opinionated and non-exhaustive selection of things we liked, especially in connection with eCommerce use cases. Enjoy!

1: Personalization in Practice: Methods and Applications (Tutorial by bookings.com)
As personalization has become an essential component in every sophisticated eCommerce strategy, bridging the gap between academic research and industry applications is definitely a challenge that must be addressed. This tutorial – given by ML scientists from Bookings.com – was enjoyable and thorough, and it also provided a variety of practical suggestions for how to move forward.
It started with an overview of trends in personalization, revealing the methods that are available for addressing problems related to multi-label classification, causality, and explainable AI. Sequence modeling, which is a fundamental tool for generating recommendations (check out our latest work on the topic!), was also well introduced.
The presenters took us on a tour through different algorithms, from traditional recurrent NNs (deep and wide recommender) to more recent transformer-based models, and discussed how they can be used as solutions for both modeling user behavior and integrating user context.
Another even more intriguing topic in ML presented in this tutorial was causality modeling. It aimed to answer the following question: How can we ensure that the alternative solution we select is the one that improves user experience the most, especially in a case where performing randomized experiments is not feasible?
The presenter discussed a number of solutions for treatment effect estimation, ranging from simple methods, such as transformed outcomes, to more tailored solutions, such as uplift random forests. We share their enthusiasm regarding causality-related topics – last year, we presented our “multiverse” paper at SIGIR, which addressed the problem of determining conversion attribution for search queries when A/B testing is not possible.
We also found some common ground when it came to the last topic as well – contextual bandits. We presented our method for query refinement at the last COLING, and we look forward to digging even deeper into how reinforcement learning can be used to improve online shopping.

2. Session: Networks
Although many SOTA deep learning models – such as BERT and other transformer-based models – have recently revolutionized NLP, machines are still limited in their ability to understand relationships and capture the rich interactions that are omnipresent in the real world.
For this reason, especially when it comes to handling data that incorporates network-like interactions, graphs are still the go-to tools to accurately represent, learn and make inferences. Two papers from the session on networks – BiTe-GCN and DyHINE – caught our attention and may serve to benefit our own use cases.
BiTe-GCN (by JD.com) is a graph convolution network designed to deal with text-rich data. By augmenting the original network with a word sub-network as well as a series of convolution and data-refinement operations, the final model is able to significantly outperform existing node-classification methods.
In the second work, the authors proposed DyHINE: a method to model temporal network structures while efficiently updating node embeddings during graph evolution. Given the importance of the temporal aspect of graph representations in many applications – such as social networks and eCommerce recommendations – we found the contribution extremely intriguing due to its wide range of potential applications. As a target task, the authors focus on the standard link prediction task and make efficient use of “temporal random walks” to produce dynamic node embeddings.

3. Beyond Web Search: How Email Search Is Different and Why It Matters (Keynote by Susan T. Dumais)
Web search is a topic that continues to be well-explored in the ML community. That is why Microsoft’s Susan Dumais brought email search to our attention, as it is clearly under-represented in the research community.
Blindly applying web search strategies, however, won’t play nicely with email particularities. For example, while email search queries are as short as web search queries, their underlying user intents are often composed of far richer metadata – such as the time, recipient, etc. That is why figuring out how to expand and reveal those hidden intents is one of the keys to success for email search engine providers.
The lifetime of emails is also a particularity that needs to be uniquely addressed. On one hand, most emails have a very short life span and recency is definitely a predictor of the level of intent to revisit. On the other hand, a user’s preference to search rather than browse has an inverse relationship with the email’s age. Therefore, email engines must be able to take all of these clues and various temporal aspects into account, as that is the only way to provide delightful user experiences.
One idea Dumais emphasized, and that we also think is incredibly important, is that optimizing for simple relevance/ranking metrics should not be the only goal. At the end of the day, continually seeking to have a deeper and more serious understanding of underlying user needs is what contributes the most to the success of an AI product.

4. Neural Structured Learning: Training Neural Networks with Structured Signals (Tutorial by Google Research)
The team at Tensorflow introduced a new deep learning framework called Neural Structured Learning. This framework uses graph structure as a form of regularization or auxiliary training signal in deep learning.
The reality driving the creation of this framework is that training samples may be correlated in ways that are not directly observable in the training data alone. This tutorial introduced the idea that we might be able to bring such knowledge into deep models by leveraging a graph-like structure defined over training samples, especially when such structure is naturally present in the problem domain.
In the case of eCommerce, co-view and co-purchase relations are obvious cases in which graphs spontaneously occur. And the key takeaway from the tutorial is that we can use the neighbor relations in these graphs to regularize the latent representations in our deep models, so that neighbors will be constrained to have similar representations. The benefits of such regularization include greater model robustness and sample efficiency.
The team also touched upon various points related to scalability and proposed ideas for future research on how structure can be leveraged in deep learning.

5. Some thoughts on Computational Natural Language in the 21st Century (Keynote by Yoav Shoham)
While Prof. Shoham has made significant academic contributions to the field, he has also proven to be highly successful in the business world as a successful serial entrepreneur. A seasoned professional at turning algorithms into products, he shared useful insights on how large language models such as BERT and GPT-3 can be used to create a useful product.
He started by acknowledging what they lack: semantic understanding. For example, when BERT is asked to predict the next word in the phrase “I ate a …”, it gives meaningful food-related predictions but also proposes non-food items like “knife” or “book”. Shoham then moved to suggest injecting semantics into these models by providing other sources of supervision during training – such as word sense and meaningful (as opposed to random) word masking.
Beyond fine-tuning and finding new techniques to improve these models, Shoham acknowledged that building useful products on top of these models requires careful engineering when it comes to outputs and smart product design to mitigate the weaknesses of these models.
As an AI company with significant investments in both theoretical and applied NLP, we saw great value in the lessons shared in this keynote. We believe they will help guide us on our journey to leverage the strength and avoid the pitfalls of large pre-trained models and further improve our products as a result.