

I’ve had some version of the same conversation probably a dozen times in the past few months. A team has built something with agentic AI. The demo was solid. Leadership is bought in. They ship — even at limited scale — and the accuracy isn’t there. Responses go sideways. Users stop trusting it.
The first instinct is almost always the same: let’s fix the prompt.
I get it. Prompts are the most accessible lever. Tweaking them feels like progress. But in most of the cases I’ve seen, the prompt isn’t the problem. What’s broken is underneath it.
The “It Worked in The Demo” Problem
2025 was a big year for agentic AI ambition. Lots of investment, lots of pilots, lots of impressive demos. What we’re starting to see now is what happens after the demo — and it’s messier than the hype suggested.
The pattern I keep seeing: teams get through the POC, survive the organizational and political hurdles (which, frankly, are their own obstacle course), and finally launch something live. Then the real-world complexity hits. Accuracy that looked great in the lab degrades under actual query volume. Latency suffers. Pilots that worked at small scale can’t hold up at larger scale, or the cost to run them makes the ROI math fall apart.
This isn’t a model problem. It’s a foundation problem.
A demo is a controlled environment. You know what questions will be asked. You’ve indexed the right content. The retrieval path is clean. Production is none of those things. Real users ask complex questions you didn’t anticipate. They’re messy, they’re varied, they span the full breadth of your knowledge base. And the retrieval system has to perform across all of it.
What Prompts Actually Control (And What They Don’t)
Here’s the thing that gets lost when teams are in fix-it mode: prompts control how a model responds. They don’t control what the model knows.
LLMs don’t know your enterprise. They don’t know your products, your policies, your customers’ history, or your internal permission structures. At runtime, they only know what gets retrieved and surfaced to them. If that retrieval is weak, the model has nothing reliable to reason over. You can write the most elegant system prompt in the world and it won’t matter.
You can’t prompt your way into accuracy or relevance. And you absolutely can’t prompt around permissions.
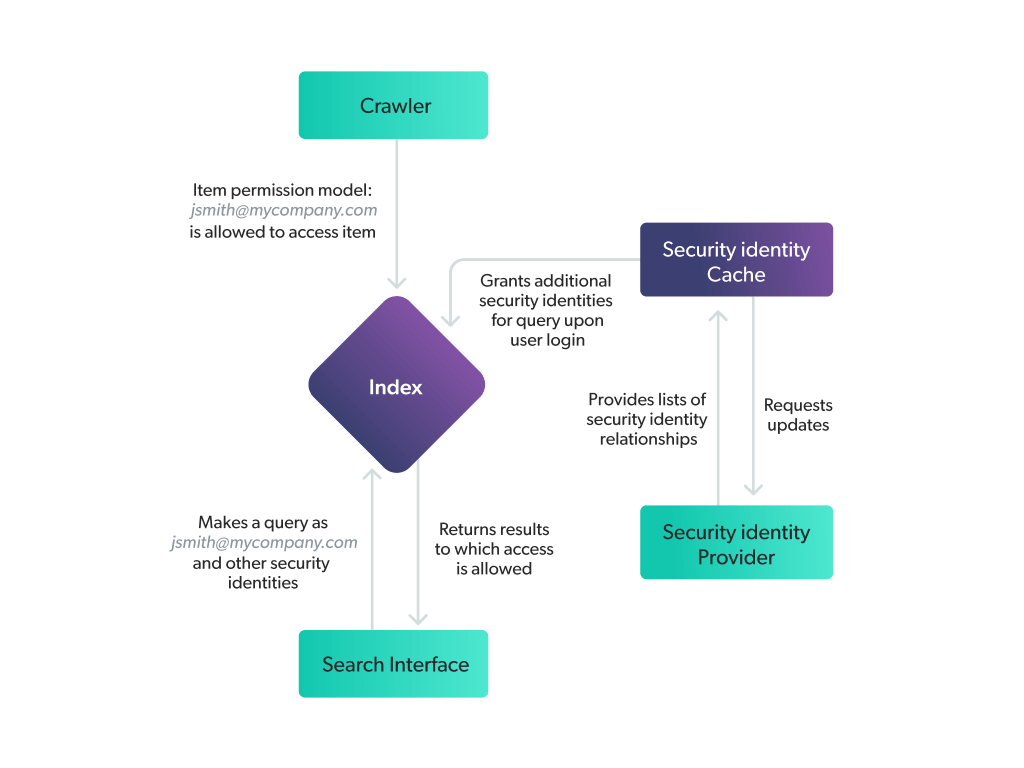
That last one is worth sitting with. Access controls aren’t a language problem. Either your retrieval layer is enforcing them — ensuring the right content goes to the right user in the right context — or it isn’t. No instruction in a prompt substitutes for that.
Fine-tuning is worth mentioning here too. Yes, you can train a model on your specific domain, and there are real benefits to that. But fine-tuning is a mature, resource-intensive step. I’ve seen teams go there before they’ve nailed the retrieval basics, and it’s expensive in every sense. If the foundation isn’t solid, fine-tuning papers over the same underlying problems at higher cost.
What “Bad Foundation” Actually Means
When I talk about a bad foundation, I don’t mean one specific thing. It’s usually a combination:
Enterprise knowledge is a mess. It’s scattered across PDFs, wikis, ticketing systems, HR portals, SharePoint folders that haven’t been touched in years. It’s inconsistent, duplicated, dynamic. Grounding an agent in that reality is real engineering work. There’s no shortcut.
Relevant reading: How The Silo Problem Is Killing Your Customer Service Experience
Existing retrieval was built for humans, not agents. Most enterprise search was optimized for a person typing a short query and waiting for a list of links. Agents are different. They issue longer, more structured queries, they retrieve in bursts, they need rich context to reason across — not a URL to click. A retrieval layer that’s great for human search often falls apart under agentic load.
Observability is an afterthought. This one comes up constantly. Teams evaluate on output quality — does the final answer look right? — without looking at retrieval quality. Are the right documents being surfaced? Is the ranking correct? Is latency holding under real volume? One of the more striking things I’ve seen recently: a customer doing what they called an LLM evaluation, but what was really just assessing the quality of the LLM’s generated answers and citations. Their evals didn’t touch the retrieval layer at all. That’s not an evaluation — it’s a guess.

