


In recent years, AI systems have made significant progress in translating between languages, especially in somewhat simple cases:
![]()
While this may seem to be the result of astonishing engineering, this ability may look somewhat less surprising when you carefully inspect what happens when you use a standard embedding technique to represent words in different languages as points in a space:

Word embeddings for numerals in English and Spanish: notice the obvious similarity.
While the “absolute” position (i.e. the coordinates) of the numerals for the two languages is different, there is a clear similarity between the position of a point in one space and the position of its counterpart in the other space. In fact, they are so similar – or isomorphic – that we can train a machine to “travel” from one space (English) to another (Spanish), and translate “one” to “uno”.
At Coveo, we have published several papers on product representations. And in a previous blog post, we actually shared ideas and code in order to show you how to build a product space for a given shop, such that shoppers’ journeys can be modeled as “paths” in that space:
Now, believe it or not, languages and product embeddings operate in the exact same way when represented in space. If you train product embeddings for Shop X and Shop Y, similar products may have different coordinates, but the overall shape of the space that they occupy will likely be the same:

The spatial conceptualization captured above begs the question, can we teach machines how to translate Ecommerce products? For example, can we translate one product to another and identify product equivalencies between stores (e.g. “Nike Cortez” to “Adidas Gazelle”) just like we would translate one word to another and identify term equivalencies between languages (e.g. “one” to “uno”)?
SPOILER: YES!
If you’re not quite ready for the nerdy details just yet, learn more about how to personalize from the very first interaction – without massive amounts of data – from the perspective of a non-AI scientist:
[NERD NOTE]: This post is based on a research paper presented during SIGIR 2020, which has been authored with our colleagues and friends Luca, Ciro and Federico: all the mistakes in this article are ours and only ours.
“Translation” Is the Key to Multi-Brand Personalization
Before discussing the details of our solution, it is important to understand what the end business goal for our “product translation” is.
Consider Bob, who is shopping for basketball items on Shop A and then leaves to continue his shopping session on Shop B, just minutes later:

Wouldn’t it be incredible if Shop B could use the shopping intent (i.e. basketball) expressed on Shop A to immediately personalize Bob’s experience even if Bob had not been on Shop B before?
Well, good news, it is possible!
If you represent shopping intent within the Shop A product space, “translating” that to Shop B will provide you with the means to implement zero-shot personalization across a variety of interesting use cases and give rise to some powerful capabilities – recommendations obviously, but also type-ahead personalization or dynamic landing pages:

If you think about the current retail landscape, the majority of Fortune 500 retail companies are actually multi-brand groups, meaning that they have two or more brands in the same product segment. Is there a way to train (without manual intervention) machines to understand, say, how to turn a Gap shopping intent into a Banana Republic one?
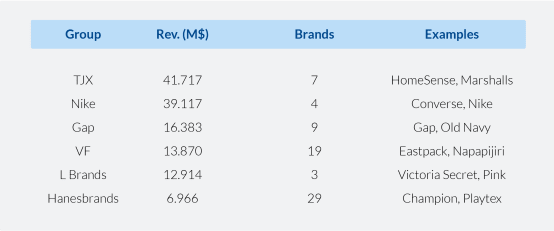
A selection of multi-brand retailers from Fortune 500
In a hyper-competitive market, with few recurrent users and high bounce rates, it is crucial to personalize as early as possible in the shopper journey. The good news is that our methods allow you to personalize the experience for shoppers at their very first interaction, even if they have never been on your site.
To use our Gap-Banana Republic example, if a shopper exhibited an interest in Gap business attire – specifically button downs and blazers – then that knowledge could be used by Banana Republic to suggest similar items within the same category (business attire) of the same type (button downs and blazers) to that shopper as soon as they land on the Banana Republic site.
Innovation, Within Business Constraints
Multi-brand groups have an incredible opportunity to pursue personalization at scale, but doing so does come with challenges.
For example, traditional retailers may have developed different IT tools and services for different brands across time, so relying on translating products (say, finding a Gap product that is similar and can be matched to a Banana Republic product) through catalog data may actually be harder than it seems. Moreover, meta-data may differ not just in quantity and quality, but even in semantics: one brand may speak French, while its counterpart speaks English.
Things get even more complicated when it comes to tracking tools. In the case of the aforementioned Bob, who is going from Shop A to Shop B, there would need to be a common anonymous ID that A and B share in order to re-identify Bob as he moves between shops:

Taking our industry experience and customer needs into account, we aimed to design a multi-brand personalization technology that:
- Works without using textual meta-data from product catalogs;
- Works well in two-regimes: a “cold start” regime, in which no tracking technology is assumed, and a “steady-state” regime, in which our pixel is installed and can be used directly;
- Produces a versatile outcome – i.e. a dense vector representing “shopping intent”, which can then be used to power multiple use cases at the same time (recs, type-ahead, search etc.)
The Dirty Details
We split our explanation in two. We’ll start with “unsupervised” alignment in the “cold start” regime, and move to “supervised” alignment in a “steady-state” regime afterwards.
Unsupervised alignment
Our first method does not assume the existence of any data in the form of cross-shop sessions. The only thing we have as input are (1) the product spaces of two sports apparel brands, Shop A and Shop B, which are both part of retail group I-Love-Sport Inc.; (2) the images of the products in Shop A and Shop B.
Consider again the two stylized spaces in the figure below: if we could map the snowboard on the left to the one on the right, and do the same with the soccer ball, we could then use the coordinates of these pairs to learn how to align the two spaces! If only…

This is where image features come into play. If we use deep neural networks to extract image features, we can generate pairs of similar-looking products in A and B without any behavioral data. Once we have pairs, it is easy to learn an alignment function that allows us to translate A-products into B-products.
Supervised alignment
After Shop A and Shop B go live with Coveo, our fine-grained data tracking will start collecting anonymous data about shoppers spontaneously going from A to B, like Bob in our example. As cross-shop data piles up, we can revisit our alignment methods and treat it exactly like a supervised translation problem. We do so by training a deep learning model to directly translate A-products into B-products – in the same way that the model would learn, from thousands of French-English examples, that “chef d’equipe” and “leader” are synonyms.
Results
We tested how effective personalization across brands is with real data from partnering shops. The table below compares our two methods (the image mapping method IM and the supervised translation method TM) on a product recommendation task against industry heuristic (PM) – that is, when Bob lands on Shop B after Shop A, Shop B is going to display the most popular products, without any attempt to employ a cross-shop inference.

IM yields a ~500% gain in performance relative to PM, while TM yields an astounding 1530% increase relative to the industry baseline, showing just how significant the adoption of a more sophisticated and unified cross-brand personalization strategy can be.
To get an idea of what this actually looks like, we took advantage of the awesome Parallax visualization tool. We did so in order to produce a 2-dimensional projection of selected products with the aligned embeddings from Shop A (blue circle) and Shop B (red circle), mapping the two axes to two sport activities: soccer and skiing:

As expected, skiing-related products from both shops are way closer to the ski axis, i.e. larger cosine similarity with respect to the average ski category; and vice versa. Also, a product that cannot be classified as specifically being skiing or soccer-related (e.g. the hoodie at the bottom-left) is found to be far away from both axes.
That being said, once again imagine yourself as a traveller in this multi-shop product space. If you have ski-based interests, you would find yourself hanging around in the bottom-right corner.
Given that (1) your interests determine your location on the product map and (2) the product map is independent of any particular shop in the multi-brand group, the machine can use your location to understand that you are interested in skiing-related products no matter which shop you find yourself on while looking for what you need. While you may move between different shops, your location on the product map remains fixed, which means your interests are always known wherever you go.
The more accurate and extensible this “product GPS” is, the better multi-shop personalization will be. Our findings suggest that even without sophisticated usage analytics, our personalization strategy is way more effective than giving up on the map altogether, which is what the industry is doing when falling back on popularity-based heuristics.
See You, Space Cowboys
Don’t forget to check out our paper for all the scientific details, more evaluations and additional discussions on privacy, data quality and training embeddings at scale. We also plan on releasing an anonymous subset of the dataset used in our research in order to foster a discussion in the AI community about this very important use case.
As usual, follow us on LinkedIn and Twitter to stay up-to-date on all the cool stuff being developed in our lab.