Architecture chaos. I’ve spoken with organizations running 70+ active agentic or chatbot projects simultaneously. Each with its own retrieval approach, its own knowledge sources, its own quality bar. When retrieval gets reinvented project by project instead of built as shared infrastructure, every gap and every mistake gets reinvented with it. There’s no compounding. There’s just compounding cost.
Relevant reading: AI Agent Experiments: How to Stop Spreading AI Resources Like Peanut Butter
The Mental Model That Changes Everything
Most teams think of AI as the smart layer sitting on top of their data. The model is intelligent; the data is just input. That framing leads you to the wrong fixes.
Flip it: your retrieval layer is what makes the model smart or dumb. The LLM is a reasoning engine. Retrieval determines what it gets to reason about. A powerful reasoning engine fed incomplete, stale, or incorrectly scoped context will produce confident-sounding wrong answers, consistently.

Think about onboarding a new hire. You can hire the most capable person in the world. If on day one you hand them a pile of unlabeled documents — some outdated, some irrelevant, some they shouldn’t have access to — and ask them to handle customer escalations, what do you expect? Now give that same person a well-organized briefing system with current, accurate, role-appropriate context at the right moment. Same person. Completely different results.
That’s what retrieval does for an agent. Invest there first.
Why Agentic Systems Make All of This Harder
Everything above gets significantly more consequential in agentic systems. I think this catches teams off guard.
In a single-turn conversational system, a retrieval miss produces a bad answer. That’s bad. But it’s contained. In a multi-step agentic system — where the agent retrieves, reasons, acts, retrieves again, and builds on its own outputs — a miss in step one can cascade into a completely wrong outcome by step four. Errors compound in ways that are hard to trace and hard to explain to the person on the receiving end.
This is also why evaluation is so much harder to get right in agentic contexts. You can’t just look at the final output and call it good. You have to understand what happened at every retrieval step that led there.

What to Actually Do About It
If your agentic deployment is underperforming, or you’re designing one and want to avoid the most common failure modes, here’s what I’d tell you:
When accuracy breaks, look at retrieval first. Before you change the prompt or switch models, ask whether the context being surfaced to the model is correct, complete, and current. That’s usually where the problem is.
Build retrieval as shared infrastructure. Not project by project. A unified, permission-aware retrieval layer that serves multiple use cases — customer self-service, agent assist, internal knowledge — from the same foundation is how you stop reinventing the same gaps and start compounding on what works.
Push your POC into real conditions early. The longer you wait, the harder it is to course-correct. Test with real query diversity, real data complexity, real user behavior — before organizational momentum carries a flawed foundation into full deployment.
Evaluate the retrieval layer, not just the output. Retrieval quality, ranking accuracy, permission enforcement, latency under load — if you can’t answer those questions, you don’t have visibility into what’s actually driving your results. Human SME testing is valuable. Automated evaluation frameworks that cover the full retrieval-to-answer chain are essential.
Relevant reading: How Coveo’s Knowledge Hub Demystifies Generative AI Outputs
The Sequence Matters
Agentic AI does deliver real value. I’ve seen it work. The teams that get there aren’t the ones with the most sophisticated prompts. They’re the ones who treated knowledge infrastructure as a first-class investment, built the retrieval foundation before the agent, and evaluated relentlessly once they deployed.
Get the foundation right, then get the agent right, then scale. Inverting that sequence is how you end up with impressive demos and frustrated users.
The unglamorous truth is that the best agentic AI experiences — the ones that actually change how employees work or how customers self-serve — are built on a retrieval layer that reliably surfaces the right information, to the right person, with the right permissions, at the right time. That’s not where the demos happen. But it’s where the results do.